Inspiration
Search used to be about ranking in blue links. Now buyers increasingly ask AI systems for recommendations, comparisons, and shortlists. That creates a new problem for brands: even if they rank in Google, they may still be invisible inside AI-generated answers.
We built ModelRank to make that problem measurable. The goal was to create a live GEO agent, not a chatbot or a static dashboard. We wanted something a CEO could open, type in a brand like Linear or Notion, and immediately understand:
- whether AI systems mention the brand
- which competitors show up instead
- why those competitors keep winning
- what to do next to improve visibility
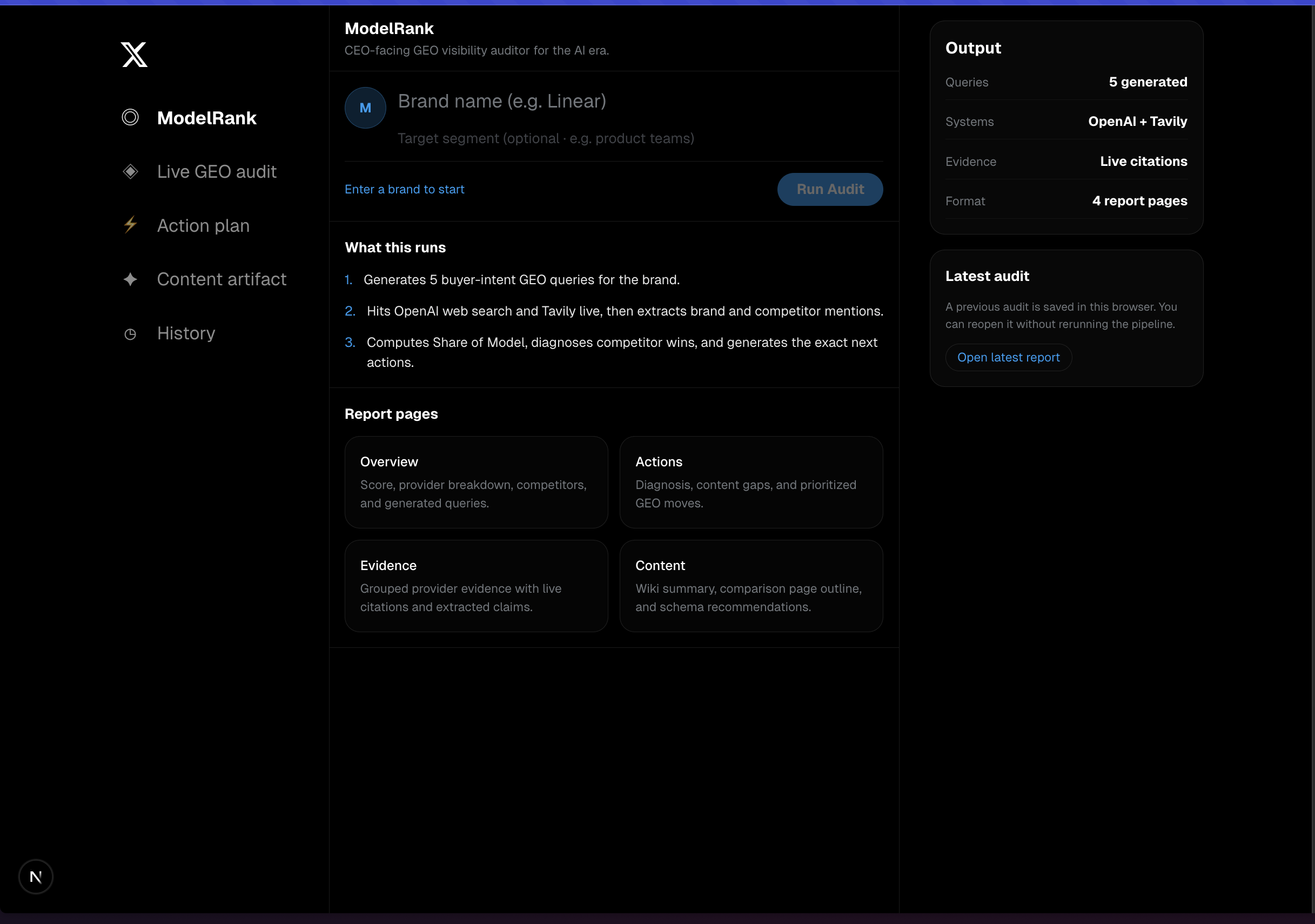
What it does
ModelRank audits how visible a brand is inside AI-style recommendation workflows.
