-
-
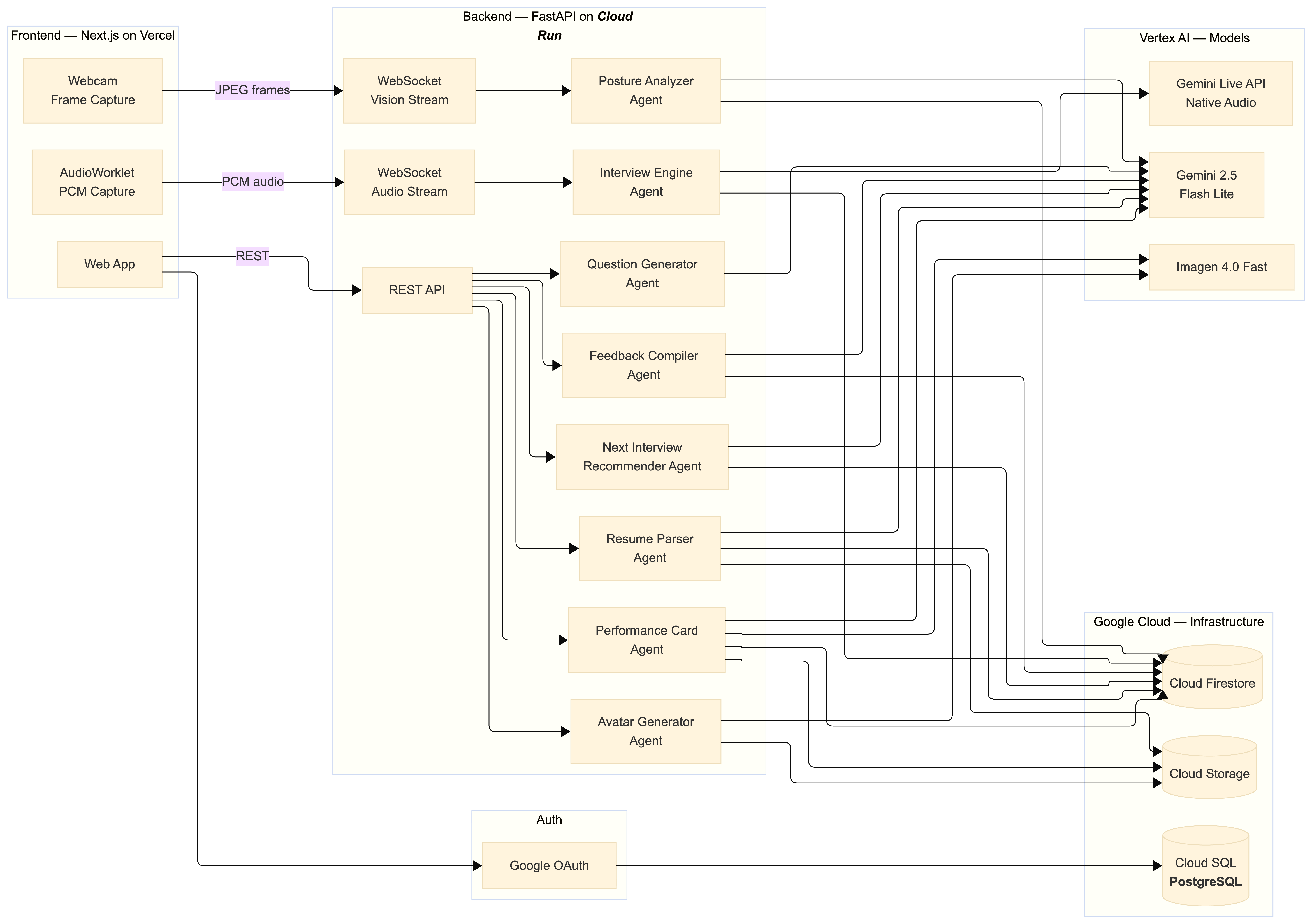
Architecture diagram
-
