-
-
user makes an highly bad post
-
other user reports it
-
confirmation of report
-
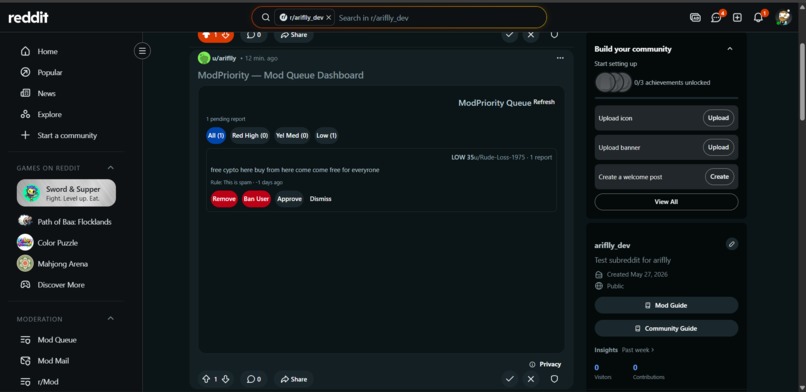
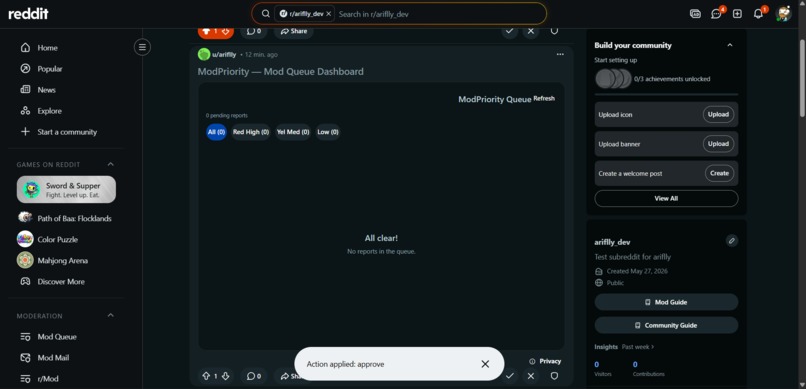
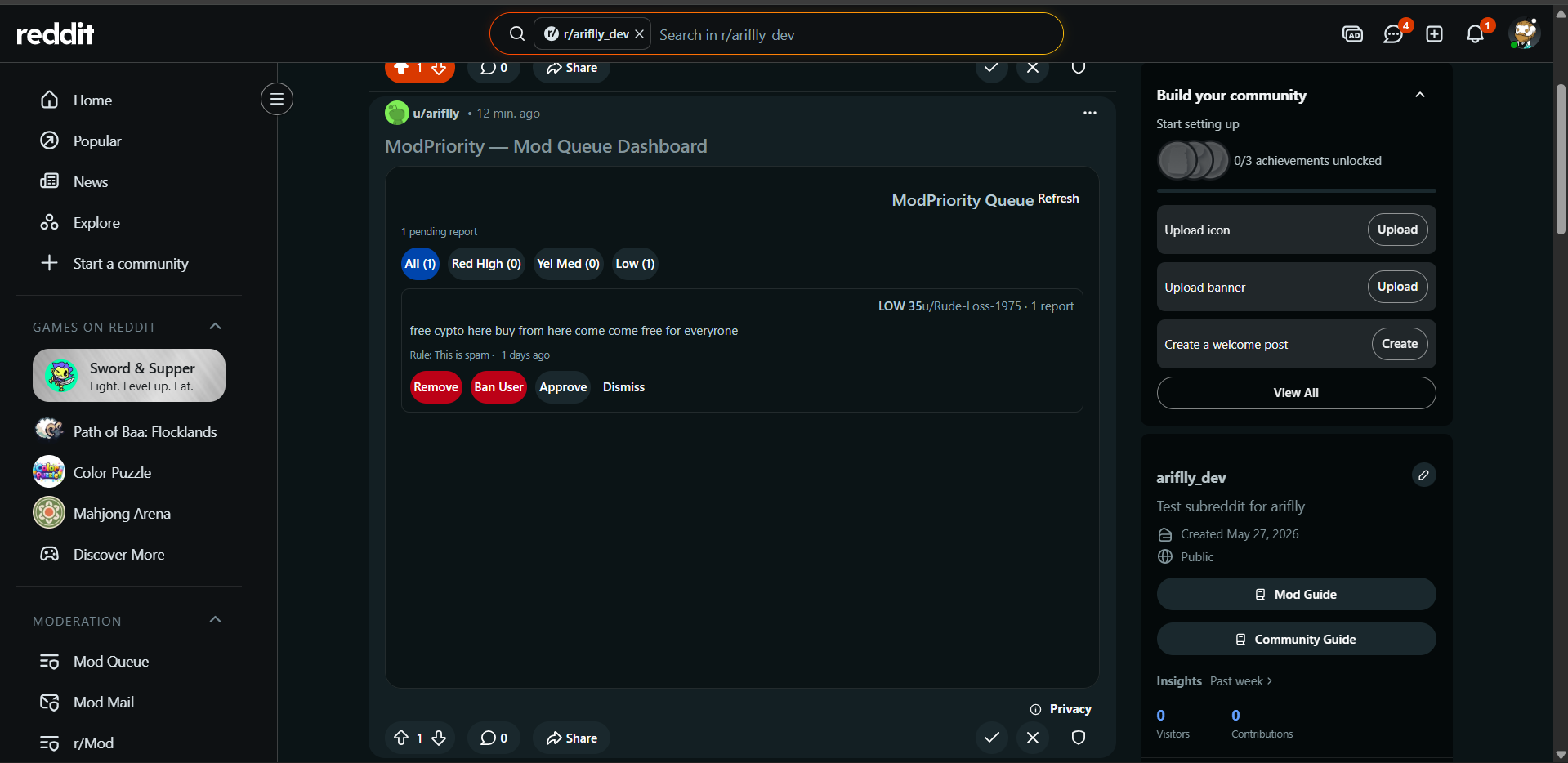
mod can now ban, and manage all the reports with ai powered score level deciding what to do with that particiular user
-
Done here

ModPriority — AI-Powered Report Triage for Reddit Moderators
Every report scored. Every threat surfaced. Zero config.
Inspiration
Reddit moderators are volunteers. Most juggle full-time jobs while managing communities of millions. Yet the tools they rely on are stuck in the past — the mod queue is chronological, treating a death threat and an off-topic