-
-
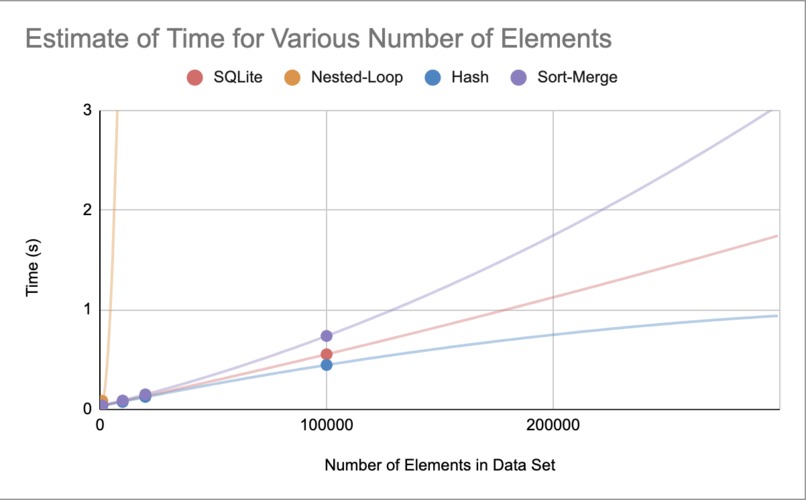
Modeling Extrapolation of Additional Elements

Inspiration
Modern database systems separate computing and storage. While datasets are being stored on servers specifically designed to store data, a different set of servers perform the actual analysis of the dataset. At query time, data must be transferred from the storage server to the compute server. However, sometimes the storage server is capable of performing basic analysis, so it might be worthwhile to perform some query processing in the storage layer.
What it does
Our project implements three different algorithms: nested-loop join, hash join, and sort-merge join. We performed comparisons on the efficiency between these approaches to determine which is the most suitable for different data sets.
How we built it
We created a database, implemented the three join algorithms using Python and SQL, and then ran tests to compare the runtimes of each algorithm.
Challenges we ran into
We had trouble figuring out how to implement some aspects of the more complicated join algorithms.
Accomplishments that we're proud of
We're proud of successfully completing the project and creating a clear visual presentation of the data despite beginning with limited experience in the field.
What we learned
How query federation is used in the real world, how data is stored and analyzed, and how people approach handling datasets.
What's next for Modern Query Federation
Moving forward, we could run more tests on different data scenarios, such as running each algorithm on already sorted data.





Log in or sign up for Devpost to join the conversation.