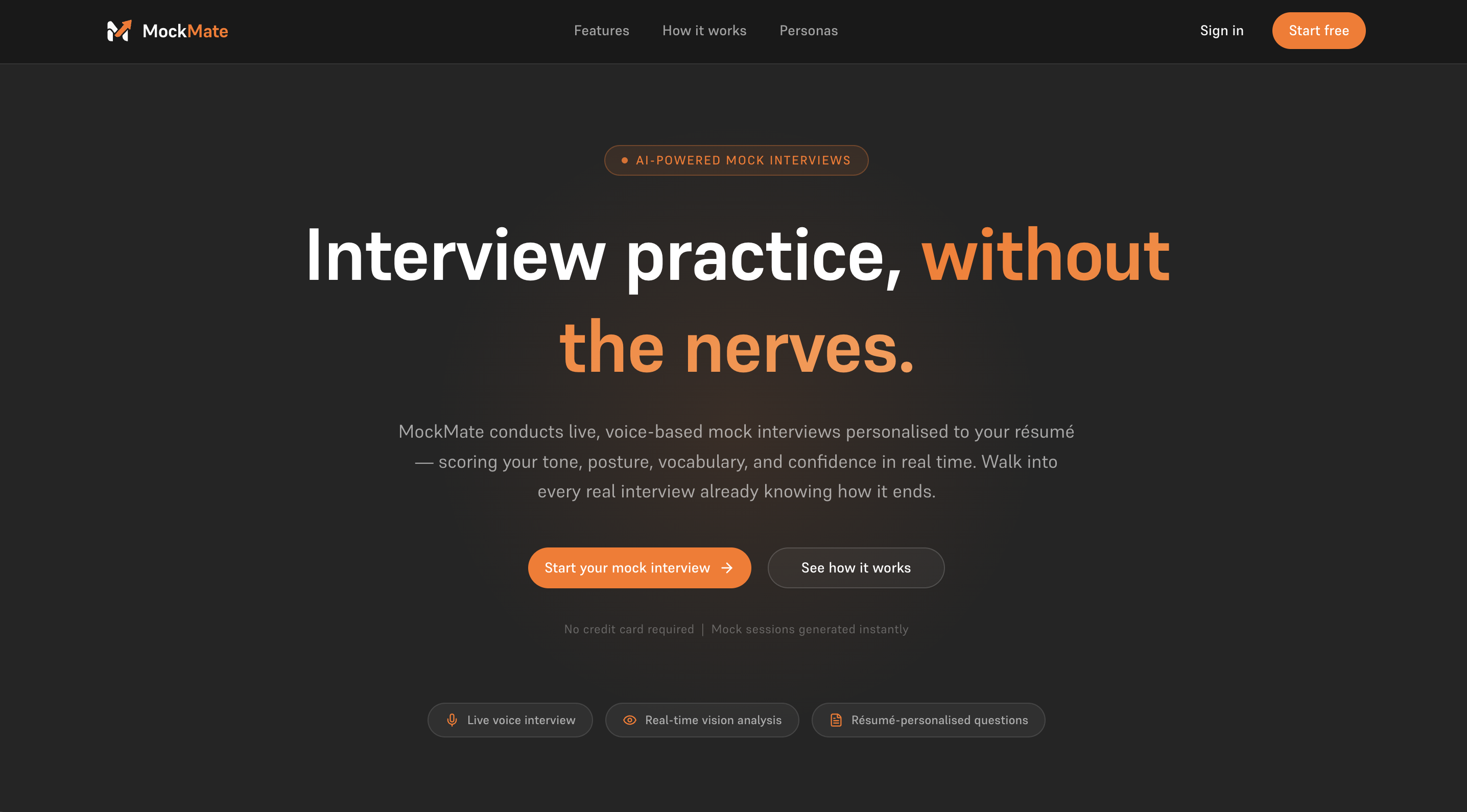
Landing page
-
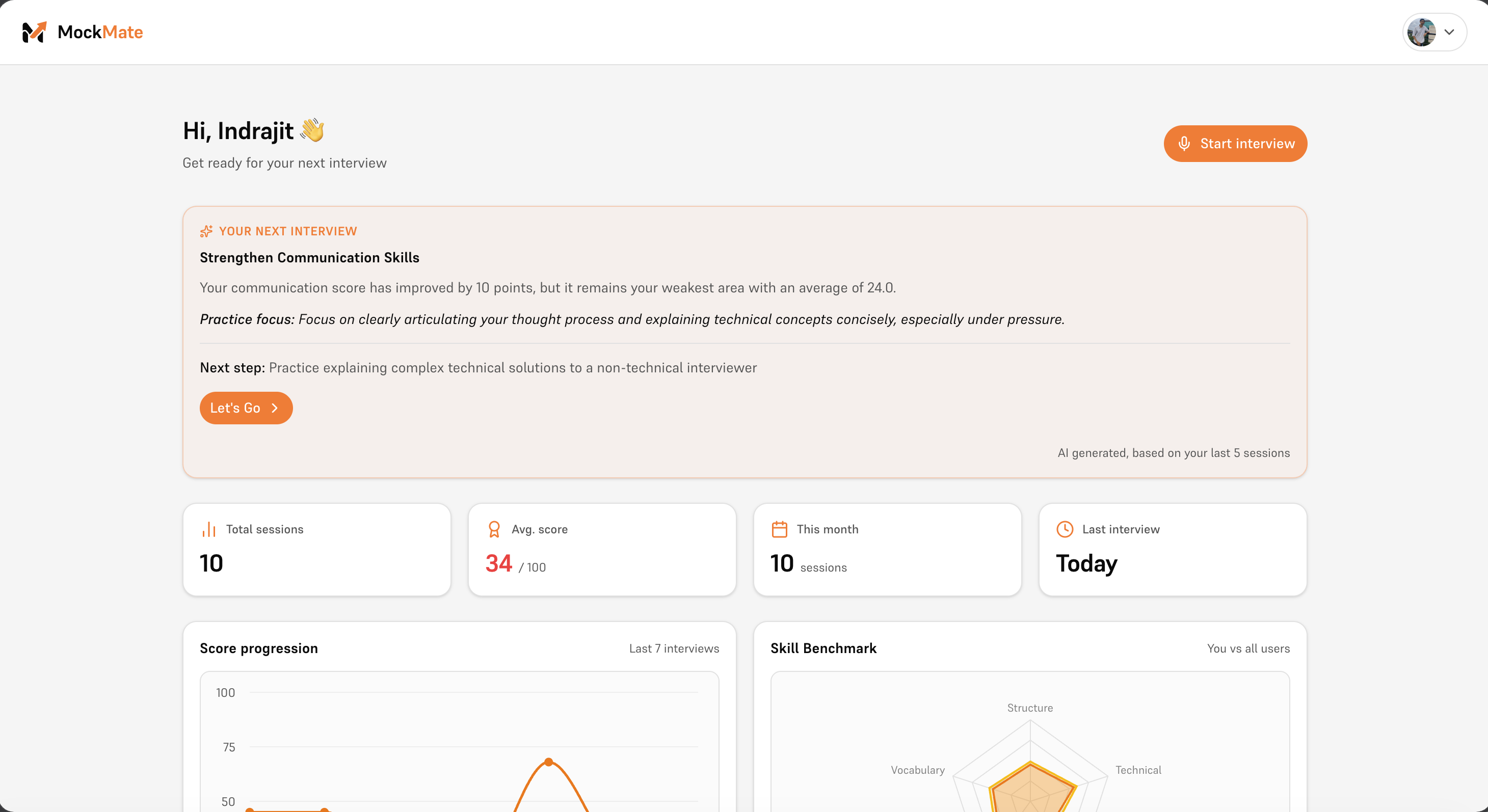