meme as exactly the same thing. We've watched mods burn out from spending hours triaging noise instead of stopping harm. A moderator once told us: "I don't need help removing content. I need help deciding what to look at first." We built ModPriority to give them back their time and their sanity.
What It Does
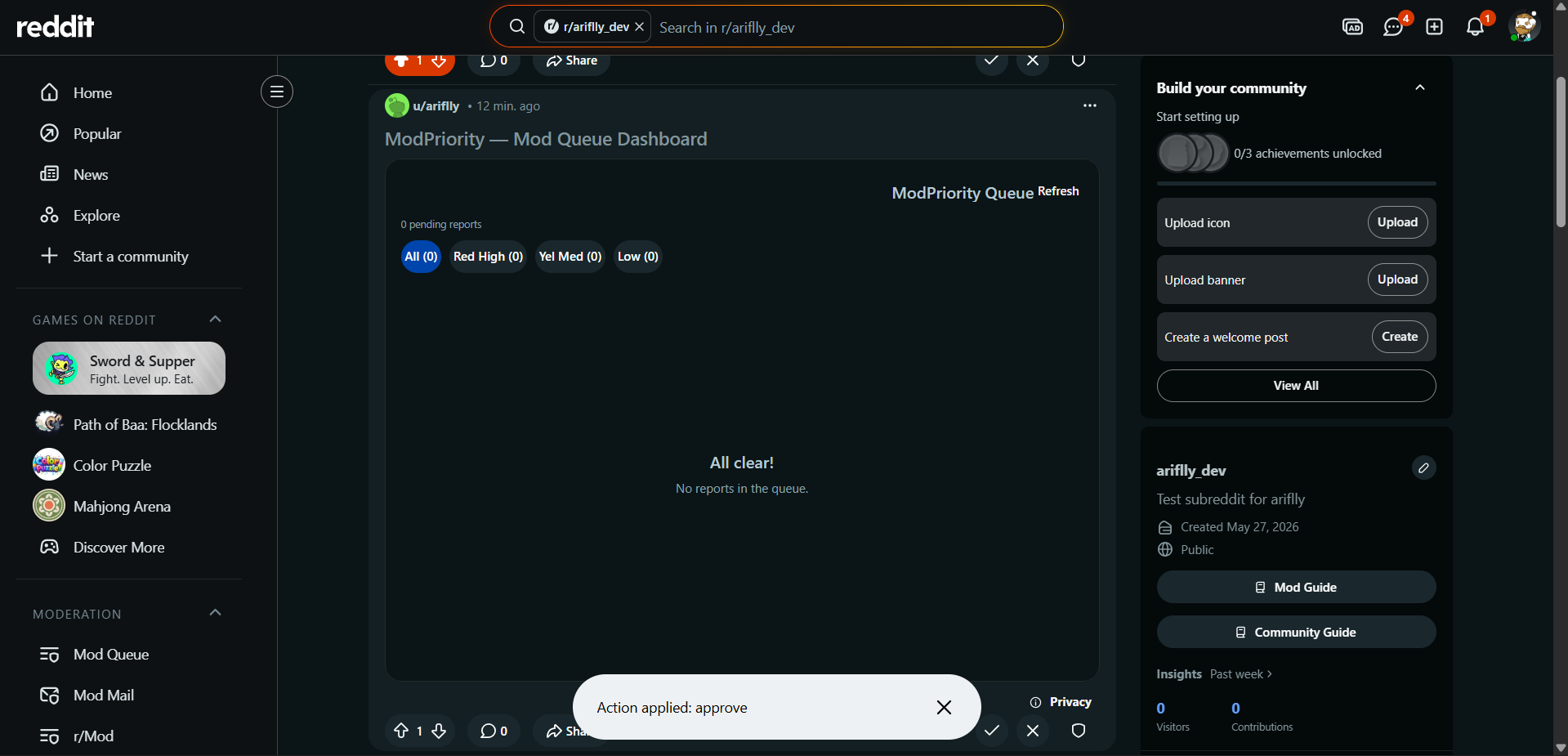
ModPriority scores every Reddit report on a 0-100 risk scale the moment it arrives. The worst content rises to the top of a live dashboard pinned to the subreddit. Moderators filter by High, Medium, or Low priority and take action — Remove, Ban, Approve, or Dismiss — with one click. Zero configuration required. It works the second it's installed.