A user enters:
- a brand name
- an optional target segment
Then ModelRank:
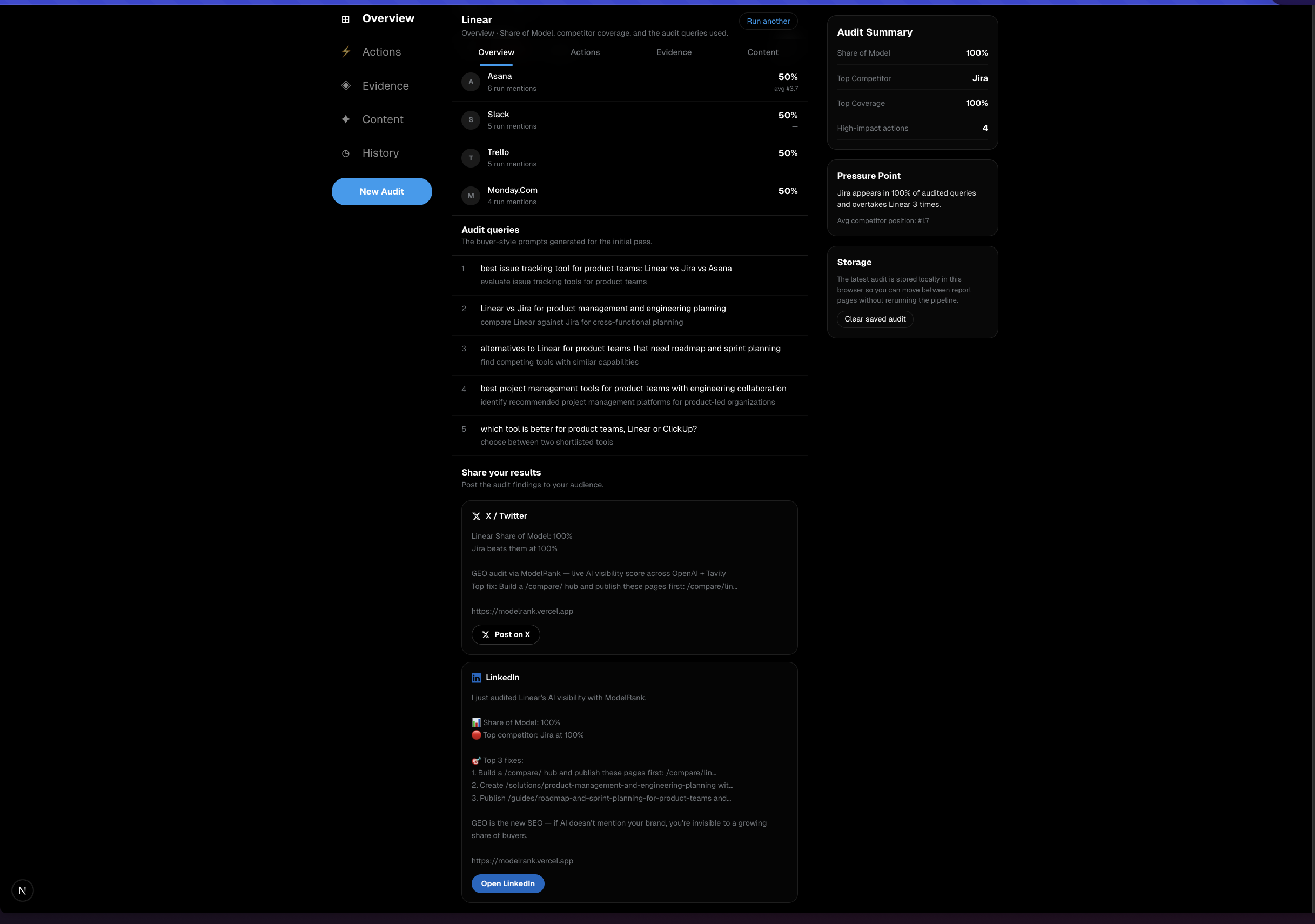
- Generates high-intent buyer queries
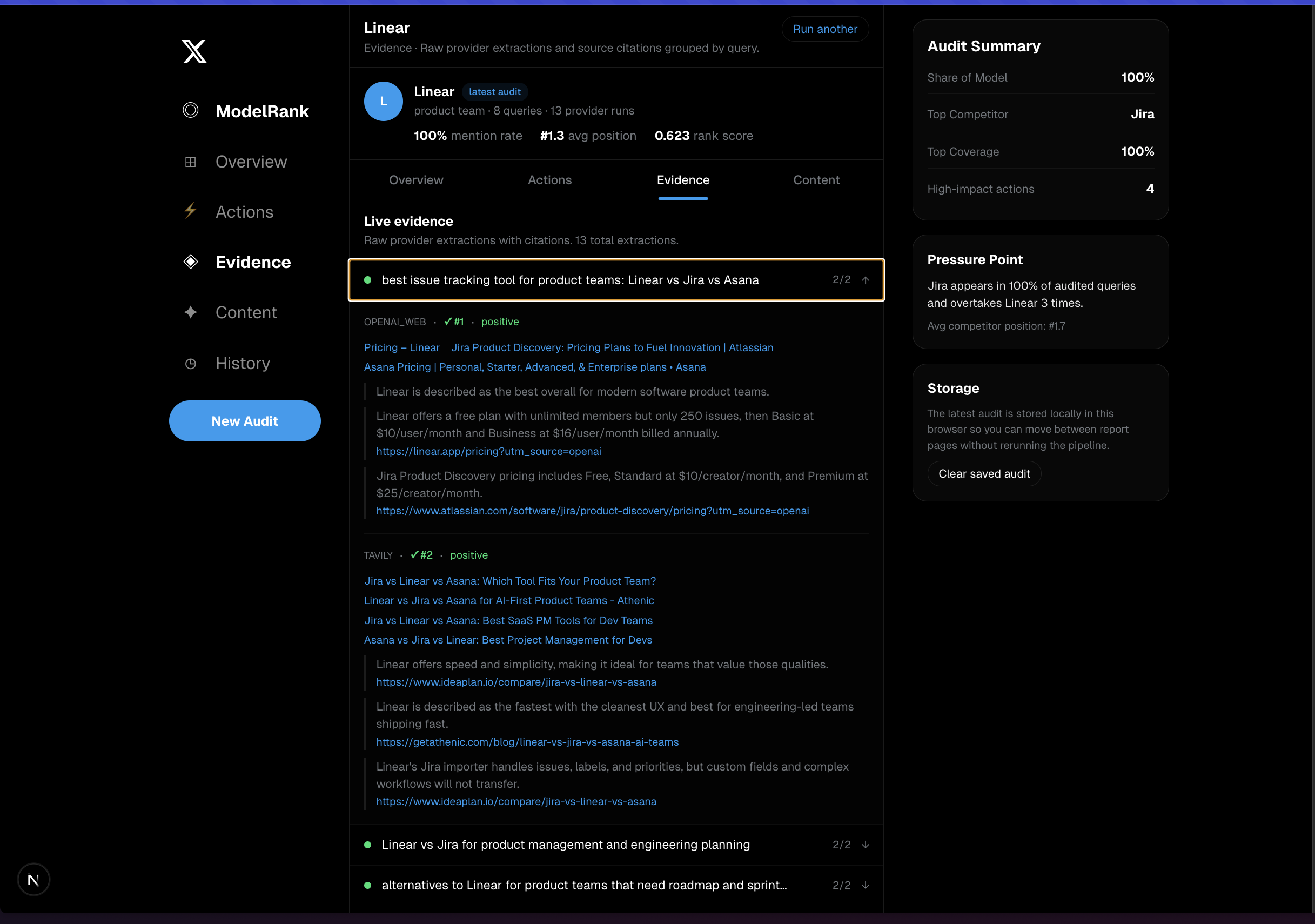
- Runs those queries against two live systems