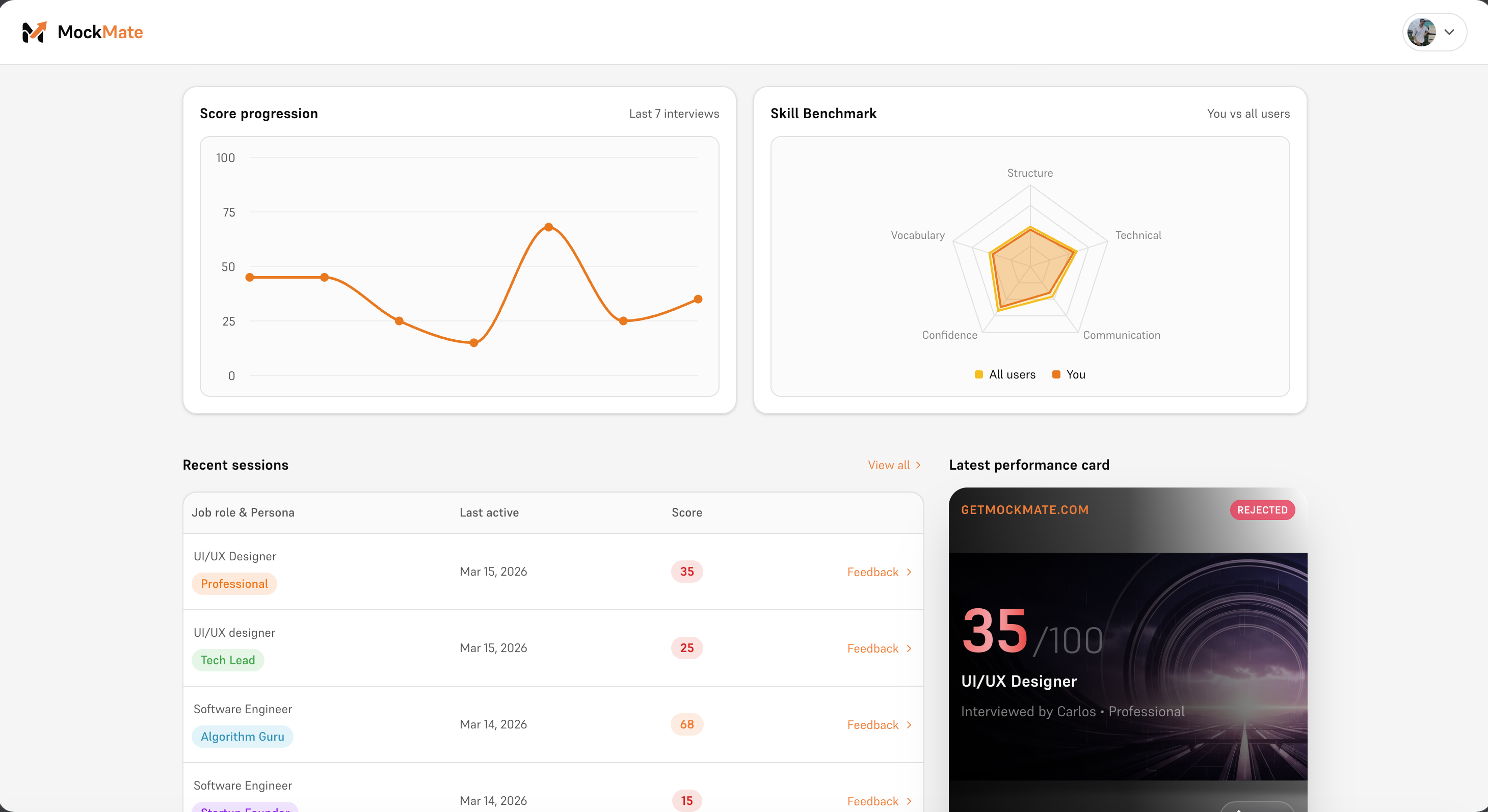
User dashboard (1/2)