How It Works
Scoring Engine
Each incoming report is scored using four weighted factors:
$$S = \min(R, 40) + \min(A, 20) + \min(C, 20) + \min(P, 20)$$
Where:
| Symbol | Factor | Max | Logic |
|---|---|---|---|
| $R$ | Content Severity | 40 | AI content analysis or config-based rule weight |
| $A$ | Account Age | 20 | $\text{age} \lt 30\text{d} \implies 20;\ \text{age} \lt 90\text{d} \implies 15;\ \text{age} \lt 365\text{d} \implies 10;\ \text{else}\ 5$ |
| $C$ | Report Count | 20 | $c \geq 6 \implies 20;\ c \geq 4 \implies 15;\ c \geq 2 \implies 10;\ \text{else}\ 5$ |
| $P$ | Reporter Reliability | 20 | Starts at $10$. $+2$ per confirmed, $-1$ per dismissed |
Priority thresholds:
\text{Priority} = \begin{cases}
\text{HIGH} & S \geq 70 \\
\text{MED} & 40 \leq S < 70 \\
\text{LOW} & S < 40
\end{cases}
AI Content Analysis
When configured, each report is sent to an LLM for real-time severity classification:
$$R = f_{\text{AI}}(\text{content}, \text{reportReason})$$
The model classifies content into {Harassment, Hate Speech, Spam, Misinformation, Off-topic, Other} and assigns a severity score from 0-40. On failure, the system gracefully degrades to config-based rule weights — no single point of failure.
Reporter Reliability
The reliability score $P$ evolves over time using a simple reinforcement model:
$$P_{t+1} = \operatorname{clamp}_{[0,20]}\left(P_t + \Delta\right)$$
$$\Delta = \begin{cases} +2 & \text{mod confirmed report (remove/ban)} \ -1 & \text{mod dismissed report (approve)} \ 0 & \text{mod ignored report} \end{cases}$$
This creates accountability — serial false-reporters lose influence in the scoring algorithm over time.
Architecture
User files report
│
▼
┌─────────────────────────────────────────┐
│ Devvit Triggers │
│ PostReport / CommentReport │
└──────────────────┬──────────────────────┘
│
┌────────────┼────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ AI Model │ │ Reddit │ │ Reporter │
│ Content │ │ User API │ │ History │
│ Severity │ │ (Age) │ │ (Redis) │
│ (0-40) │ │ (0-20) │ │ (0-20) │
└────┬─────┘ └────┬─────┘ └────┬─────┘
│ │ │
└────────────┼────────────┘
▼
┌────────────────┐
│ computeScore │
│ S(0-100) │
└───────┬────────┘
│
▼
┌────────────────┐
│ Redis Storage │
│ Sorted Sets │
│ + Hashes │
└───────┬────────┘
│
┌───────────┴───────────┐
▼ ▼
┌──────────┐ ┌──────────────┐
│Dashboard │ │ Actions │
│Custom │ │ Remove / Ban │
│Post (JSX)│ │ Approve/Dism │
└──────────┘ └──────────────┘
Data Model
Redis Sorted Set — ranked queue by score:
Key: reports:{subredditName}
Value: {member: "post_t3_abc123", score: 87}
Redis Hash — per-report details:
Key: report:{reportId}
Value: {contentId, authorId, authorName, contentPreview,
rule, reportCount, reporterId, score,
breakdown: JSON, timestamp}
Redis Hash — reporter profiles:
Key: reporter:{userId}:{subredditName}
Value: {totalReports, confirmedReports, dismissedReports,
reliabilityScore}
How We Built It
We built ModPriority as a native Reddit Devvit app — no external hosting, no separate database, no third-party frontend server.
