-
landing page
-
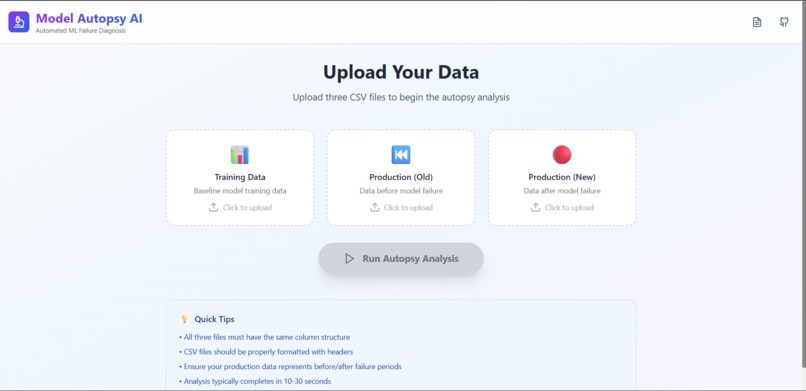
upload page
-
analysis loading page
-
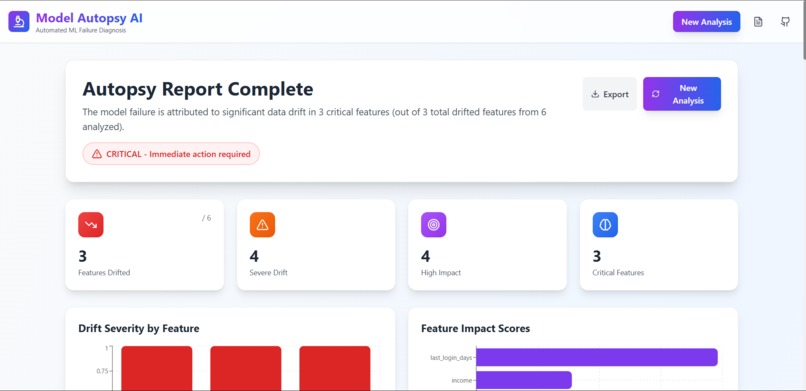
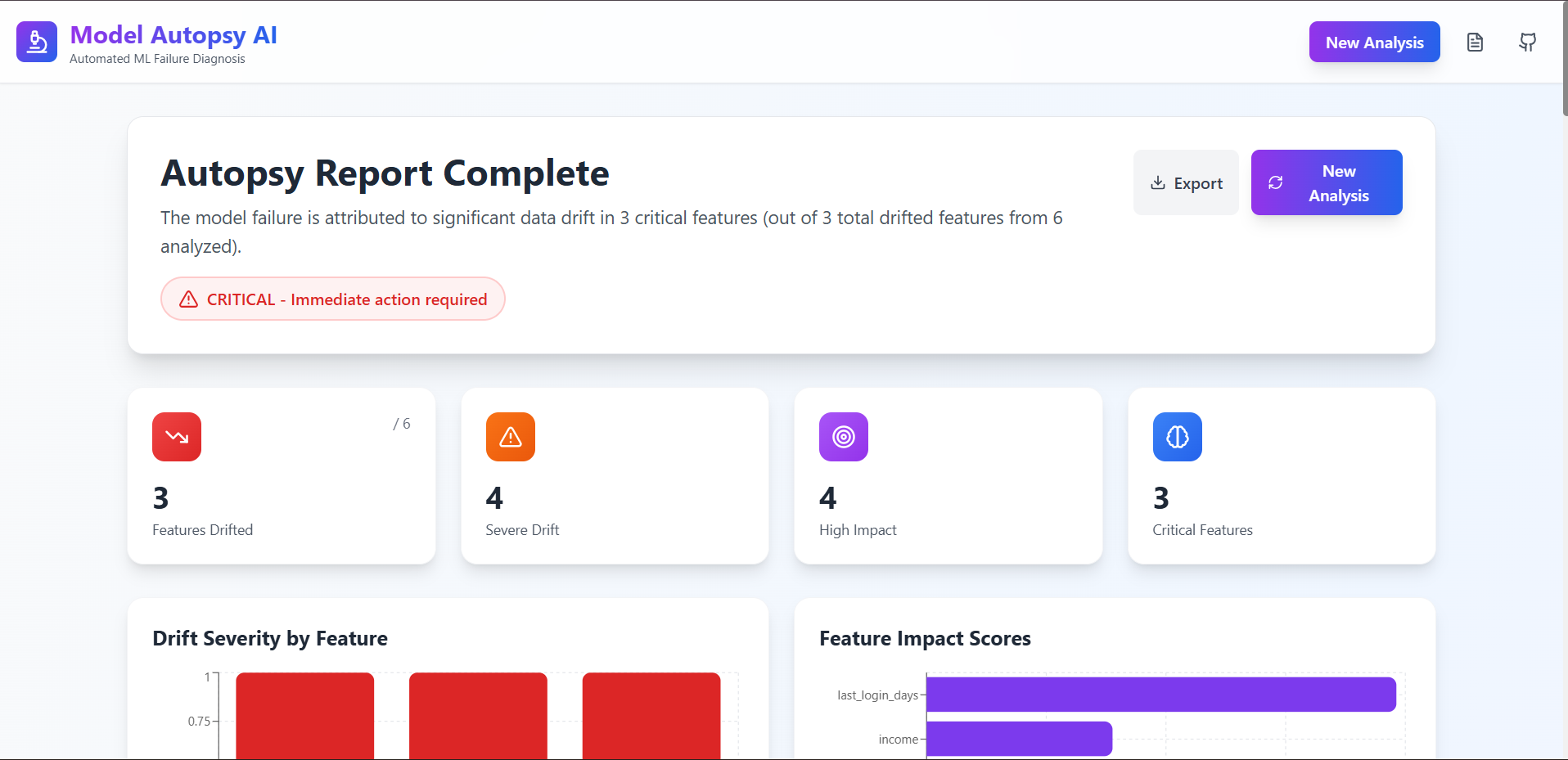
