-
-

-
-
-

our fpga!
-
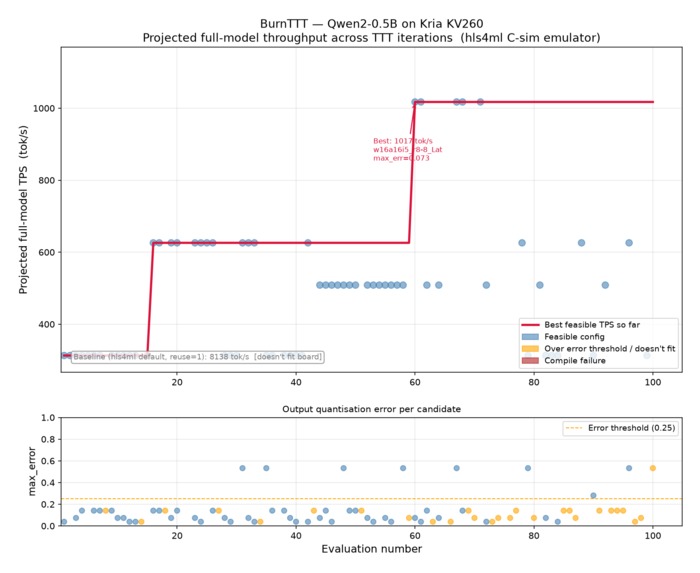
initial TTT
-
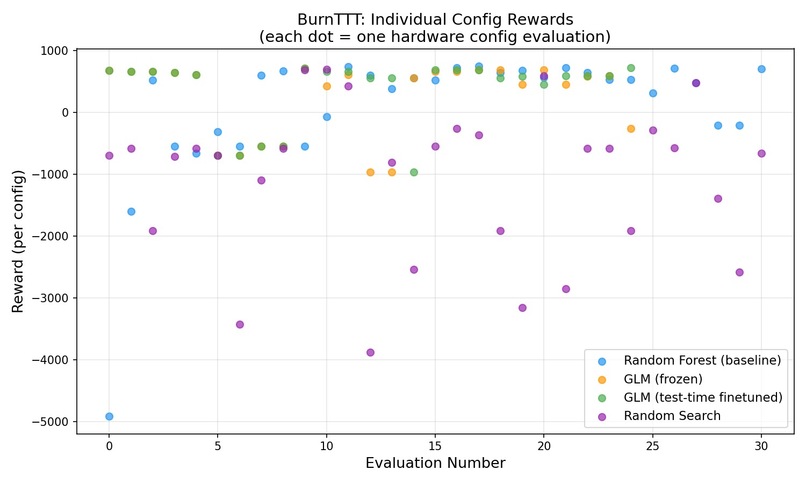
-
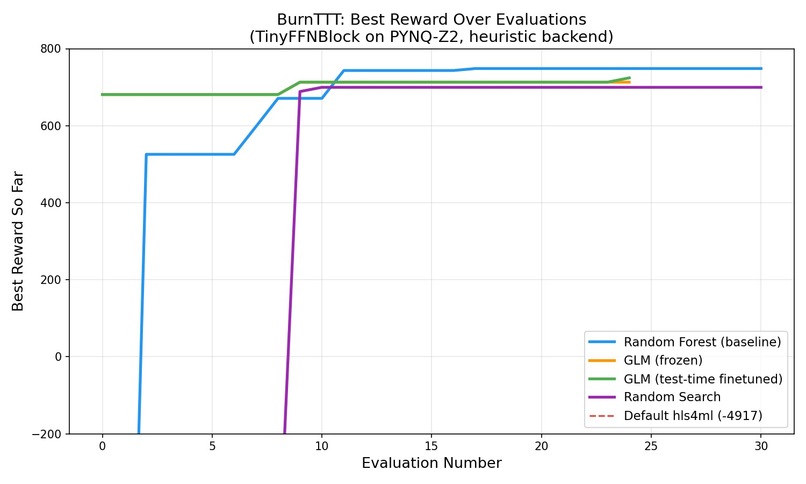
GLM-fintune-TTT

Inspiration
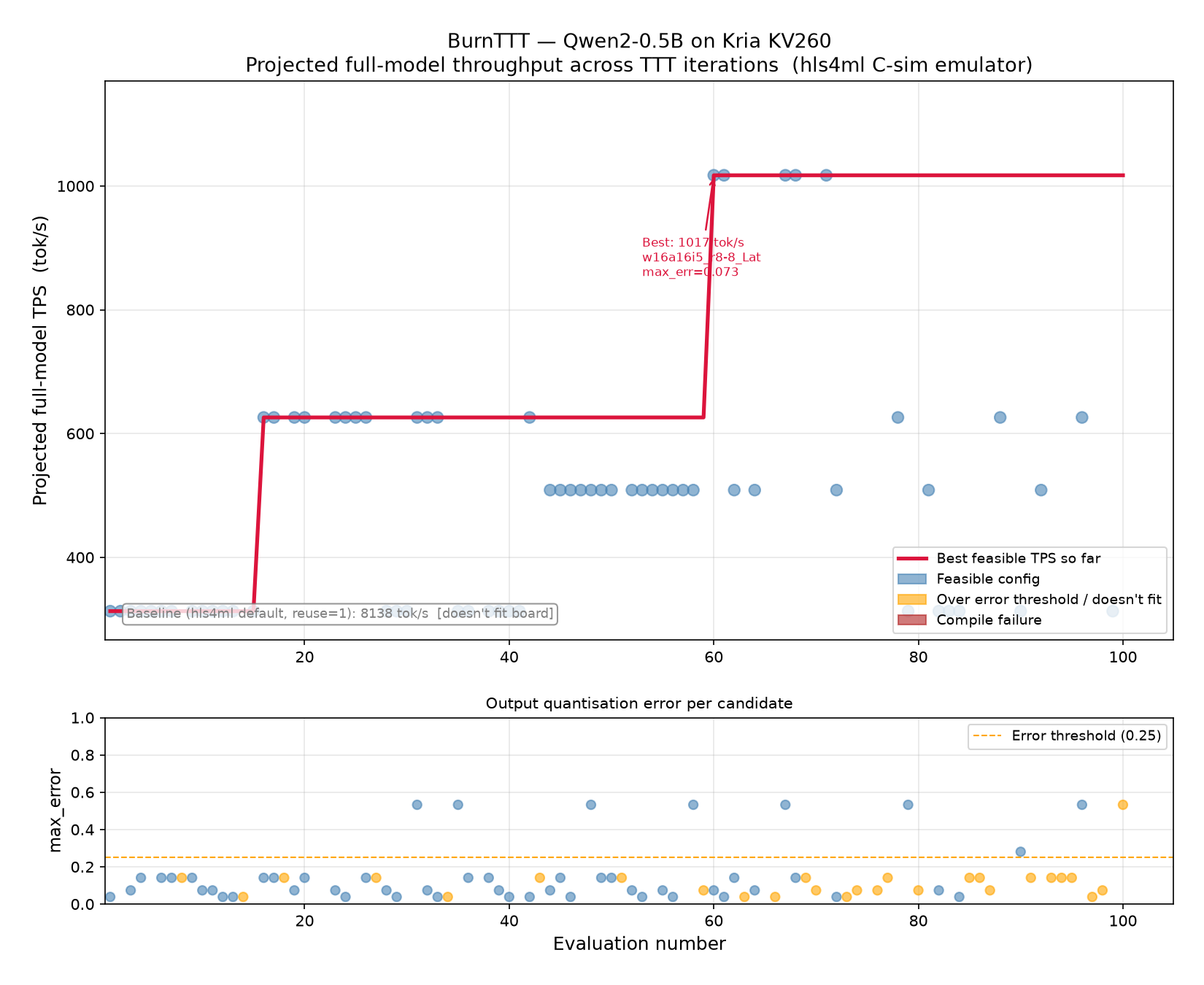
Deploying LLMs on FPGAs means navigating a tight tradeoff: fixed-point precision, loop unrolling, and reuse factors must satisfy both resource budgets (LUTs, DSPs, BRAM) and accuracy (quantization error). The sweet spot depends on the specific model block and the specific FPGA part — there is no one-size-fits-all default.
We were inspired by test-time training (TTT): instead of hand-tuning hls4ml knobs or training a static surrogate, what if an LLM authors hardware configs at compile time and finetunes its own weights (LoRA) on real feedback from synthesis and bit-accurate simulation? Our north star: Qwen-2B inference on FPGA at peak performance, reached by scaling from a toy FFN block up through full transformer sub-blocks — and eventually onto real boards (PYNQ Z2, AWS F2).
