-
-
ModelArena_1
-
ModelArena_2
-
ModelArena_3
-
ModelArena_4
-
-
-
-
-
-
-
-
-
-



Inspiration
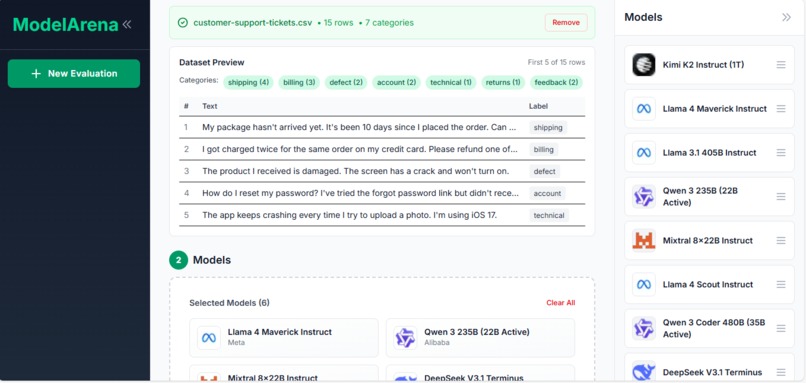
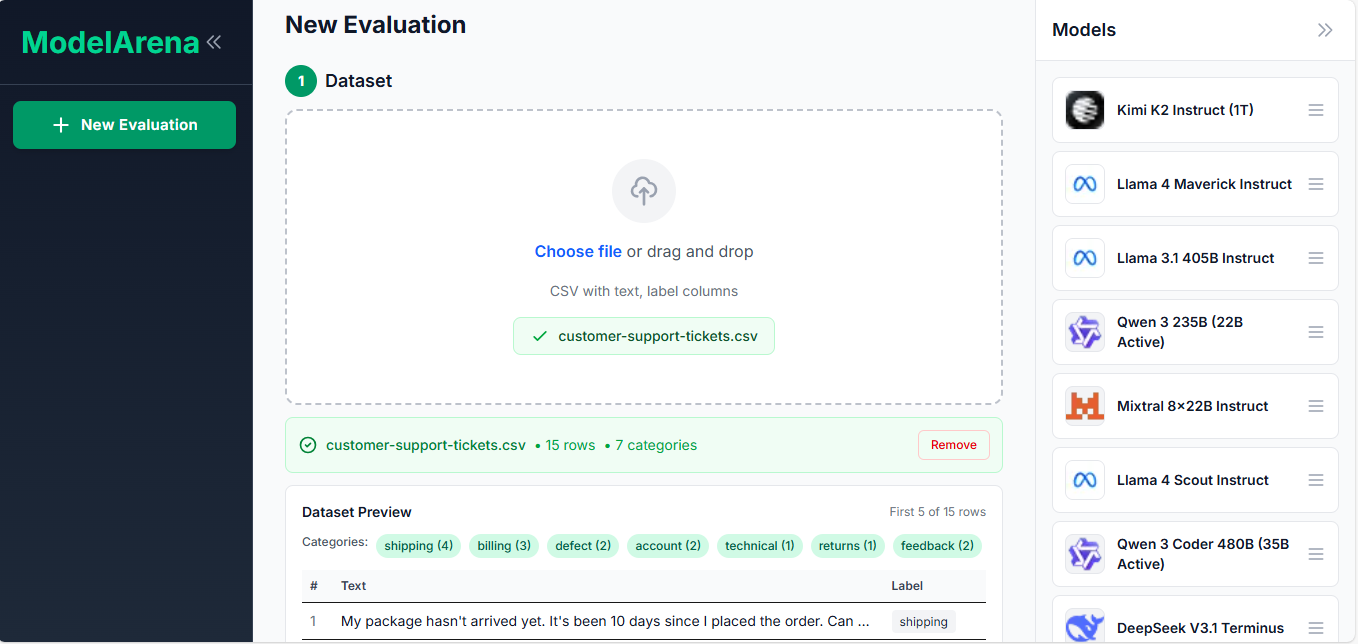
We noticed developers and data teams spending hours testing different LLM APIs manually to find which model works best for their specific task. Generic benchmark scores don't reflect real-world performance on your actual data distribution. We built ModelArena to make this process systematic: upload your dataset once, test multiple models simultaneously, and get clear performance comparisons.