- Extracts brand and competitor mentions
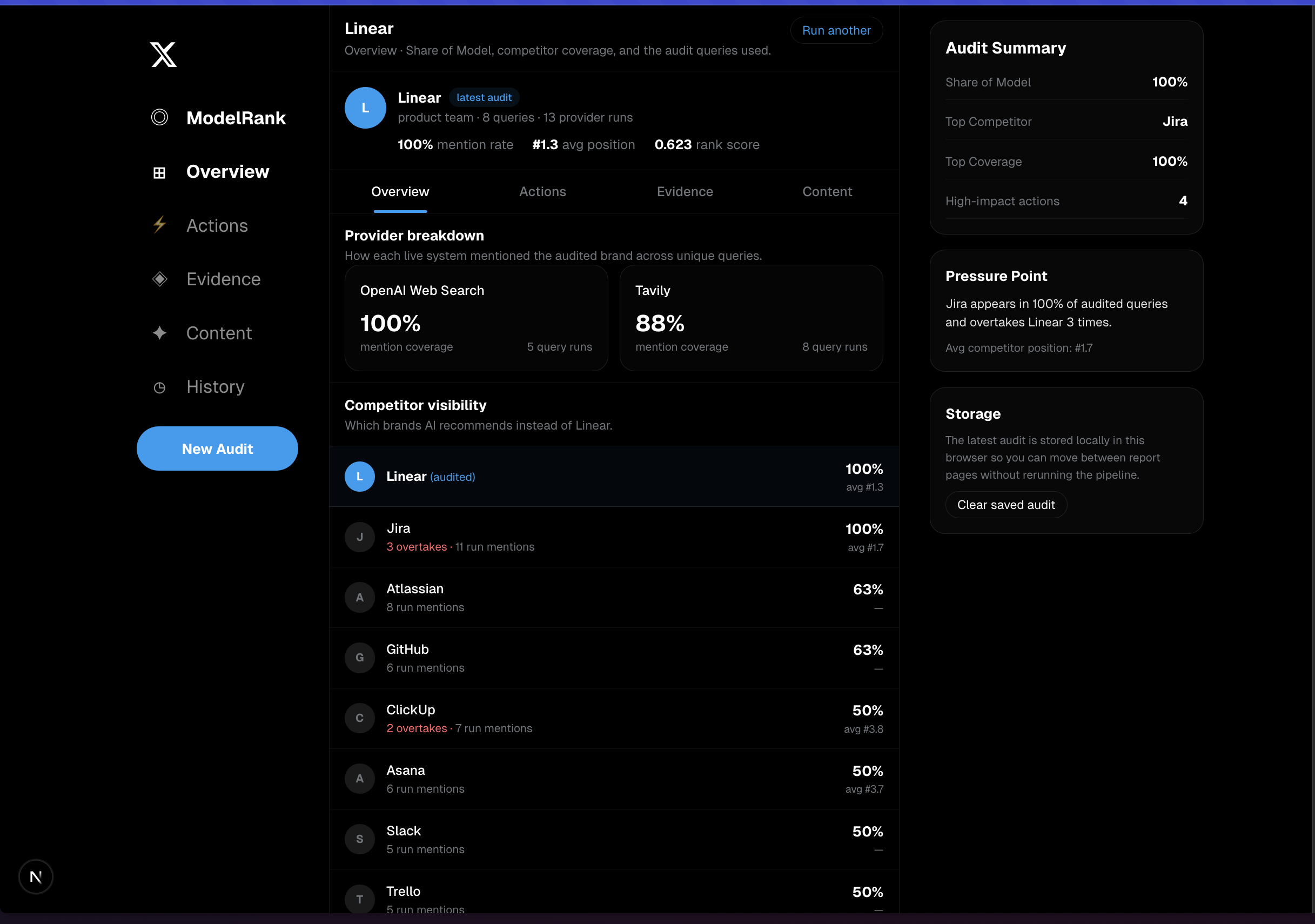
- Computes a Share of Model score
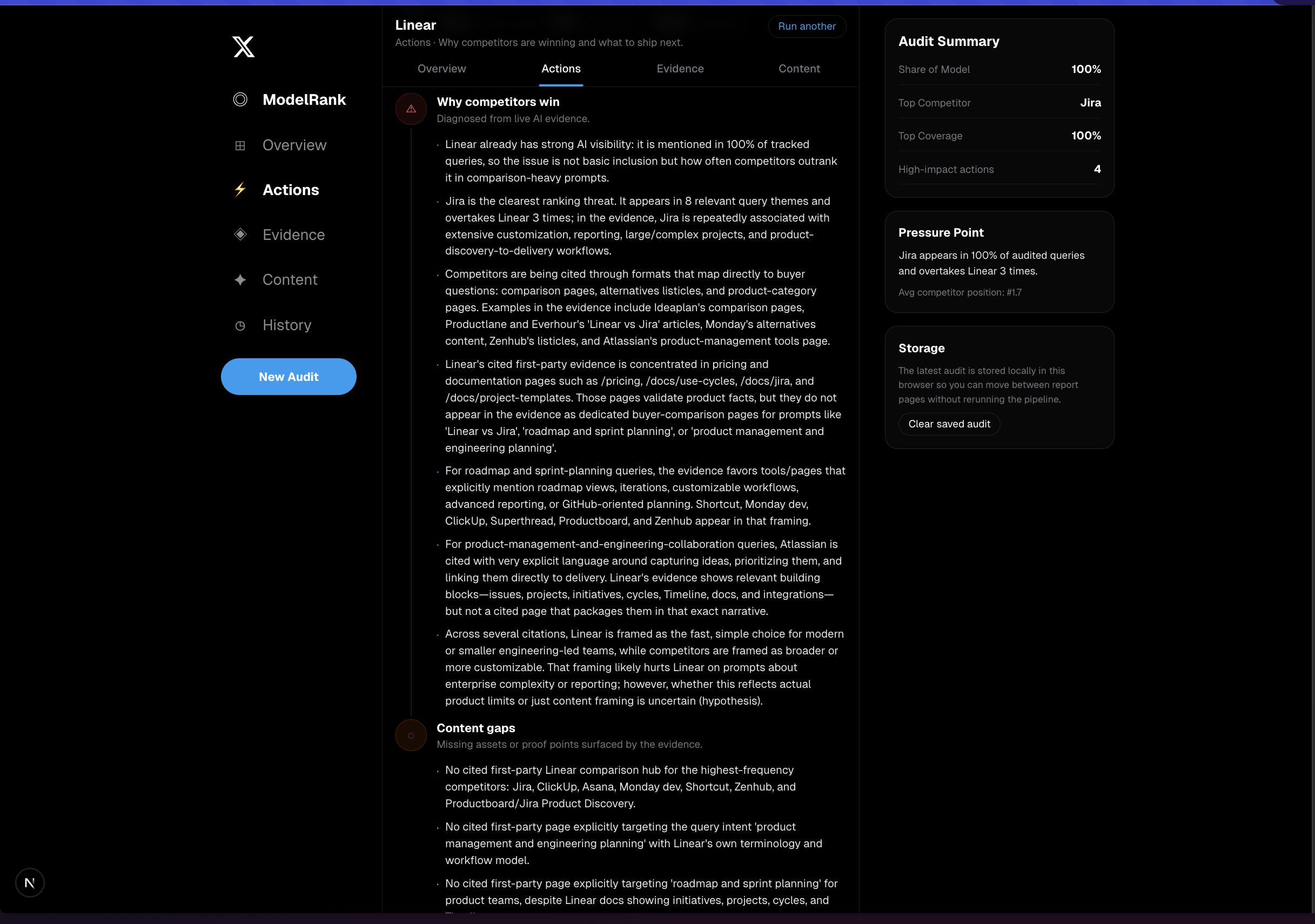
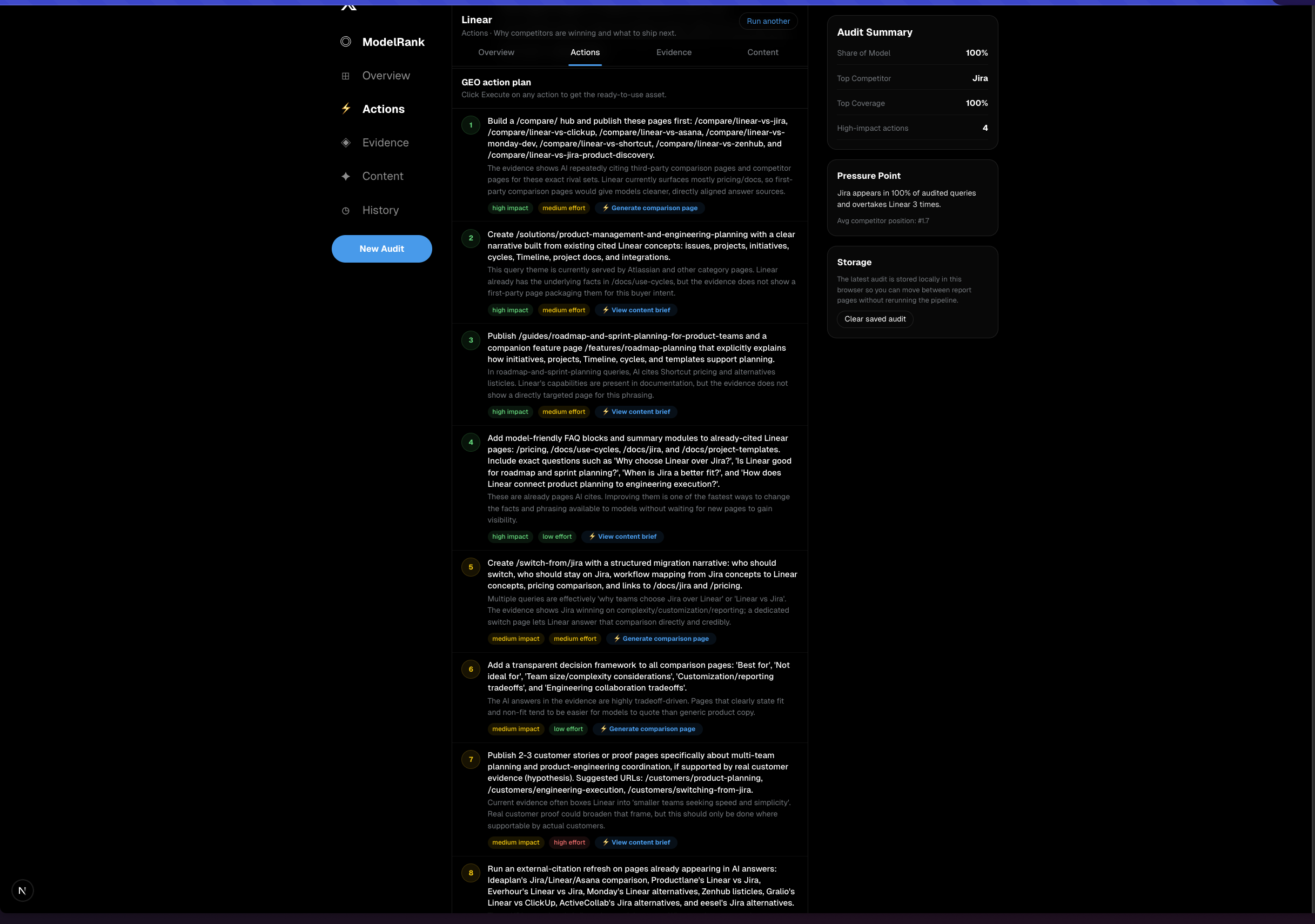
- Diagnoses why competitors are winning
- Produces a prioritized GEO action plan