report.1 (over view)
-
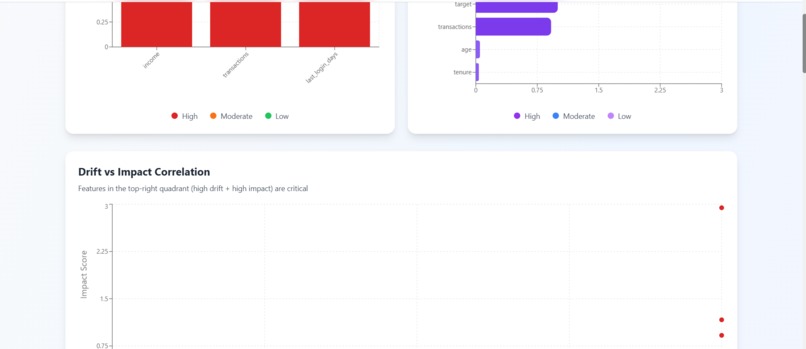
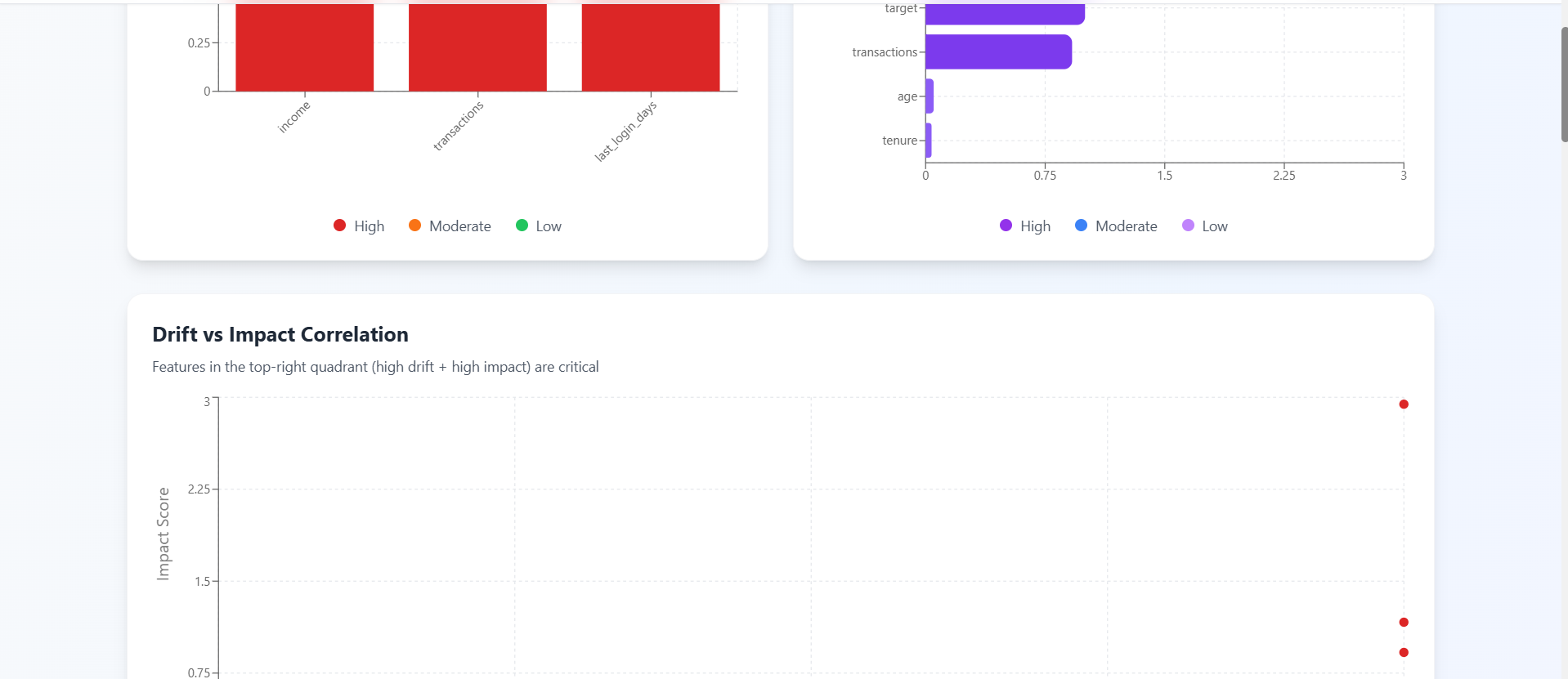
report.2 (graphs)
-