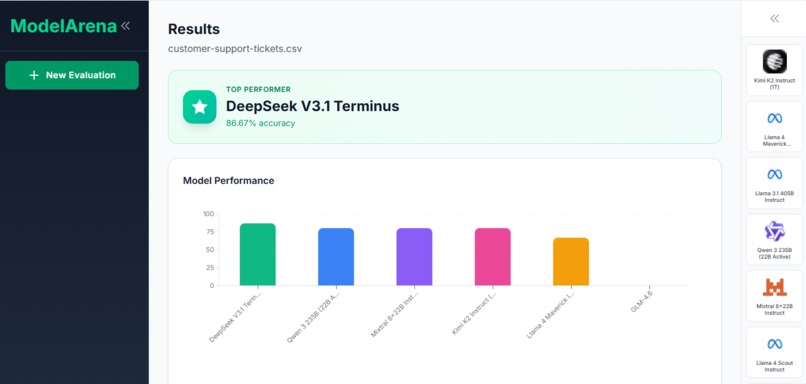
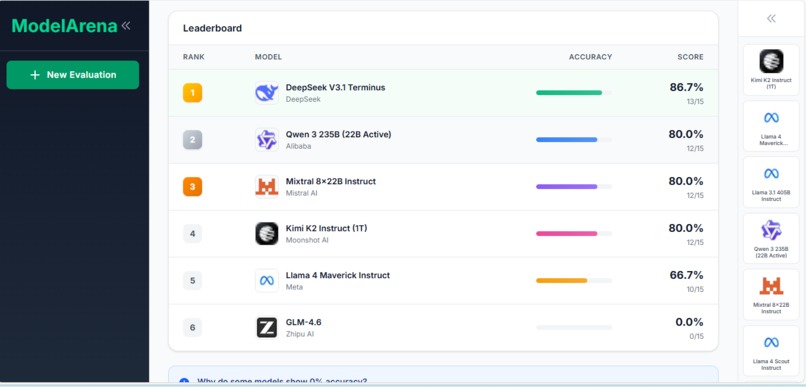
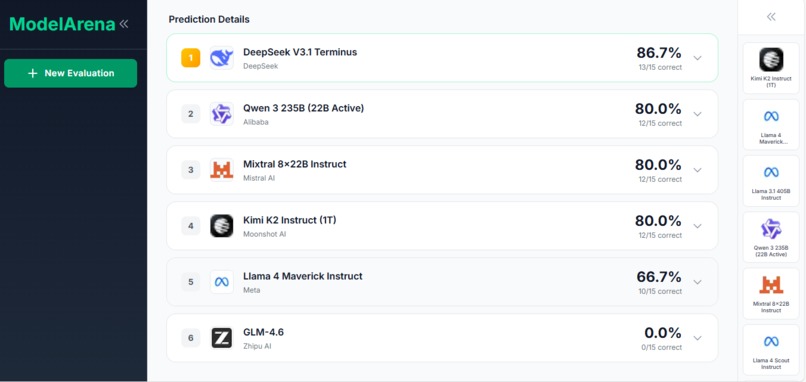
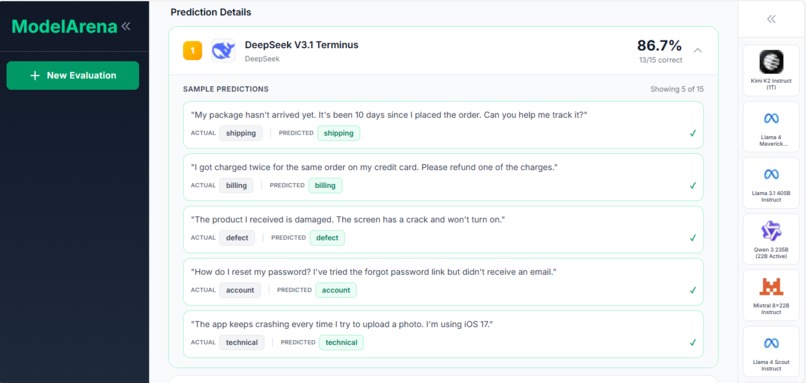