Our language model: Nanocoder
NanoCoder is our answer to a blunt constraint: a PYNQ-Z2 has 220 DSP slices, and a real coding LLM wants tens of thousands. So instead of shrinking someone else's model, we grew our own from scratch to fit the silicon. It's a GPT-Neo–architecture family (inherited from the TinyStories lineage) built with a ReLU MLP, chosen specifically because ReLU is hls4ml- and DSP-friendly when the block gets hardened into hardware. The series is a deliberate climb against one tension, small enough to harden ⟺ too small to write real code:
We did three iterations, and with the third we were able to generate coherent code:
- v1 - ~1.7M params, hidden 128, byte-level vocab (256), trained from random init on a small (~8.4 MB) local Python corpus. It learned the shape of code but not its meaning (plateaued ~2.27 bits/byte).
The win wasn't the model — it was the block: its MLP (131,072 MACs) fits the Z2 at ReuseFactor 596 and passed bit-accurate hls4ml csim at ap_fixed<18,7> (max error ~0.206).
- v2 - ~7.5M params, hidden 256, a ~4k BPE vocab so parameters buy logic instead of spelling tokens byte-by-byte. The BPE swap is free at the hardware boundary, the hardened MLP block is
vocabulary-independent, and that block (256→1024 = 524,288 MACs) still fits at ReuseFactor 2,384.
- v3 - the full model–silicon co-design: the MLP block kept vocabulary-independent and "DSP-shaped,"
activations kept quantization-friendly, every architectural choice made knowing one block must fold onto 220 DSPs at a fixed reuse factor. A model born already knowing where it will run.
The key realization NanoCoder encodes: the model is the part of the system you're allowed to redesign. The bitstream is fixed and the DSP budget is non-negotiable, so coherence and hardenability trade off directly, and NanoCoder is the lever we built to push on that trade-off, distinct from the Qwen2.5-Coder model that serves as the actual host-side chat assistant.
What We Learned
Each (model block, FPGA part) pair is a fresh optimization task. The honest TTT framing: the deployed bitstream is fixed; the training happens in the generator — GLM's LoRA weights adapt to this task's feedback before deployment.
We learned that hardware search is a constrained multi-objective problem. A design must first compile, then stay within accuracy tolerance (\epsilon_{\max}), then fit the part budget (\mathcal{B}), and only then optimize latency and resource use:
[ \text{reward}(c) = \begin{cases} -\infty & \text{compile fail or } \max_error > \epsilon_{\max} \ f(\text{latency}, \text{resources}, \text{accuracy}) & \text{feasible} \end{cases} ]
Board constraints flip the quantization strategy entirely: INT4 groupwise fits HBM-bound AWS F2 deployments; on a PYNQ Z2 with only 512 MB DDR, W8A8 wins because INT4 error compounds across layers and destroys decode quality. We also hit hls4ml's ceiling — linear projections compile cleanly, but attention softmax/RoPE need custom HLS.
How We Built It
BurnTTT is a test-time-trained LLM compiler built around a closed feedback loop:
model block → GLM authors hls4ml config → HLS/RTL → sim (+ synth) → reward
▲ │
└──── LoRA finetune on task feedback ◄─────────┘
- Config author — GLM (or a heuristic stand-in) proposes
BurnConfig/ per-layerBlockConfigJSON: bitwidth, integer bits, reuse factors, HLS strategy. - Feedback engine — hls4ml conversion → bit-accurate C-sim error → Vivado synthesis or analytical resource estimates → scalar reward.
- Repair loop — compile failures are fed back to GLM for agentic correction.