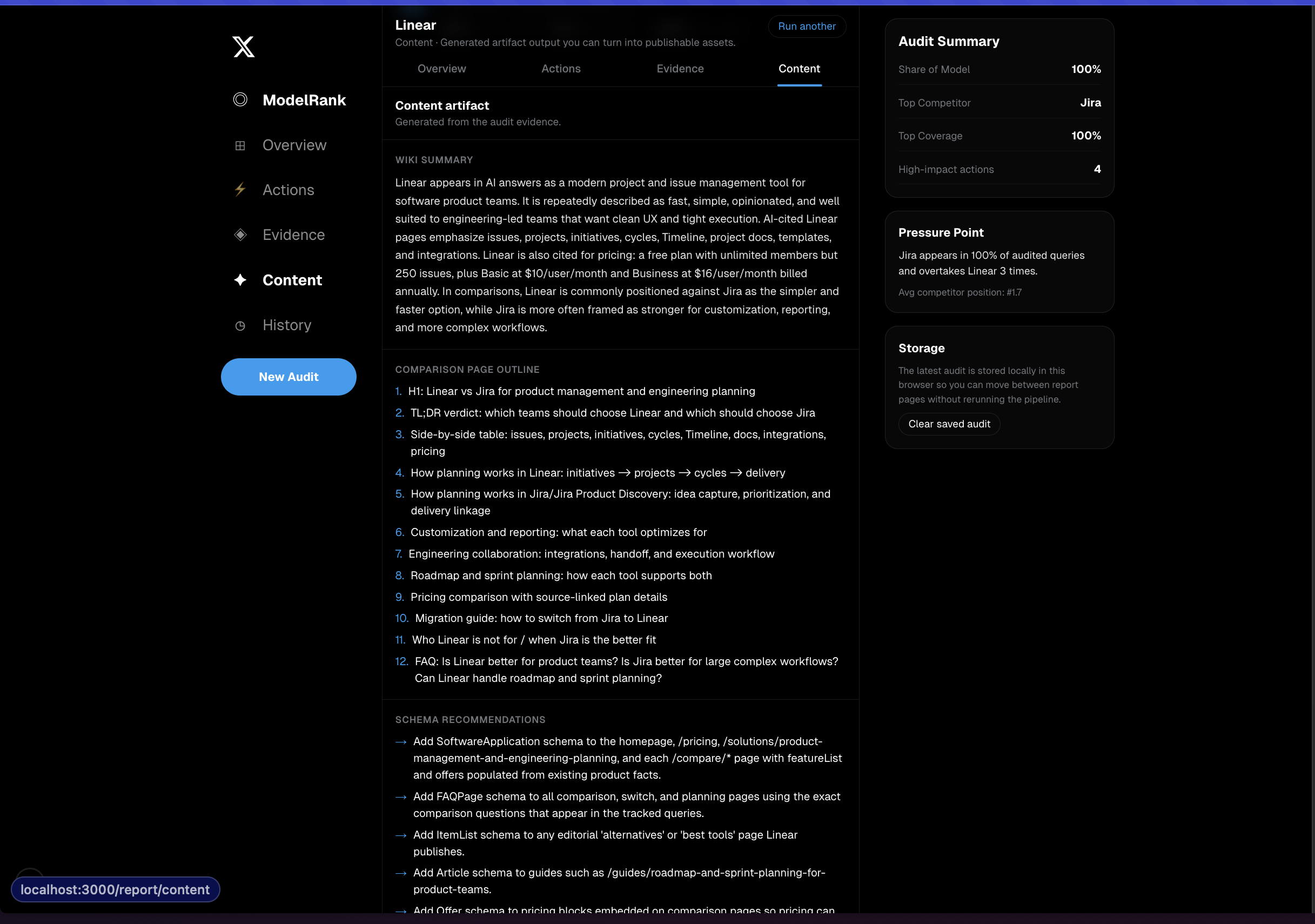
- Generates content and distribution artifacts that can actually be used next
The action plan is not generic advice. It includes concrete next moves such as:
- comparison pages and alternative pages to publish
- docs or help-center pages to create
- schema recommendations to add
- wiki-style summaries to tighten brand framing
- LinkedIn post angles for brand and founder distribution
- X / Twitter thread hooks based on the audit findings
- GitHub Gists or public docs pages for technical credibility
- supporting evidence and live citations for every recommendation
We use a simple but useful first-pass scoring model:
$$ \text{Share of Model} = \frac{\text{queries where the brand is mentioned}}{\text{total audited queries}} $$
We also track supporting metrics like average position, provider-level coverage, competitor coverage, and overtake count.
How we built it
We built ModelRank as a Next.js app with a single input surface and separate report views for the output.