What it does
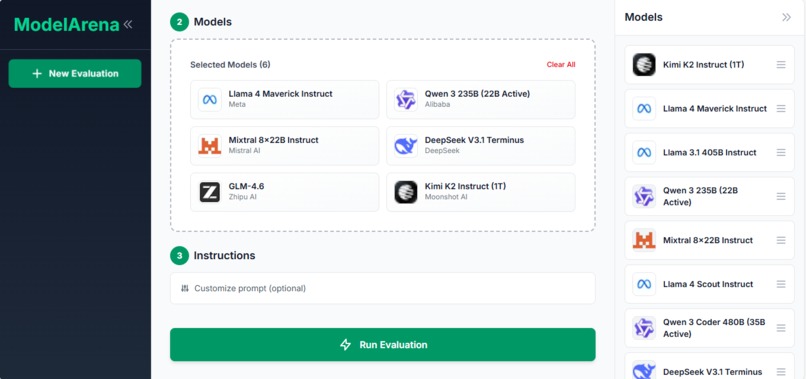
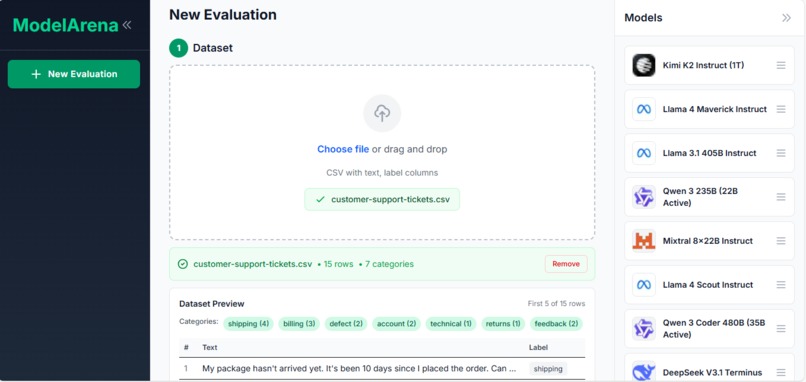
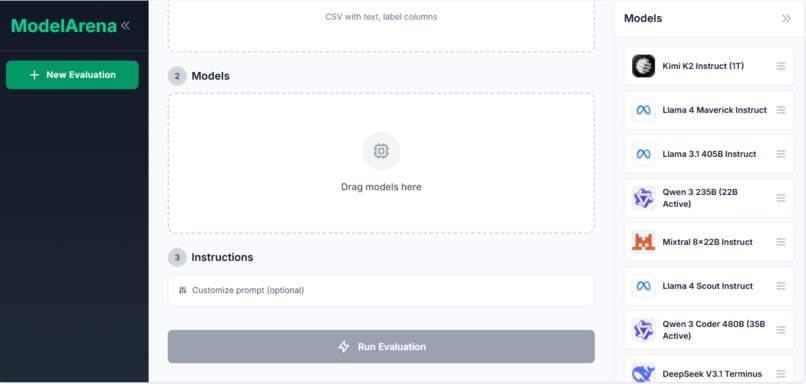
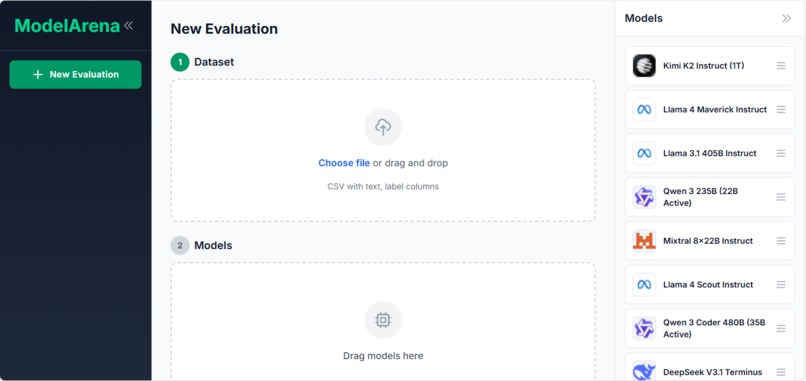