-
User dashboard (2/2)
-
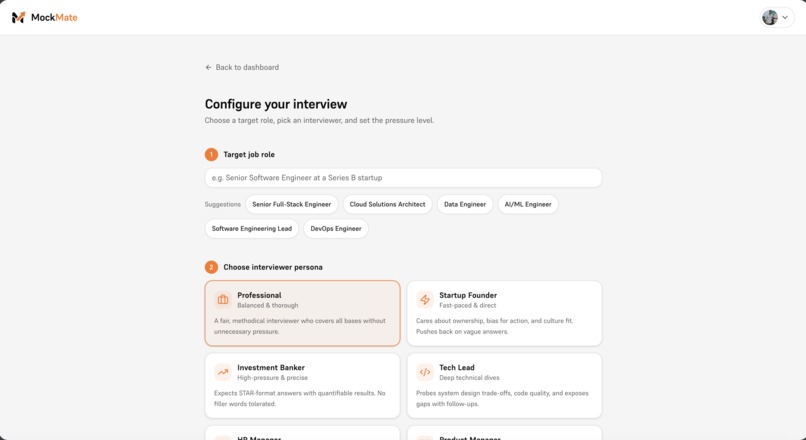
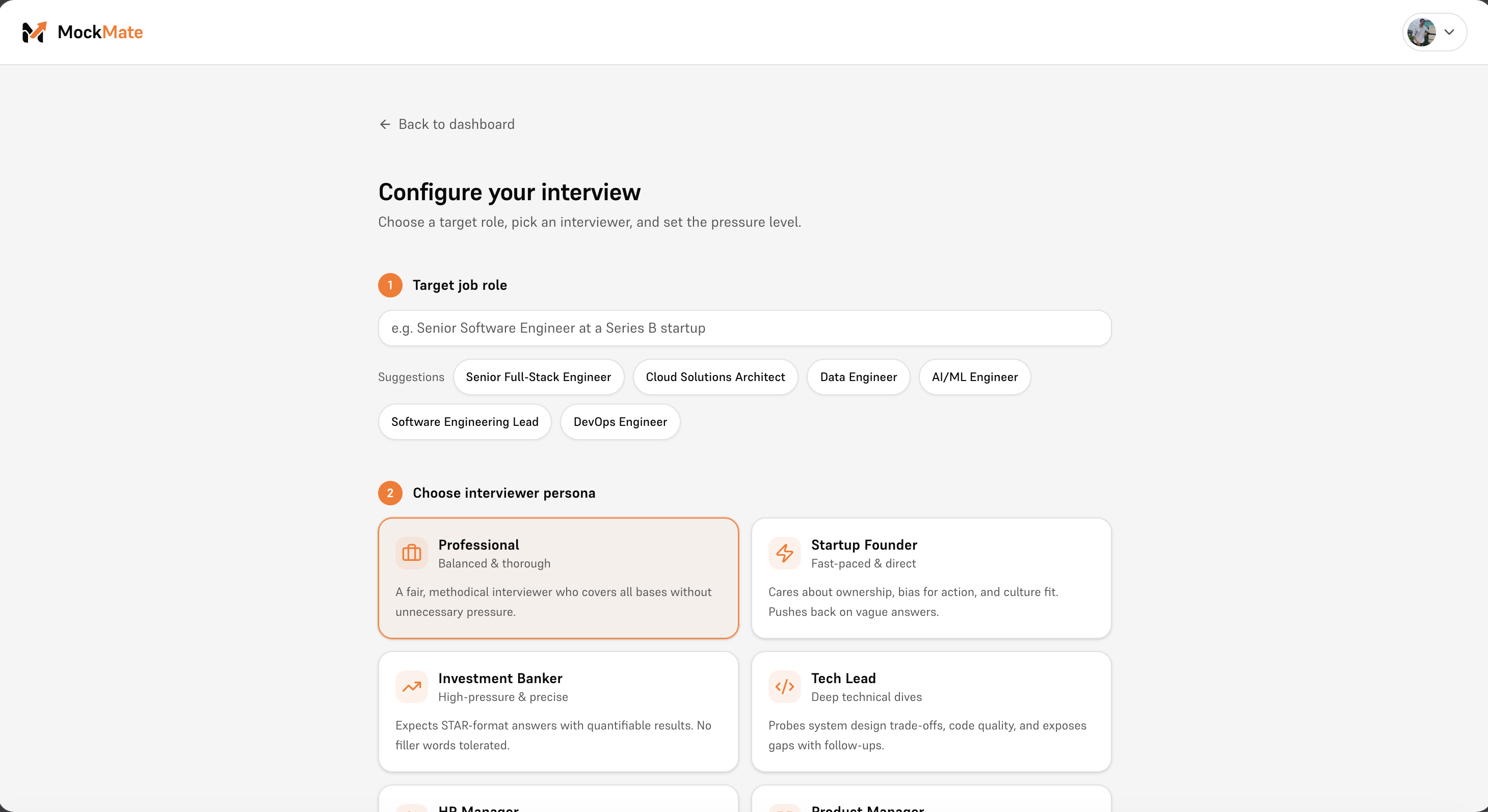
Interview setup
-