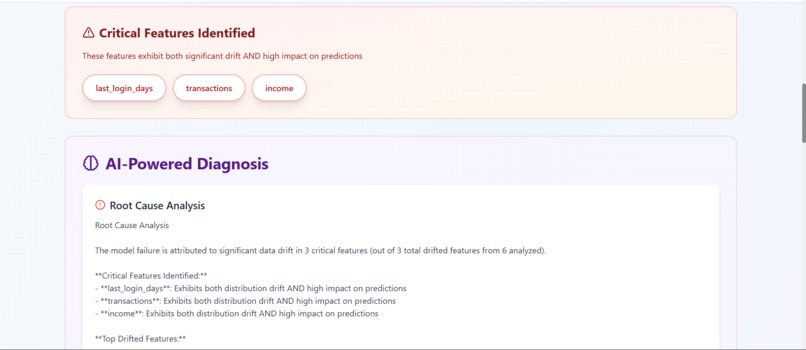
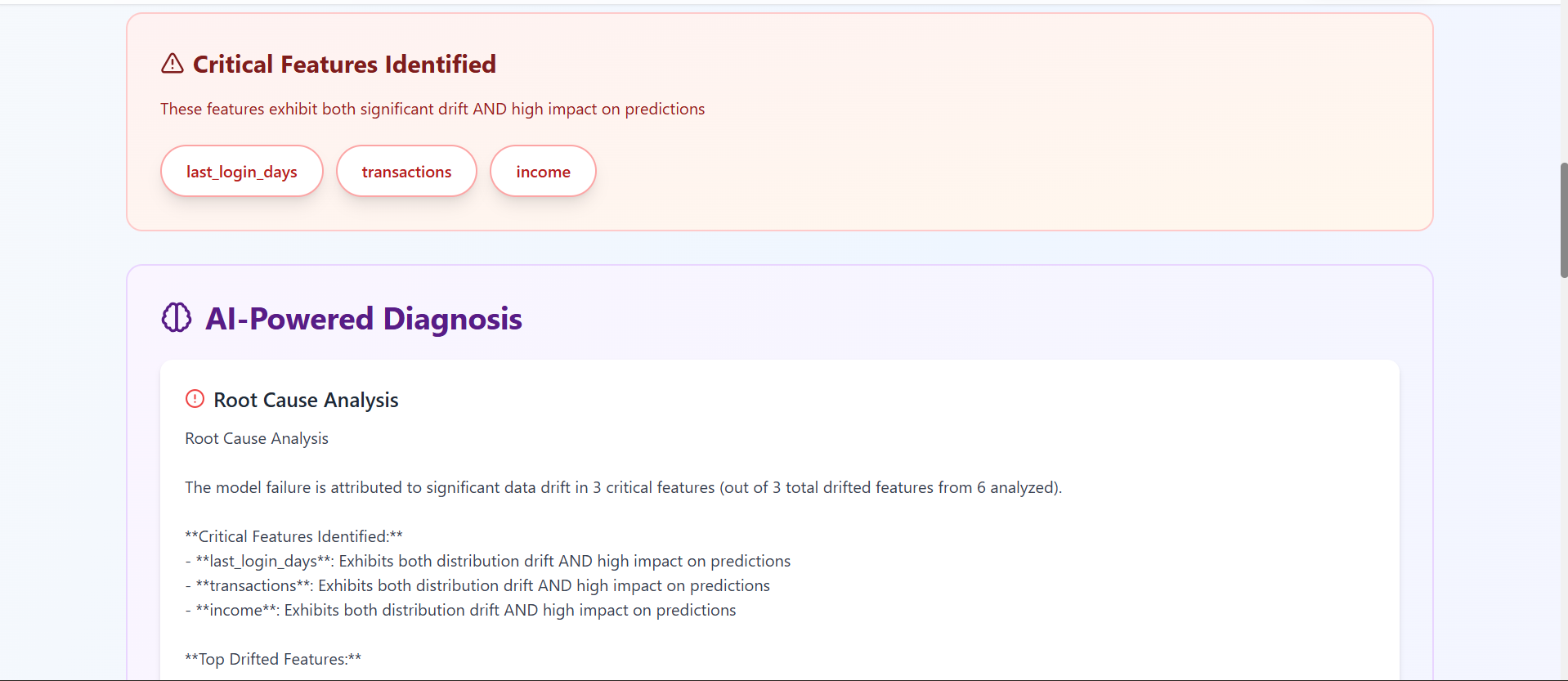
report.3 (critical features identifed)
-
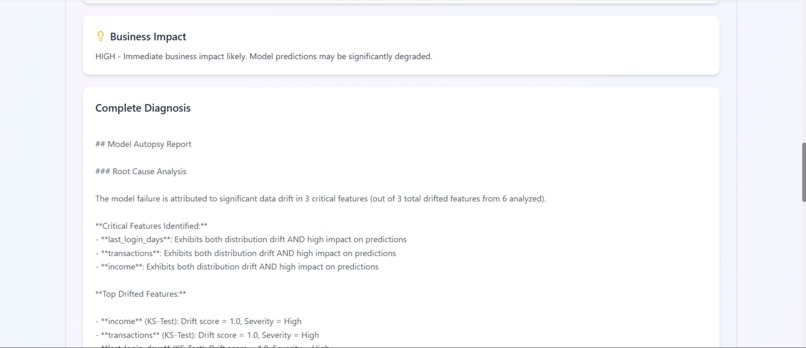