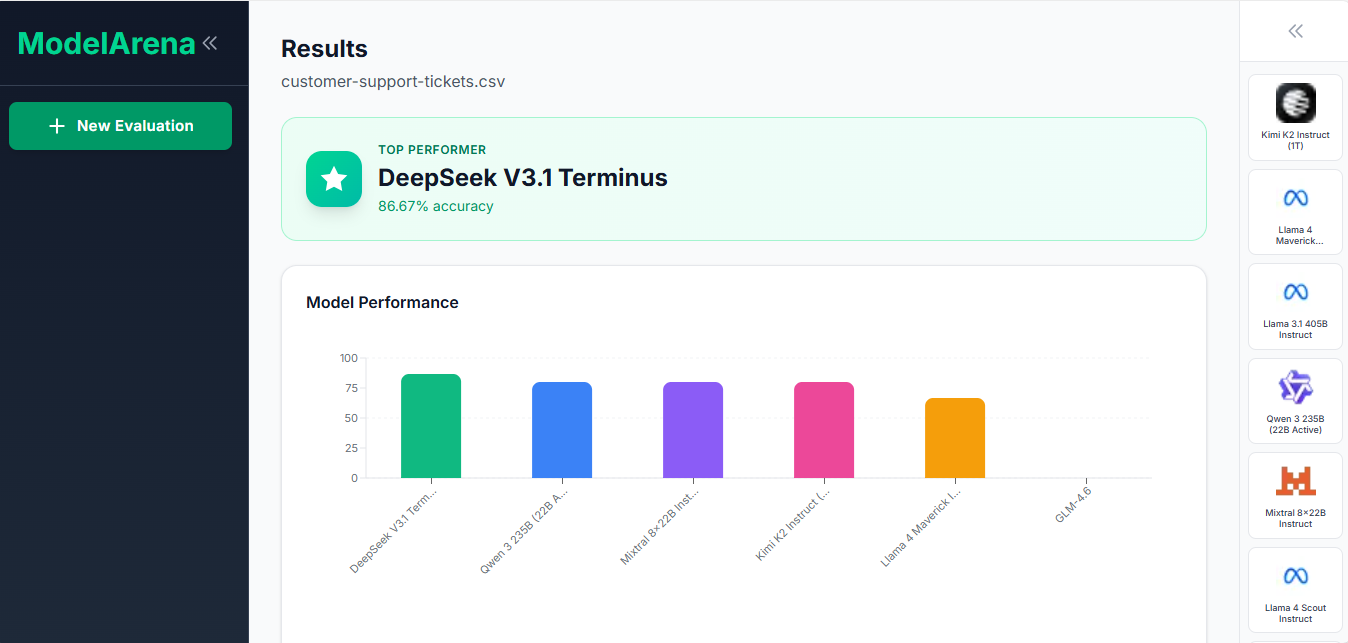
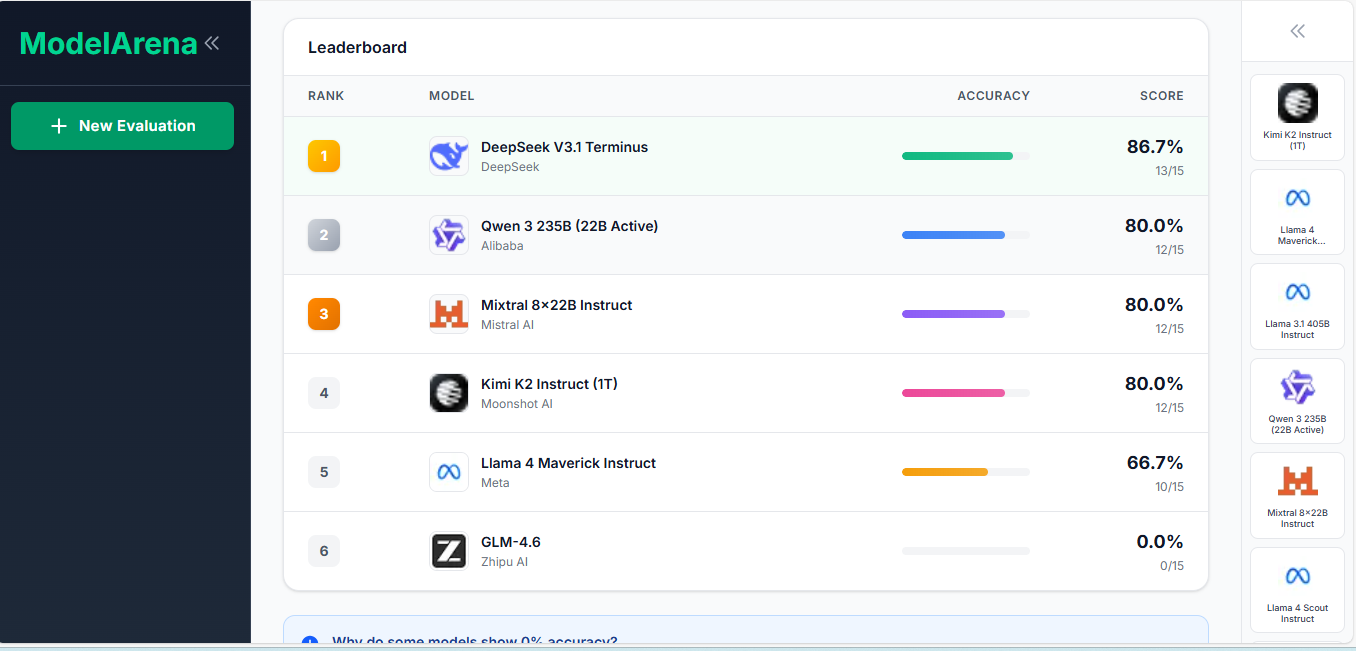
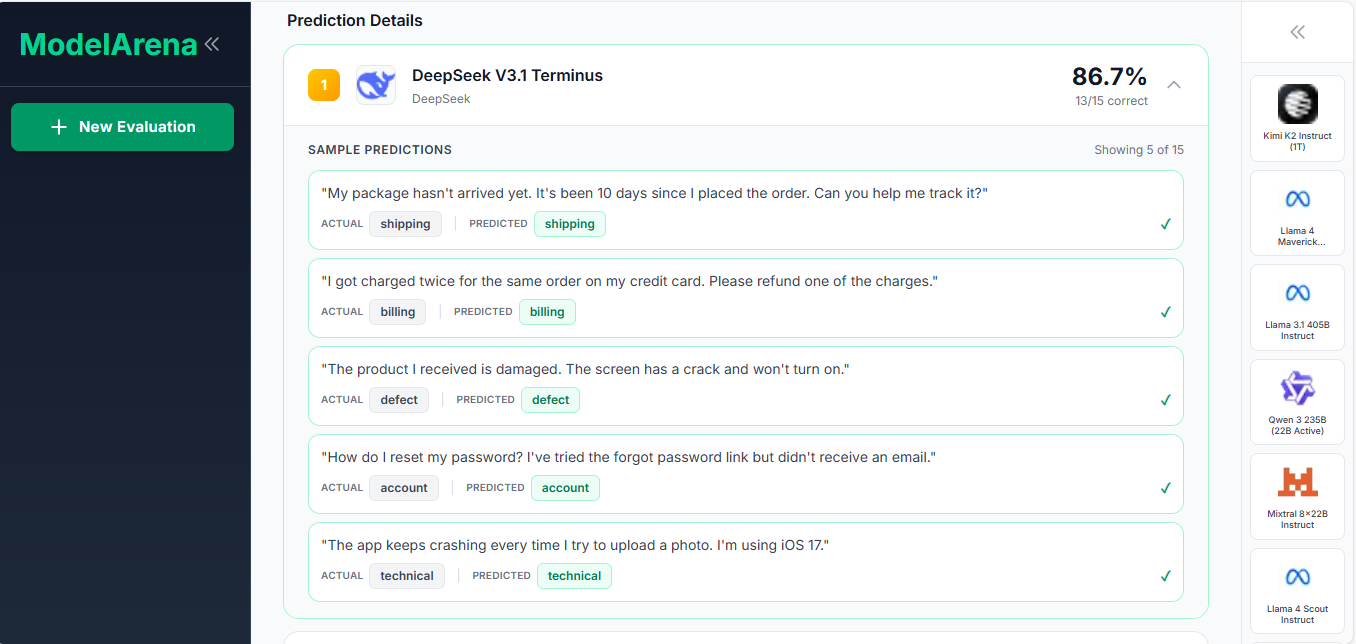
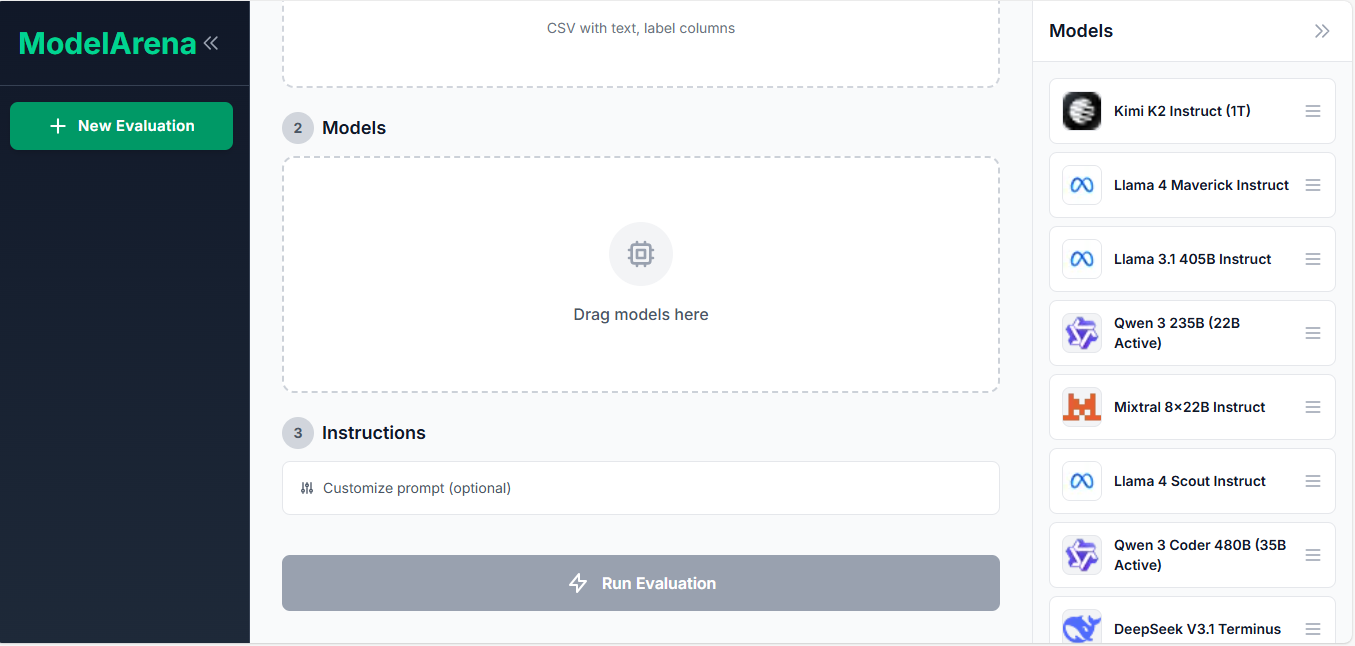
