Inspiration
Two peer-reviewed papers from Bajpai & Chandrasekharan (UMich) put hard numbers on a problem moderators have lived with for years:
- 84% of moderators "sometimes, often, or almost always" leave the modqueue to seek additional context while reviewing reports — checking user history, scrolling parent threads, scanning prior mod logs (In the Queue, CHI 2026).
- 74.5% of moderators report experiencing a collision — two mods unknowingly acting on the same item at the same time (Towards a Better Modqueue, arxiv 2409.16840).
- The modqueue UI has not been redesigned since 2008.
Every time a mod leaves the queue to gather context, they lose seconds. Across a busy sub, that's hours per week of unpaid volunteer time. Huddle brings the context to the queue.
What it does
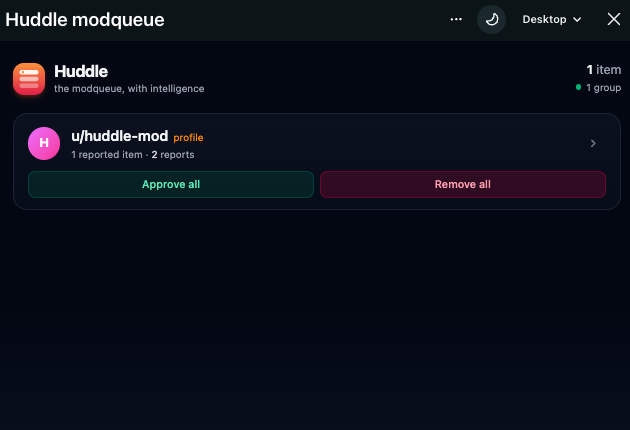
Huddle installs as a custom post in any subreddit you moderate. Open it and you see a smarter, team-aware version of the modqueue:
- Automatic grouping — reports cluster by author. Multiple reports against one user collapse into one row with bulk Approve all / Remove all actions.
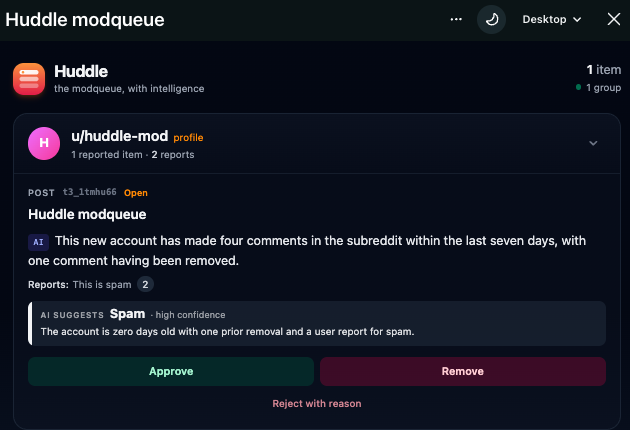
- Factual AI summaries — every item shows a one-sentence summary like "This 259-day-old account has made 2 comments in this subreddit, both within the last 7 days." The LLM never sees the reported content — only a structured fact dict (account age, posts/comments in sub, last 7 days, prior removals). Summaries are cached forever per item.
Why an AI that can't see content? Every other AI mod tool risks hallucinating about your community's content. Huddle's LLM only sees a 5-field fact dict — it cannot make claims it can't justify. Mods see the exact same dict next to the AI's sentence in the Context Peek drawer, so every summary is auditable.
- AI-suggested mod action — a color-coded chip above each item recommends Approve / Remove / Spam with a confidence level and a single factual sentence citing only the dict. When Gemini's free-tier rate-limits (429), a deterministic heuristic over the same facts takes over so the chip stays useful.
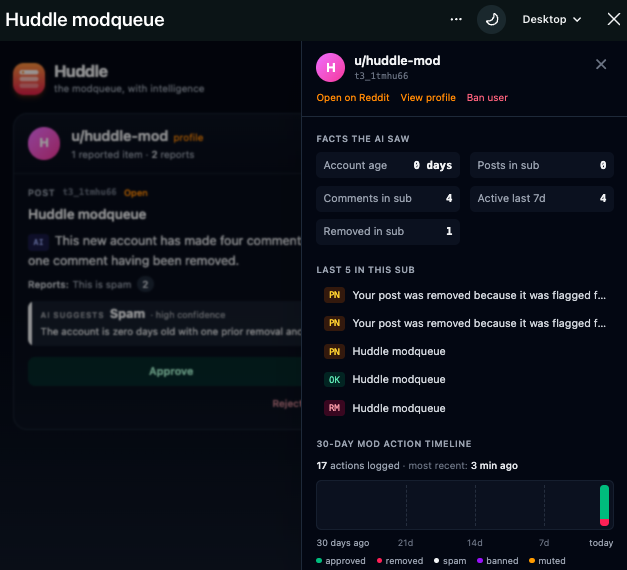
- Context Peek drawer — click any item, a right-side drawer slides in showing (1) the exact facts the AI received as a small table, (2) the user's last 5 post/comment titles in this sub with two-letter status codes (
ok/rm/pn/sp), and (3) a 30-day mod-action stacked histogram by day and action type. From the drawer header a mod can Open on Reddit, View profile, or Ban user (click-twice to confirm). Banning auto-removes every queued item the user authored in one sweep. - Bulk + inline + reject-with-reason actions — Approve / Remove individual items, Approve all / Remove all at the group level, plus Reject with reason: an inline panel where the mod types a removal reason (or clicks "Suggest with AI" to have Gemini draft a friendly, factual, second-person reason). On confirm Huddle removes the item and posts the reason as a distinguished, stickied reply — same UX Reddit's native removal-reason flow uses.