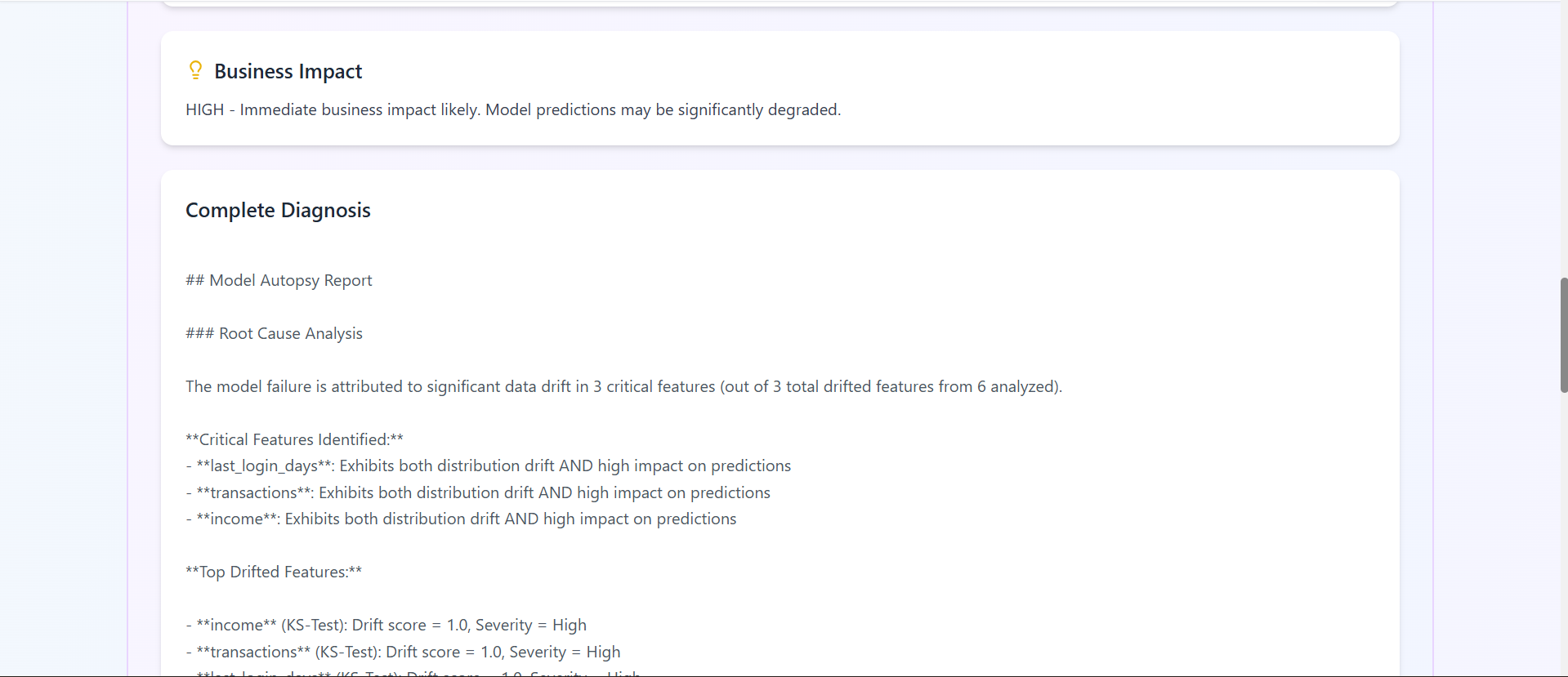
report.4 (business impact)
-

report.5 (complete diagnosis)
-
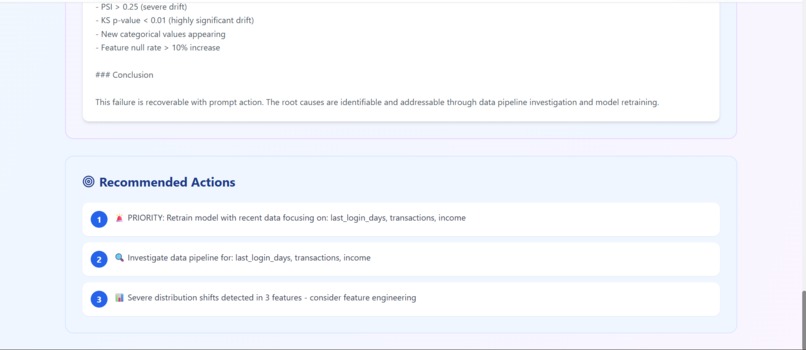
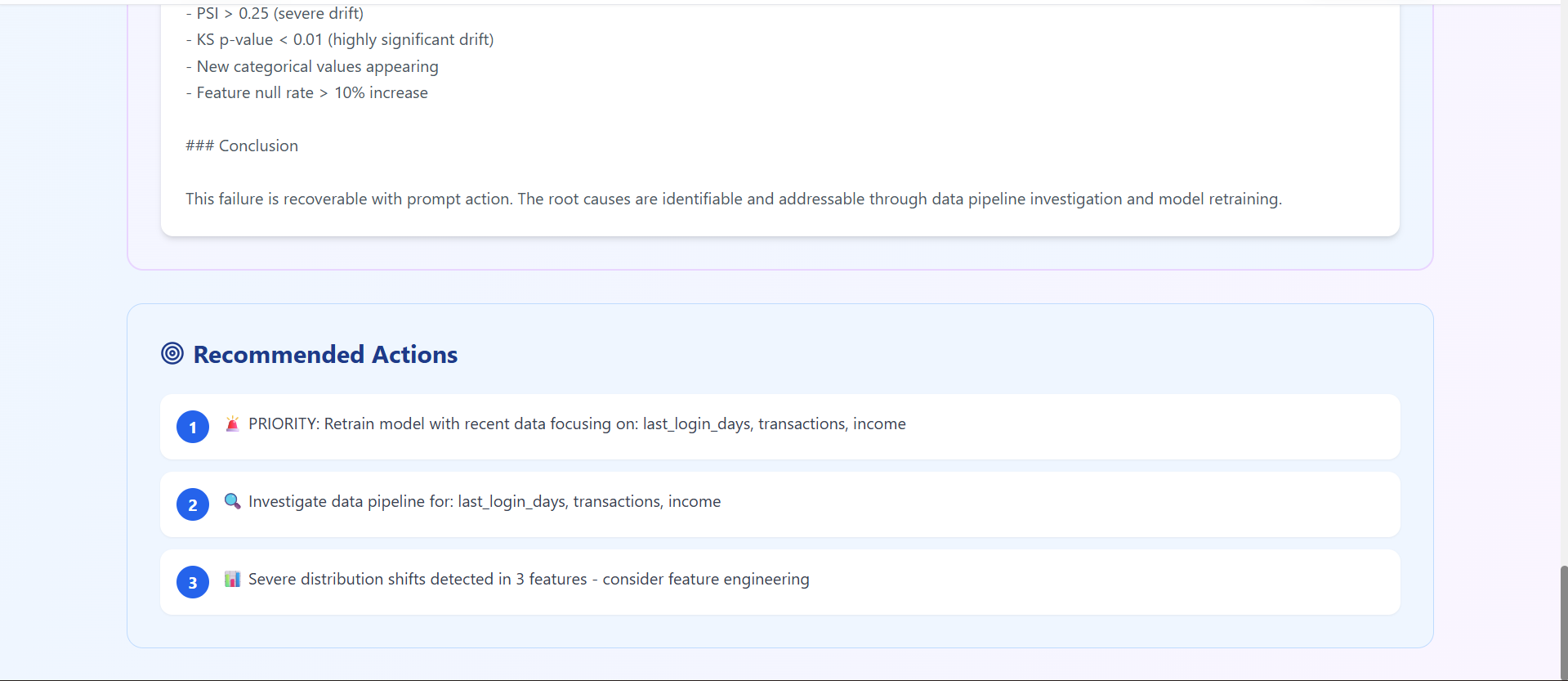
report.6 (recommended action)

Inspiration
In real-world machine learning systems, models rarely fail because the algorithm is poorly designed. More often, failures happen because data silently changes over time — user behavior evolves, distributions drift, or upstream pipelines introduce subtle inconsistencies.