Stack:
- Platform: Reddit Devvit SDK
- Language: TypeScript (strict mode)
- Storage: Redis (sorted sets + hashes)
- UI: Devvit BlockKit JSX (inline custom post)
- Testing: Vitest (20 unit tests on pure scoring logic)
- AI: llama-3.1-8b-instant via API
Key design decisions:
- All business logic is pure TypeScript with zero Devvit dependencies — testable, portable, and resilient to SDK changes
- Redis sorted sets are the perfect data structure for a priority queue — $O(\log n)$ insert, $O(\log n + m)$ range queries
- AI scoring gracefully degrades — no API key, no problem; falls back to config-based rule weights
- Reporter reliability uses a simple running score rather than requiring statistical significance — it starts working from the first report
Challenges We Ran Into
SDK Version Instability
The Devvit SDK is evolving rapidly. Our implementation targeted v0.11, but the CLI force-upgrades to v0.13 during upload — a version that had removed addCustomPostType and useAsync entirely. The type definitions were inconsistent across versions and the bundled declaration files in the npm package differed from what the build system resolved.
Solution: We mapped the v0.13 API surface (PostV2, CommentV2, Redis signatures) by inspecting the protobuf definitions directly and built thin adapter layers. For deployment, we used devvit playtest after pinning v0.11 via a local tarball — a workflow not documented anywhere.
Inline Dashboard Rendering
Devvit custom posts render synchronously inside Reddit's post layout. Async data fetching (from Redis to populate the dashboard) required useAsync, a hook that worked in v0.11 but was removed in v0.13. We also discovered that JSX key props on custom components are not stripped by Devvit's JSX transform, requiring index signatures on all component prop interfaces.
Solution: Built the component tree to work within Devvit's rendering constraints — all async state flows through useAsync with a refresh key dependency array, and component interfaces explicitly allow spread props.
AI Integration Without Breakage
Couldn't depend on the AI being available — moderators might not set an API key, the API might be down, or rate limits might be hit mid-analysis.
Solution: Built a resolveRuleAndSeverity() dispatcher that tries AI first, catches any failure silently, and falls through to config-based weights. The system never throws; it always produces a score. Reports scored by AI are tagged [AI] in the dashboard for full transparency.
Accomplishments We're Proud Of
- Full-stack in under 48 hours — triggers, AI scoring, Redis storage, live dashboard, action handlers, and scheduler, all working end-to-end
- Graceful degradation — AI scoring falls back to rule-based weights seamlessly; the app works with or without an API key, with or without network access
- Mathematically sound scoring — the $S = \min(R,40) + \min(A,20) + \min(C,20) + \min(P,20)$ formula is simple enough to explain to a mod, rigorous enough to be fair
- Reporter accountability — tracking reliability over time and feeding it back into the scoring creates a self-correcting system
- 20 unit tests on pure scoring logic, zero test dependencies on Devvit internals, 100% pass rate
- Shipped to a live playtest subreddit with the full interactive dashboard experience
What We Learned
- Architect for platform instability. When building on an evolving SDK, keep all business logic in pure functions with thin platform adapters. Let the SDK layer be swapped without touching the scoring engine.
- AI isn't a replacement for human judgment — it's a prioritization layer. The goal isn't to auto-moderate. The goal is to make sure the content that most needs human attention gets it first.
- Redis sorted sets are underrated. For a priority queue with range queries and O(1) removal, they're perfect. No need for a database.
- Fallbacks aren't optional. Every external dependency — API, SDK, network — can fail. A system that produces some score is always better than a system that throws.
- The Devvit community is small but passionate. We documented our SDK version pinning workaround and API mapping process to help the next builder.
What's Next
- Production deployment — launch to high-traffic subreddits (r/worldnews, r/gaming, r/AskReddit) where chronological queues cause the most harm
- Modmail digests — automated daily summaries of high-risk reports sent directly to mod inbox
- Trend analytics — per-subreddit dashboards showing report patterns, peak hours, and repeat offenders over time
- Community-specific fine-tuning — let moderators provide example content to calibrate the AI scoring for their community's specific norms and tolerance levels
- Mobile responsiveness — optimize the dashboard layout for the Reddit mobile app where many mods do their triage
Built With
- blockkit
- devvit
- groq-api-(llama-3.1-8b-instant)
- reddit-devvit-sdk
- redis-(sorted-sets-+-hashes)
- typescript
- vitest


Log in or sign up for Devpost to join the conversation.