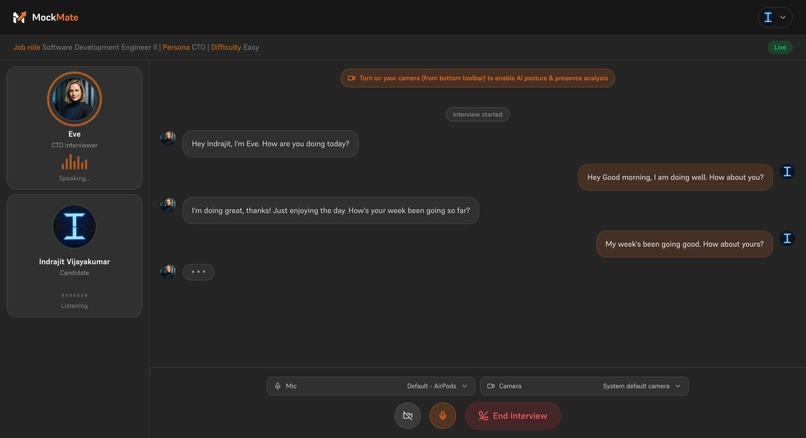
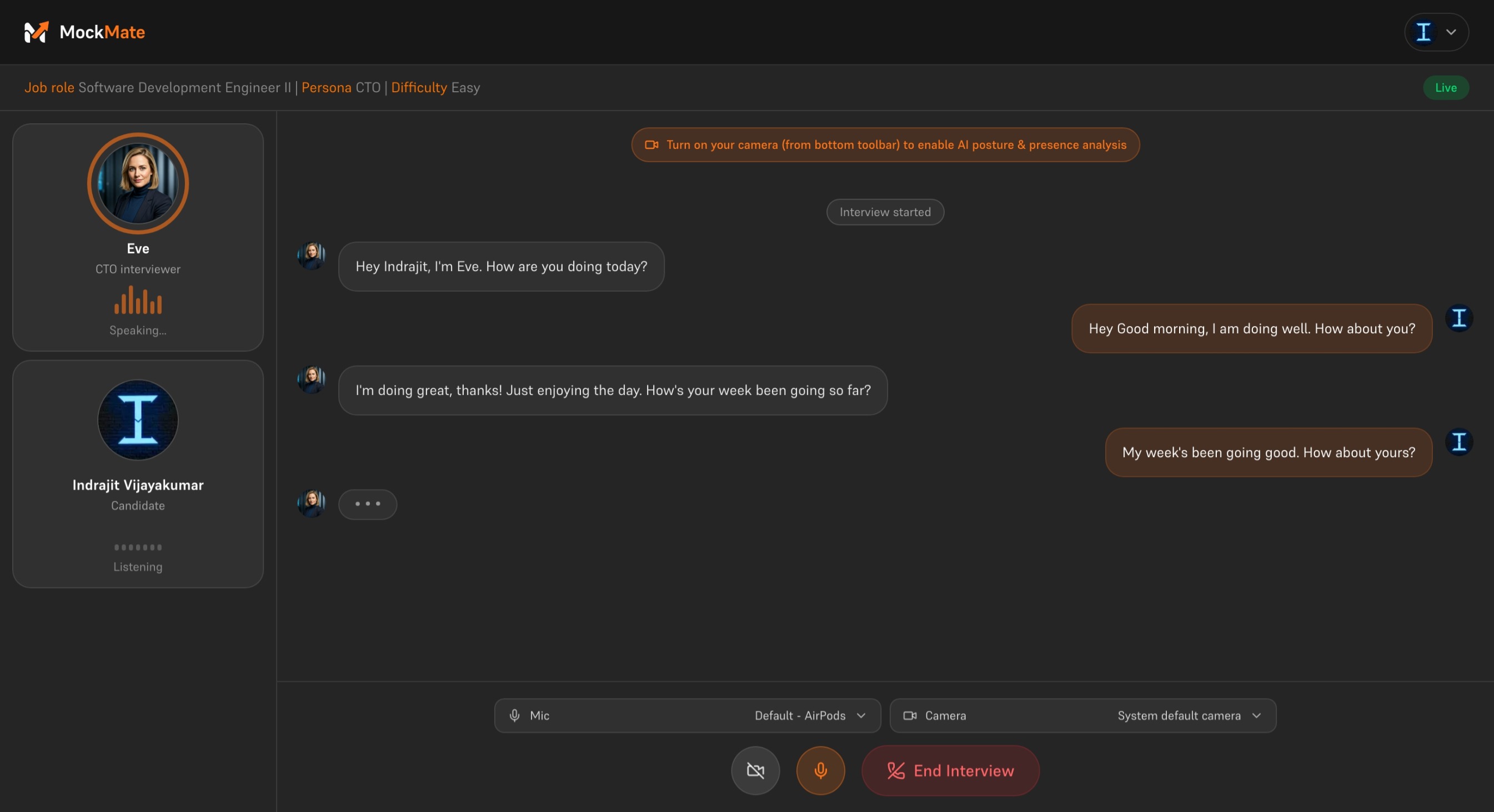
Live interview