We observed that most existing tools focus on detecting performance drops, but they stop there. When a model fails, engineers are still left manually investigating questions like:
Which feature changed?
When did it change?
Did that change actually cause the failure?
This gap between failure detection and failure diagnosis inspired us to build Model Autopsy AI — a system that explains why a model failed, not just that it failed.
What it does
Model Autopsy AI performs an automated post-mortem analysis of machine learning models.
Given training data, pre-failure production data, and post-failure production data, the system:
-Detects statistical data drift
-Measures feature impact using explainable AI (SHAP)
-Reconstructs a failure timeline
-Identifies critical root-cause features
-Generates a human-readable diagnostic report with actionable recommendations
Instead of dashboards and alerts, it provides clear answers about what broke the model.
How I built it
The system is built as a modular ML diagnostics pipeline.
-We validate schemas across all datasets to prevent silent pipeline errors.
-For drift detection, we use the Kolmogorov–Smirnov (KS) test for numerical features, flagging statistically significant distribution changes.
-To measure impact, we use SHAP (SHapley Additive exPlanations) to quantify how important each feature is to the model’s predictions.
-We compare SHAP importance before and after drift to compute importance shift.
-We combine drift severity, importance shift, and temporal precedence into a Root Cause Confidence Score that ranks features by likelihood of causing failure.
-Finally, we generate an AI-powered diagnostic report that translates technical signals into clear explanations and recommended actions.
Challenges I ran into
-Distinguishing harmless drift from drift that actually causes model failure
-Avoiding false positives when many features change slightly
-Combining statistical tests with explainability in a meaningful way
-Ensuring consistent schemas across multiple uploaded datasets
-Translating complex ML signals into explanations that are understandable and actionable
These challenges pushed us to think beyond metrics and focus on causal reasoning.
Accomplishments that I'm proud of
-Designing a root-cause scoring system instead of simple drift alerts
-Successfully combining statistical drift detection with SHAP explainability
-Producing a report that resembles a real ML incident post-mortem
-Building a clean, intuitive UI that guides users through diagnosis
-Creating a solution that mirrors real production MLOps problems
What I learned
-Data drift alone does not imply model failure
-Explainability is essential for trustworthy ML systems
-Temporal reasoning helps establish causality, not just correlation
-Clear communication and storytelling are as important as technical depth
-Production ML problems are fundamentally diagnostic, not just predictive
This project significantly deepened our understanding of MLOps, explainable AI, and real-world ML reliability.
What's next for Model Autopsy AI
In the future, we plan to extend Model Autopsy AI with:
-Real-time drift monitoring
-Automated retraining triggers
-Multi-model and version comparison
-Integration with MLOps platforms and CI/CD pipelines
-Support for categorical features and large-scale datasets
Our long-term vision is to make model failure diagnosis a standard part of every ML deployment.

Log in or sign up for Devpost to join the conversation.