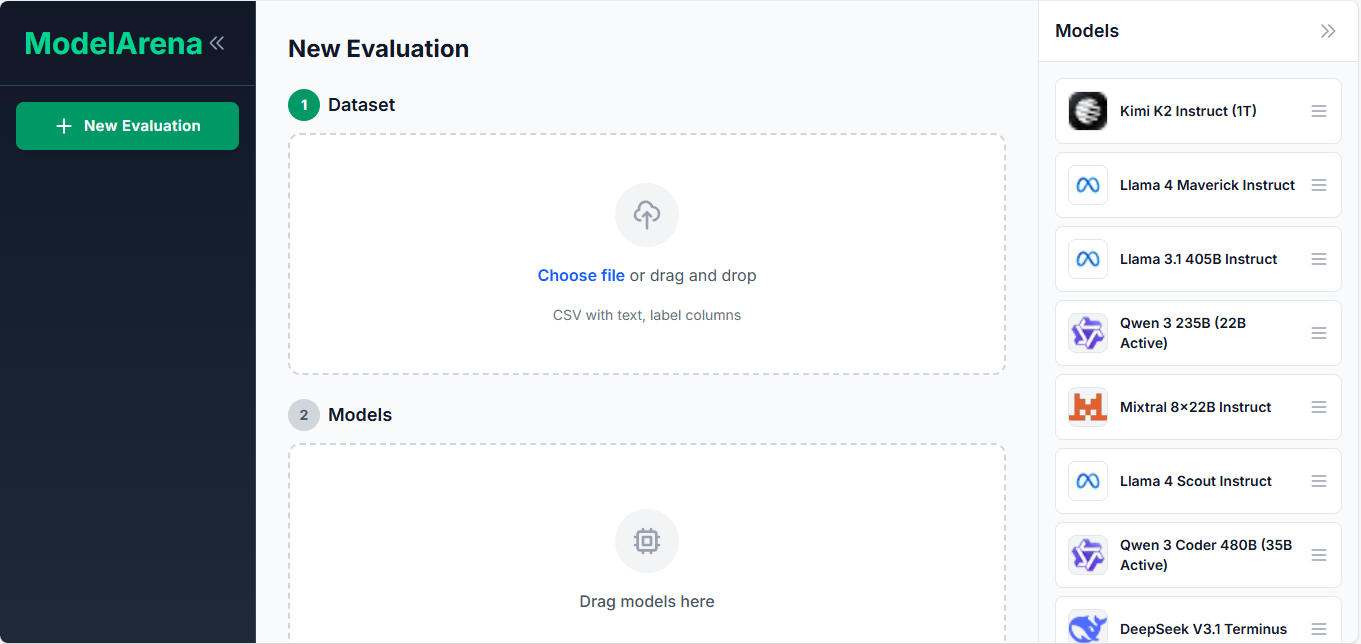
ModelArena evaluates LLM models on your own dataset. Upload a CSV file with labeled data, select models to test (Llama, Mistral, Gemma, Qwen, etc.), run the evaluation, and view ranked results with accuracy scores and prediction details. This gives you objective metrics based on your specific data instead of relying on vendor claims or public benchmarks.
Built With
- next.js
- react
- tailwindcss
- typescript



Log in or sign up for Devpost to join the conversation.