- Test-time finetune — high-reward
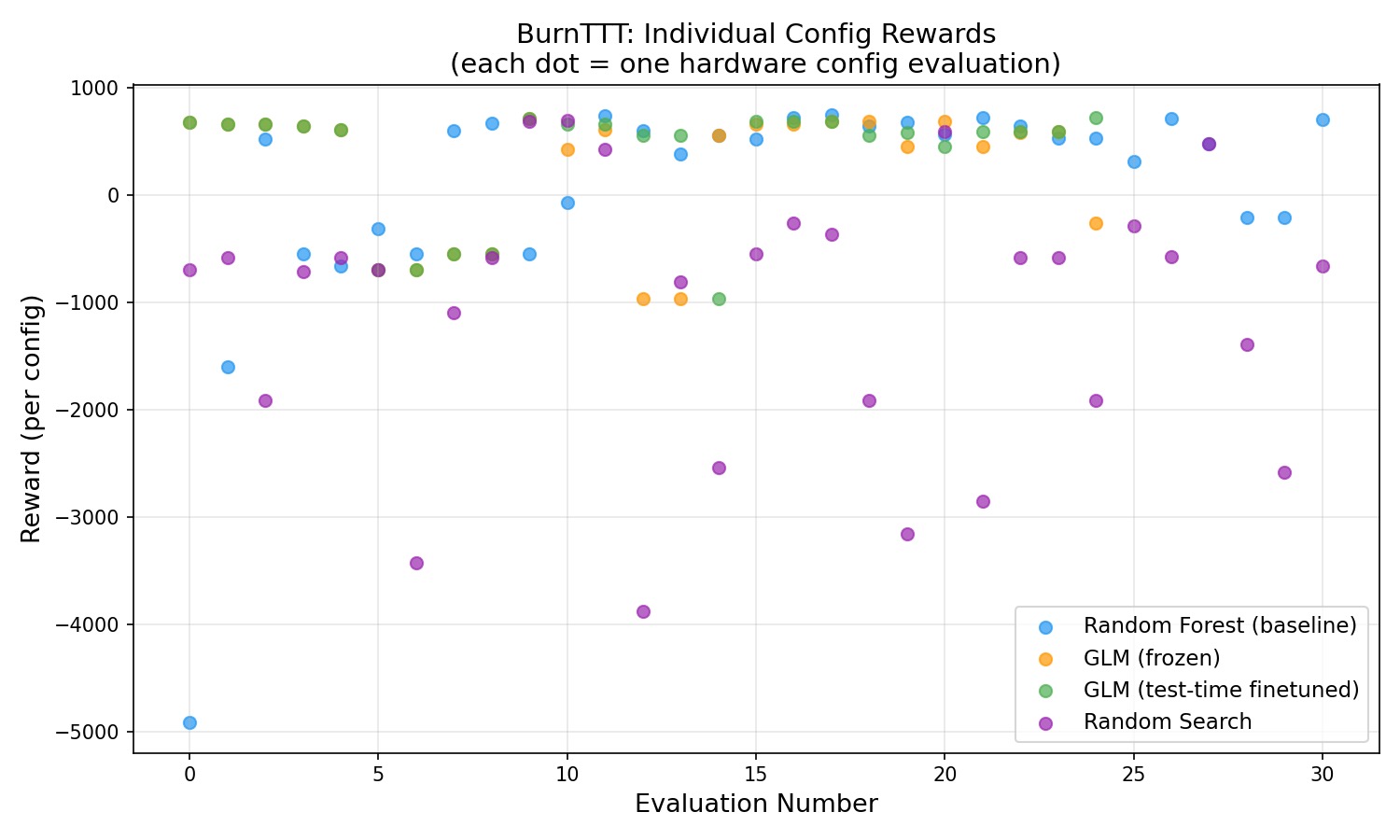
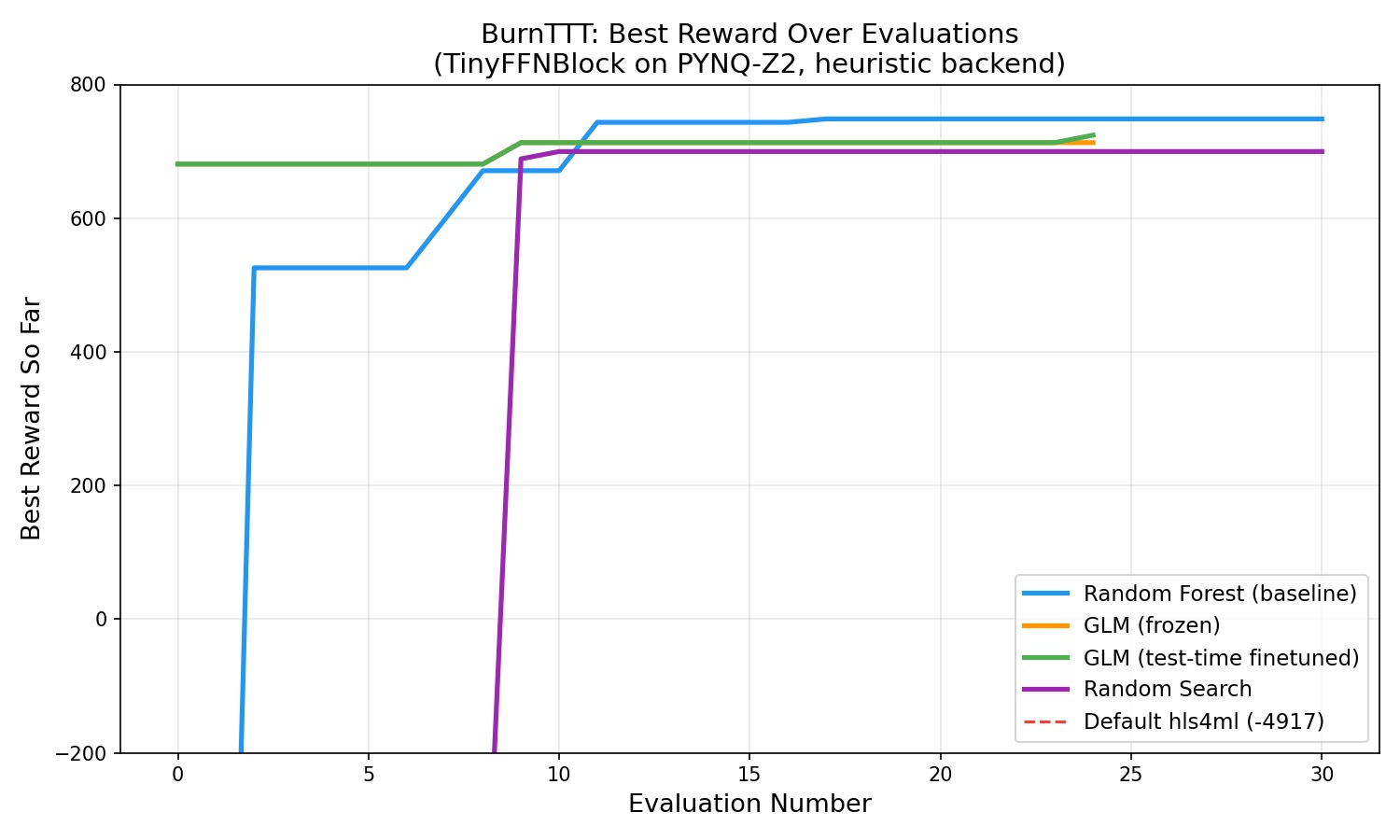
(prompt → config)trajectories drive LoRA SFT/DPO steps between search rounds. - Baselines — random search, random-forest surrogate, frozen GLM, and GLM+TTT run on equal eval budgets; a Streamlit dashboard plots reward vs. step.
We scaled in phases: toy FFN → Qwen SwiGLU MLP decomposition → two hardware paths:
qwen_fpga/— INT4 GEMV kernel + HBM streaming for AWS F2tinystories_z2/— W8A8 GEMV decoder for PYNQ Z2, with numpy/C++ golden vectors proving bit-exact arithmetic before synthesis
Challenges
- Search space explosion — precision × reuse × strategy combinations explode; per-layer
BlockConfigfor multi-projection blocks (Qwen MLP, attention) made the space manageable but harder to prompt. - Reward engineering — early unbounded rewards let resource-heavy valid designs score below compile failures; we fixed this with lexicographic tiers and budget-normalized scoring.
- Toolchain dependency — Vivado synthesis is slow and environment-specific; we built graceful degradation (analytical estimates off-toolchain, heuristic GLM backend off-GPU) so the full TTT loop runs anywhere.
- Attention gap — hls4ml handles matmul blocks but not softmax/RoPE; flagged as a research stub while we focus on the MLP/GEMV spine.
- Hardware bring-up — bitstream builds require board-specific HDK flows (F2 AFI, Z2 PYNQ); we de-risked by proving the integer datapath in software first (168/168 golden GEMV cases on Qwen, 49/49 on TinyStories) so "works on CPU" means "correct FPGA target."
Built With
- c++
- glm
- javascript
- keras
- peft
- pytorch
- qwen-2
- react
- tensorflow
- typescript
- vite






Log in or sign up for Devpost to join the conversation.