How we built it
- Devvit Web (
@devvit/web/server) — Hono HTTP server hosting five trigger webhooks (PostReport, CommentReport, ModAction, PostSubmit, CommentSubmit) plus the queue/summary/drawer/action APIs. - Redis for the entire data plane — ZSETs for group sets and per-user history (recent titles capped at 20, 30-day action timeline), HASH for the user-facts cache (24h TTL), STRING for cached AI summaries (forever). Devvit Redis has no plain SET ops, so ZSETs with timestamp scores throughout.
- React 19 + Tailwind 4 + Vite for the WebView — the queue polls
/api/initevery 5 seconds; each item lazy-fetches its AI summary; the drawer composes over data already in Redis (no extra LLM call when the drawer opens). - Google Gemini Flash (
gemini-flash-latest) via Google AI Studio's free tier — 1,500 requests/day, no card. The system prompt locks the model into one neutral sentence ≤25 words. Thinking mode disabled so we get a clean answer inparts[0]. Every failure path (no key, network error, 429, safety block, response under 10 chars) silently falls back to a templated raw-facts sentence over the same fact dict. - TypeScript end-to-end with branded
t1_/t3_/t2_thing-id types narrowed via runtime predicates rather than casts.
A reverse-lookup huddle:item-groups:{itemId} ZSET lets mod-action cleanup remove an actioned item from every group it belongs to in a single pass.
Challenges we ran into
- The Devvit ecosystem migrated from Blocks (
@devvit/public-api) to Web (@devvit/web) between the spec and the build. Every import pattern in the original spec was obsolete. We translated the architecture in place: triggers become HTTP routes, settings move fromDevvit.addSettingstodevvit.jsonsettings.global, custom posts host React WebViews viasplash.html/game.htmlentrypoints. - Devvit Redis has no plain SET operations — no
sAdd/sRem/sMembers. We used ZSETs throughout, with timestamps as scores so we get free recency ordering on every read. - Gemini 2.5's thinking mode broke our parser. The model's response prepends a "thought" part with a one-character placeholder (
*) before the real answer. We cached that single*as the summary on first call. Fix:thinkingConfig.thinkingBudget: 0, concatenate all non-thought parts, reject any response under 10 characters, and auto-bust suspiciously-short cached values on read. - Reddit doesn't expose reporter identity for anonymous user reports — by policy. We had to design around this: the group is keyed by reported-content author (not reporter), and mod-initiated reports surface separately through
Post.modReportReasons/Comment.modReportReasons. - Free-tier Gemini 429s under burst load. We added a Redis circuit breaker (
huddle:gemini:blocked-until) with a 5-minute cooldown that flips the UI to the deterministic heuristic until Gemini recovers.
Accomplishments that we're proud of
- The AI never sees content. This was a non-negotiable design constraint — it eliminates the entire class of hallucination and judgment errors that plague AI moderation tools. Every summary is grounded in deterministic facts; the LLM is just a sentence formatter.
- The fallback path is invisible to users. Whether Gemini returns prose or the raw-facts formatter takes over, the moderator sees the same shape of information in the same place — the LLM is genuine polish, not a load-bearing dependency.
- The Context Peek drawer is AI-free by design. It composes facts + history that are already in Redis. No extra LLM call. The "AI legibility" promise is literal: mods see the exact dict the AI received.
- Three independent AI surfaces, all sharing the same no-content guarantee. Summary, suggested-action, and removal-reason are three separate Gemini prompts, each tuned for its purpose. Each one has its own deterministic fallback so the UI never breaks.
- Ban closes the user-level loop too. Banning from the drawer cascade-removes every queued item the user authored in one server-side sweep — a Bajpai finding (mods still leave the queue to take user actions) addressed inside the queue.
- Backed by peer-reviewed research. Every feature maps to a finding in the Bajpai papers.
What we learned
- The most important architectural decision in an AI moderation tool isn't the model — it's deciding what the model doesn't get to see. Constraining Gemini to formatting-only made hallucination structurally impossible.
- Devvit's WebView model is more permissive than it looks once you accept that custom posts ARE the UI surface — no separate "splash + game expanded view" Blocks dance, just two HTML entrypoints sharing state through HTTP.
- Diagnostic affordances pay back fast. Surfacing the LLM source as a chip in the UI ("AI" vs "raw") and logging each fetch outcome to playtest CLI turned a long debug cycle into a single-glance check.
What's next for Huddle
- Live mod presence — avatar dots on each row so two mods don't act on the same item simultaneously (the 74.5% collision stat).
- Persistent realtime updates instead of 5-second polling, via Devvit's realtime channel.
- Toolbox usernote integration so existing notes surface in the Context Peek drawer.
- In-drawer mute / approve-user actions to complete the user-level loop.
- Reporter reliability scoring once Huddle has accumulated enough per-user history.
These were deliberately scoped out of the MVP per the 4-day budget. The whole MVP went to the headline 84%-fix.
Built With
- anthropic-claude
- claude-haiku
- devvit
- hono
- node.js
- react
- reddit-devvit
- redis
- tailwind-css
- trpc
- typescript
- vite
- vitest

Log in or sign up for Devpost to join the conversation.