Core stack:
- Next.js 16
- React 19
- Tailwind CSS 4
- OpenAI Responses API
- OpenAI
web_searchtool - Tavily search API
- Zod for validation
- TypeScript throughout
Pipeline:
Query generation
We prompt OpenAI to generate 5 buyer-style, high-intent GEO queries.Live retrieval
For each query, we run:- OpenAI web search
- Tavily search
Structured extraction
We pass raw search output back into OpenAI and extract:- whether the brand was mentioned
- brand position if inferable
- sentiment
- competitor mentions
- evidence snippets and URLs
Scoring
We aggregate results into a CEO-readable report with:- Share of Model
- average brand position
- weighted rank score
- provider breakdown
- competitor coverage
Recommendations and artifacts
We generate:- diagnosis
- content gaps
- prioritized actions
- schema recommendations
- comparison page outline
- wiki-style brand summary
- LinkedIn post ideas
- X / Twitter post hooks
- docs / Gist / public knowledge asset suggestions
On the frontend, we designed the interface to feel familiar and fast by using an X/Twitter-inspired layout with a strong feed metaphor, then split the report into separate pages for:
- Overview
- Actions
- Evidence
- Content
Challenges we ran into
The biggest challenge was reliability with live data.
A few things were harder than they looked:
Structured parsing
Free-form JSON is fragile. We had to move to stricter structured outputs and schema validation to avoid brittle parsing.Live API latency
Multi-query, multi-provider audits can get slow fast. We had to reduce unnecessary reasoning overhead, parallelize extraction, and keep the follow-up loop efficient.Evidence quality
It is easy for a system like this to sound confident while being weakly grounded. We had to keep the recommendation layer tied tightly to actual evidence and citations.Scoring correctness
A naive mention-rate calculation can become misleading when multiple providers are involved. We had to separate raw run mentions from query-level coverage so the metrics remained defensible.Turning insights into action
It is not enough to say “your competitors are winning.” We had to make the output operational by turning findings into actual next steps across brand distribution, social posts, docs, and technical assets.Client state across pages
Once we split the report into separate pages, we needed a clean way to preserve the latest audit result during navigation without forcing a rerun.
Accomplishments that we're proud of
We are proud that ModelRank is not a mockup.
It actually:
- uses live APIs
- breaks if the internet is unavailable instead of faking results
- shows real evidence and citations
- compares competitors programmatically
- computes a real visibility score
- generates concrete next actions from observed evidence
We are also proud that the output is usable beyond the demo. Instead of only showing metrics, ModelRank can point teams toward:
- site content to publish
- docs pages to write
- LinkedIn and X distribution angles
- GitHub Gists or technical explainers
- schema and knowledge-surface improvements
We are also proud that the product is focused. Instead of becoming a generic “AI marketing assistant,” it stays tightly scoped to one job: auditing brand visibility inside AI-generated recommendation flows.
What we learned
We learned that the hard part is not generating text. The hard part is building trust.
That means:
- grounding recommendations in evidence
- designing metrics that are easy to defend
- making latency manageable
- keeping the UI legible for non-technical users
- turning audit findings into actions teams can actually ship
- resisting the temptation to overbuild flashy features before the data pipeline works
We also learned that GEO is different from SEO in a practical way: it is not just about traffic, it is about being included in the model’s answer set at all.
What's next for ModelRank
Next, we want to make ModelRank more durable and more actionable.
Planned next steps:
- persistent audit history with shareable report URLs
- recurring audits and trendlines over time
- more provider coverage beyond OpenAI and Tavily
- deeper competitor evidence clustering
- stronger content gap detection by page type
- exportable CEO reports and team-ready action briefs
- auto-generated LinkedIn and X post drafts from the audit
- suggested docs pages, knowledge-base entries, and help-center content
- GitHub Gist / public technical explainer generation for technical products
- automated monitoring when a brand’s Share of Model drops
The long-term goal is to turn ModelRank into a continuous GEO operating system: not just showing where a brand stands today, but helping it systematically improve how AI systems talk about it tomorrow.
Built With
- next.js
- openai-responses-api
- openai-web-search
- react
- tailwind-css
- tavily-api
- typescript
- vercel
- zod

Log in or sign up for Devpost to join the conversation.