-
-
ModelMash Homepage
-
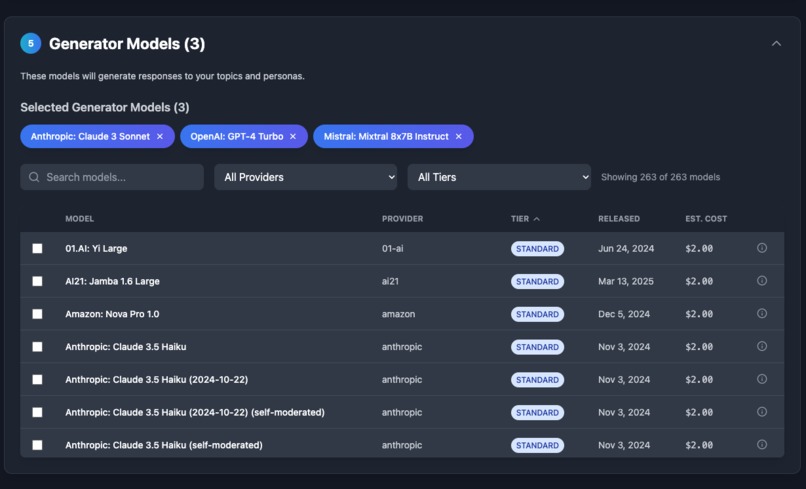
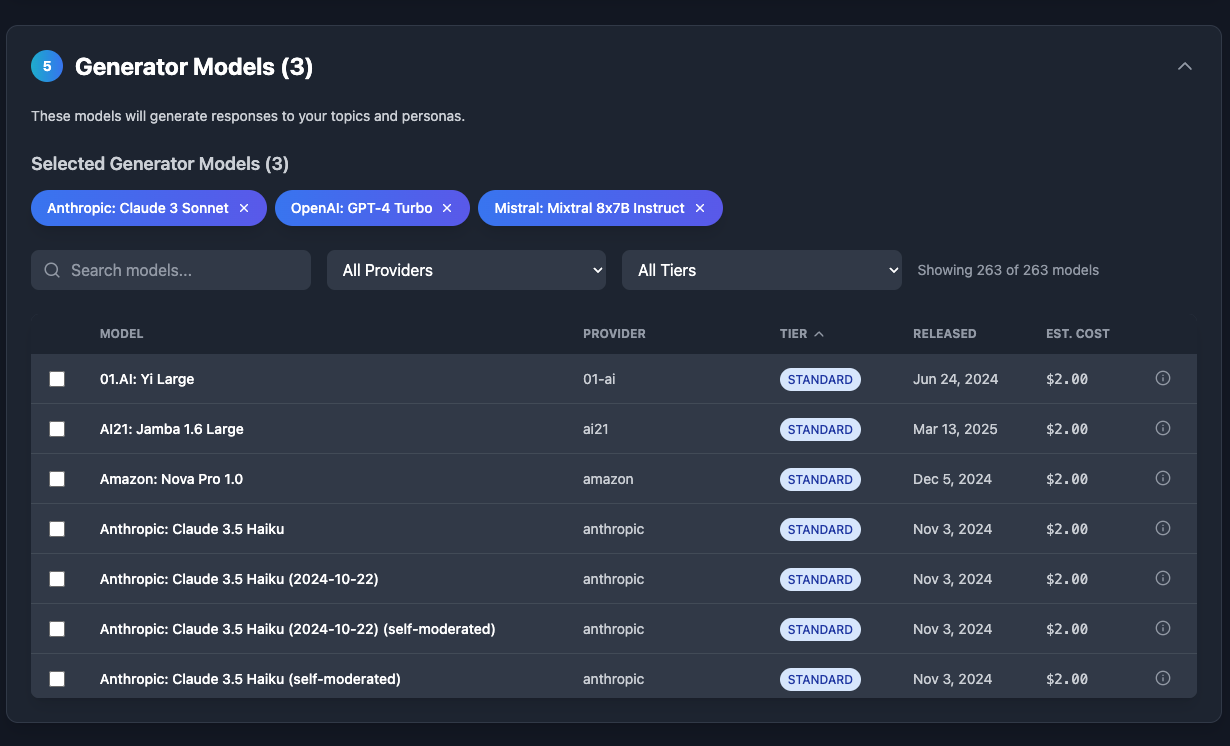
AI Model Comparison
-
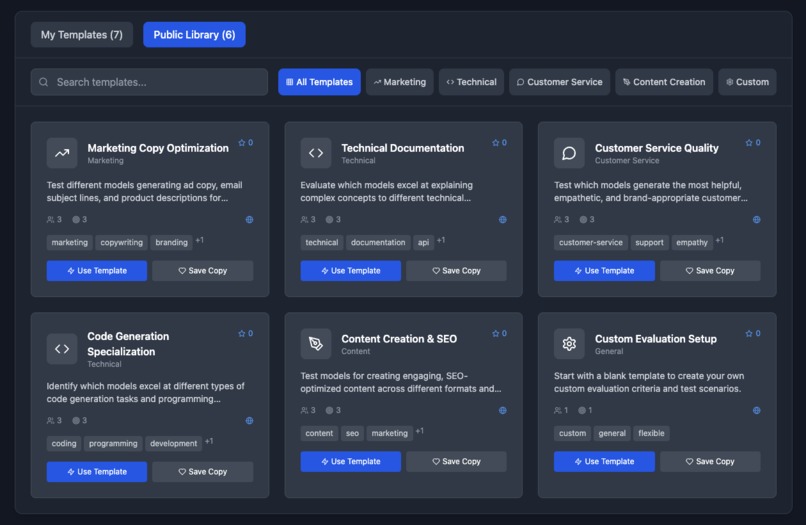
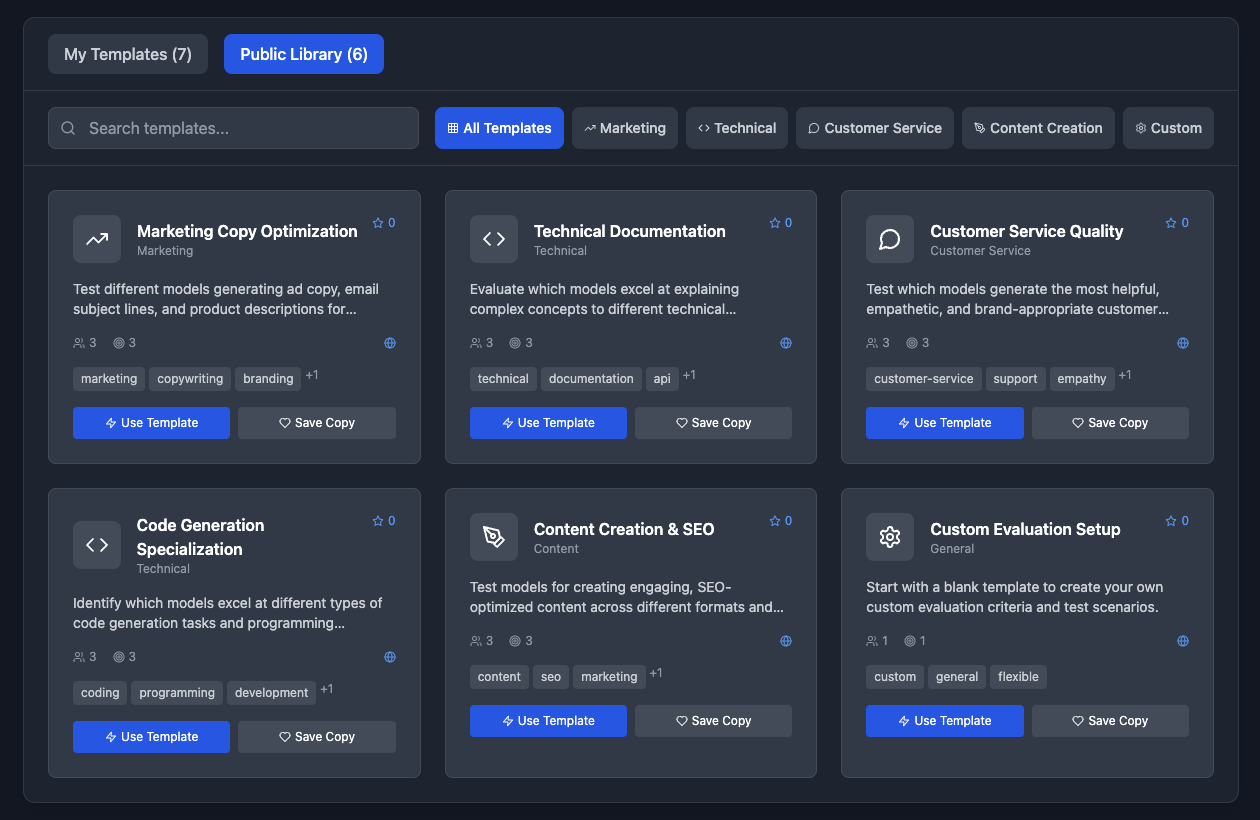
Template Library
-
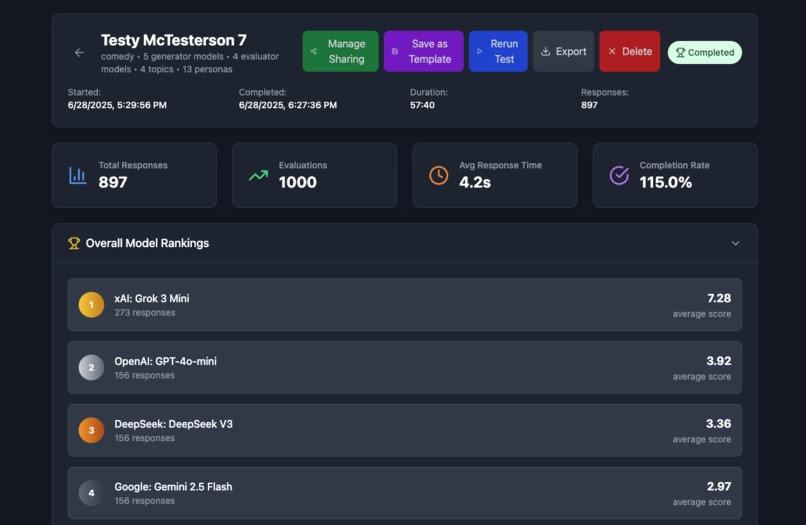
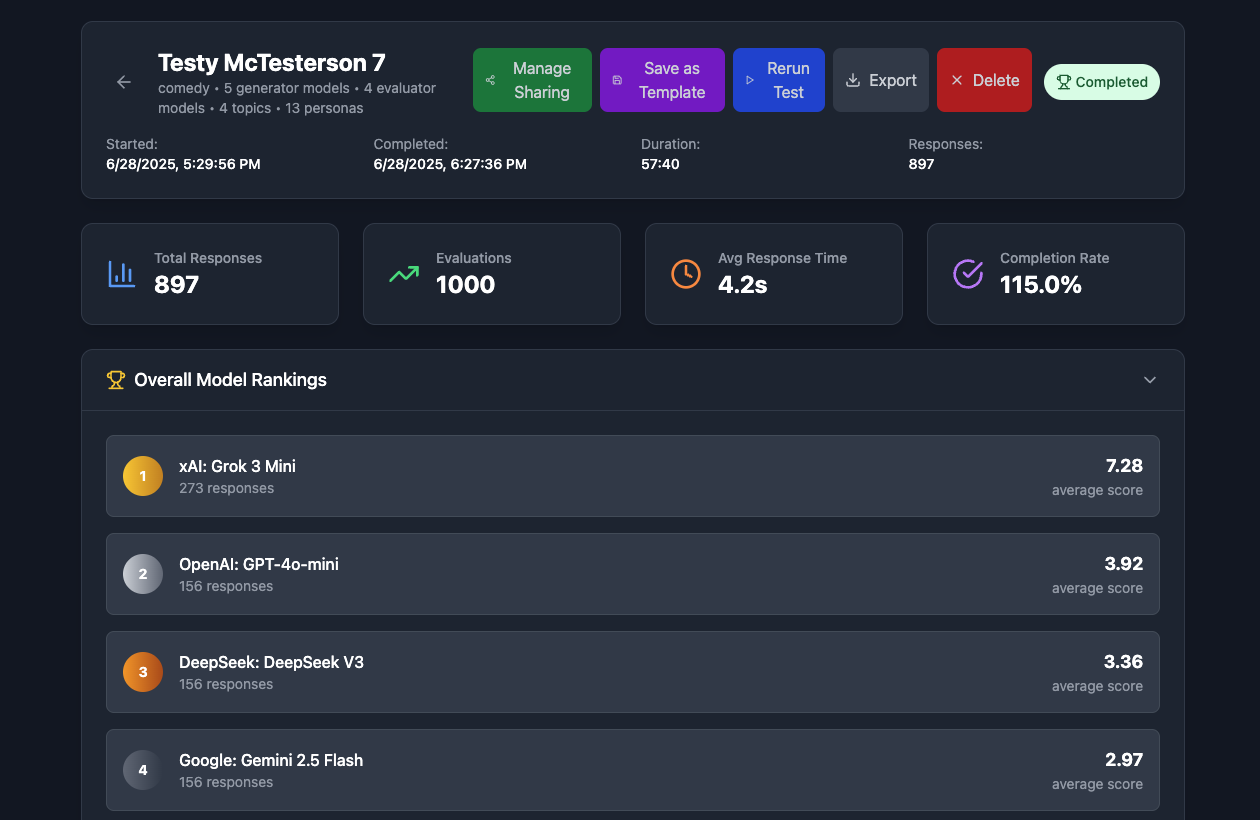
Test results dashboard
-
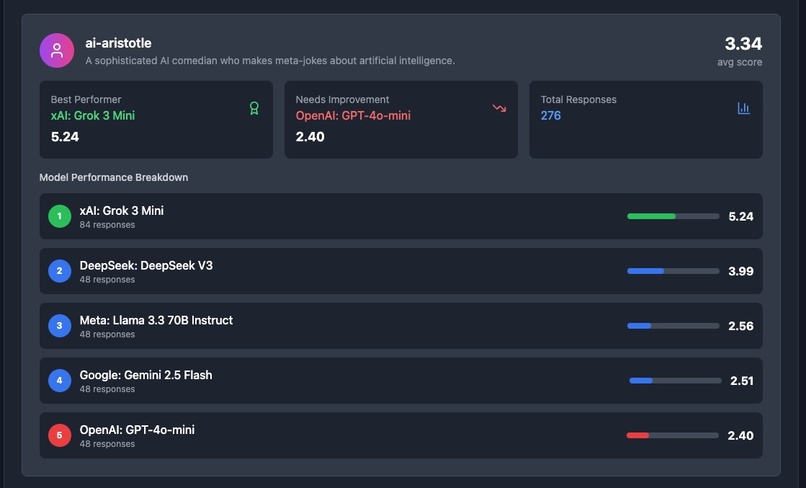
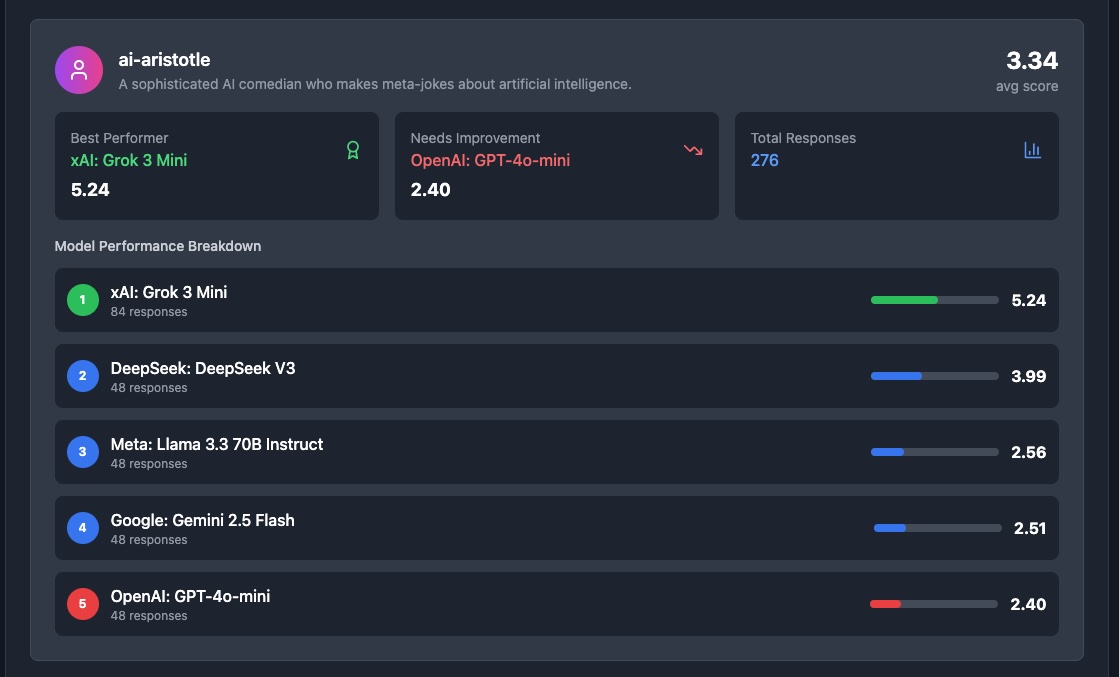
Detailed test results
ModelMash: Find the Perfect LLM
Inspiration
The inspiration for ModelMash came from a very specific problem I encountered while building RiffRoll, a platform featuring multiple AI comedians with different personalities and comedy styles. I also submitted this project to the hackathon, so this one grew out of a different project. HACKCEPTION! Basically, I realize that the LLM I was using was not funny. In fact, it kept talking about existential dread in every comedy bit and it was a bit of a bummer.
This led me to create an informal experiment where I had various models generate jokes, then used other models to rank and evaluate the humor quality. The results were fascinating. Different models truly excelled at different comedy styles. Some were better at wordplay, others at observational humor, and some had a knack for specific personas.
I had coded this up as a hacky experiment, but then it hit me: if this works for comedy, why not for everything else? Developers, marketers, and content creators are constantly choosing between different AI models for their projects, often based on gut feeling or limited testing.
What it does
ModelMash is a comprehensive AI model testing platform that transforms model selection from guesswork into data-driven decision making. Here's how it works:
Custom Benchmark Creation: Users select multiple AI models and define specific tasks they want to test - whether it's JavaScript coding, Python development, React components, SEO copywriting, creative writing, or telling different types of jokes.
Automated Multi-Model Testing: Each selected model completes the identical tasks, ensuring fair comparison across different AI providers and model versions.
AI-Powered Evaluation: Multiple evaluator models vote and rank the results across configurable criteria like accuracy, creativity, readability, and task-specific effectiveness. This eliminates single-model bias and provides more reliable scoring.
Detailed Performance Reports: Users receive comprehensive insights about which models excel at which tasks, complete with reasoning, scoring breakdowns, and actionable recommendations.
Report Sharing: I added a feature that lets you generate a link to share your reports with colleagues.
Community Templates and Saved Tests: I built a system that pre-fills testing configurations for common use cases such as SEO, coding, etc. Users can also save their test configurations as a template and make those public. This encourages sharing and viral spread.
Pay-as-You-Go Model: Users design their test, pay a few dollars to run it, and get results without ongoing subscriptions. This was both to keep it simple and because I didn't feel like building a subscription business out of this.
How we built it
I built ModelMash using Bolt, Supabase, and OpenRouter.
Frontend: React application built using Bolt.new, of course.
AI Integration: OpenRouter serves as the unified API layer, giving access to dozens of different LLM providers (OpenAI, Anthropic, Google, Cohere, and many others) through a single interface.
Backend & Database: Supabase handles user authentication, test configuration storage, results persistence, and real-time updates. Railway actually runs our persistent function for querying the LLMs. Supabase kept going to sleep during our tests, so Bolt suggested Railway (thanks!).
Deployment: The entire application is deployed on Netlify through Bolt.
Challenges we ran into
API Rate Limiting: Coordinating dozens of requests across multiple model providers simultaneously while respecting each provider's different rate limits was like conducting an orchestra where every musician plays at their own tempo. I had to implement queuing, retry logic, and request batching. In addition, Supabase functions, go to sleep after a short time, so for long running tests I had to find a different solution.
Cost Optimization: Running comprehensive tests across many models gets expensive fast, multiplying with each new model, persona, or task. I spent considerable time optimizing prompt efficiency, implementing smart caching for similar queries, and finding the sweet spot between thorough evaluation and reasonable pricing.
Inconsistent Output Formats: Different models return responses in wildly different formats, some verbose, some terse, some with markdown, others plain text. I tried using only models that support JSON output, but still had to add some parsing because sometimes they just don't listen.
Accomplishments that we're proud of
Solving Real Model Bias: The multi-model evaluation system actually works incredibly well. By using diverse AI judges with carefully crafted evaluation criteria, the results are often more nuanced and reliable than single human evaluation.
Making AI Evaluation Accessible: What used to require expensive consulting or extensive manual testing can now be done by anyone for a few dollars. This democratizes access to sophisticated model comparison.
Technical Architecture: Successfully orchestrating complex multi-model workflows through OpenRouter and Railway while maintaining a smooth user experience was a significant technical achievement.
User Experience: Despite the underlying complexity, the interface makes it easy for users to design sophisticated tests and understand nuanced results.
What we learned
Specialization is Everything: The most surprising discovery was how specialized different models are. GPT-4 might excel at creative writing but Claude might be better for technical documentation. Gemini could dominate coding tasks while smaller models might be perfect for specific copywriting styles. No single model rules them all. Grok seems to be the funniest for most personas, but Deepseek is up there!
AI Judges Are Surprisingly Good: When properly configured with diverse perspectives and clear criteria, AI evaluators produce remarkably consistent and insightful results. They often catch subtleties that humans might miss and don't suffer from fatigue or unconscious bias.
The Market Need is Real: Early user (me) feedback validated that this addresses a genuine pain point. Developers and content creators are hungry for data-driven model selection rather than relying on marketing claims or trial and error.
Prompt Engineering at Scale: Building evaluation prompts that work consistently across different domains taught me valuable lessons about creating robust, generalizable AI instructions.
What's next for ModelMash: Find the Perfect LLM
Specialized Industry Benchmarks: Adding domain-specific tests for legal writing, medical documentation, financial analysis, and other professional use cases where model selection is critical.
Historical Performance Tracking: Building trend analysis to show how different models improve over time and alerting users when new models outperform their current choices.
API and Integration: Developing APIs so other applications can programmatically run model evaluations, and integrating with popular development tools and content management systems.
Advanced Analytics: More sophisticated statistical analysis of results, confidence intervals, and significance testing to help users make even more informed decisions.
Real-time Model Monitoring: Continuous evaluation of models on user-defined criteria, with alerts when performance changes or new models become available that might be better for specific use cases.
The vision is to make ModelMash the definitive platform for AI model selection - where every AI implementation decision is backed by empirical data rather than guesswork.
Built With
- bolt
- openrouter
- railway
- react
- supabase











Log in or sign up for Devpost to join the conversation.