-
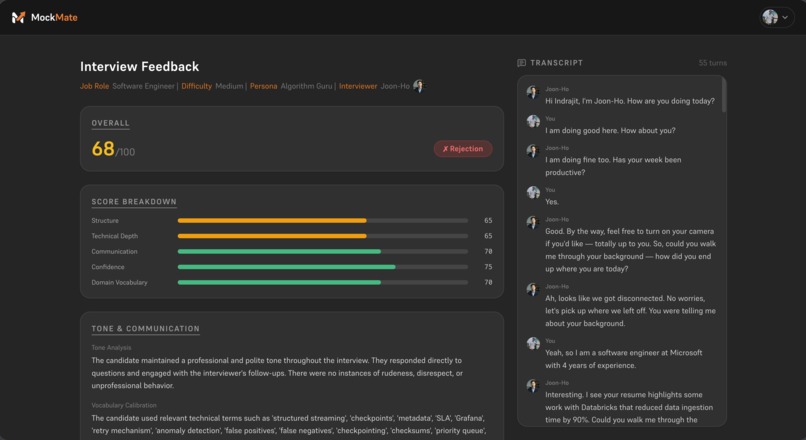
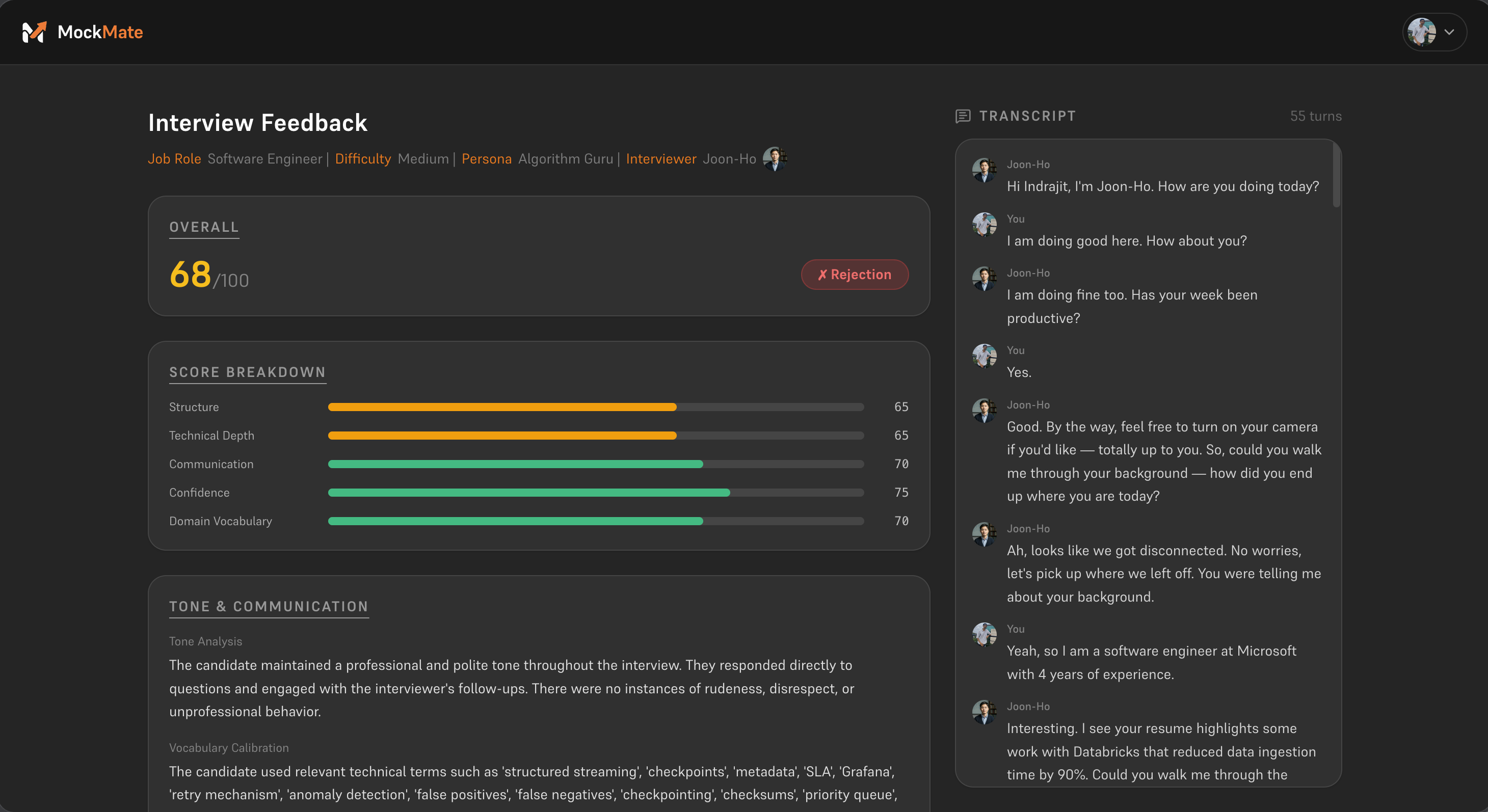
Interview feedback
-
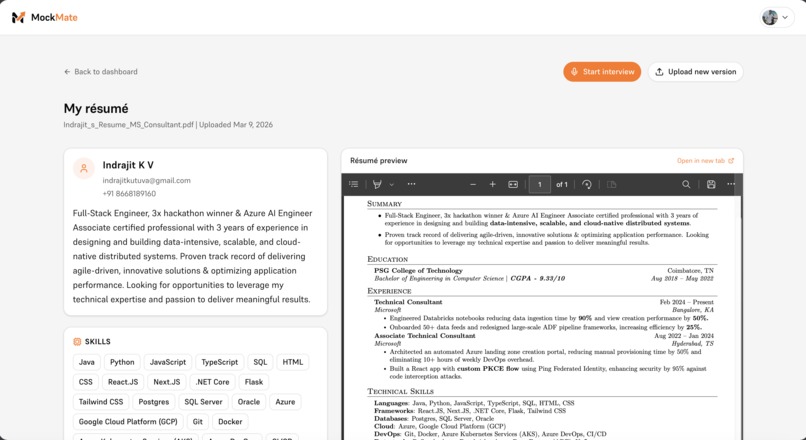
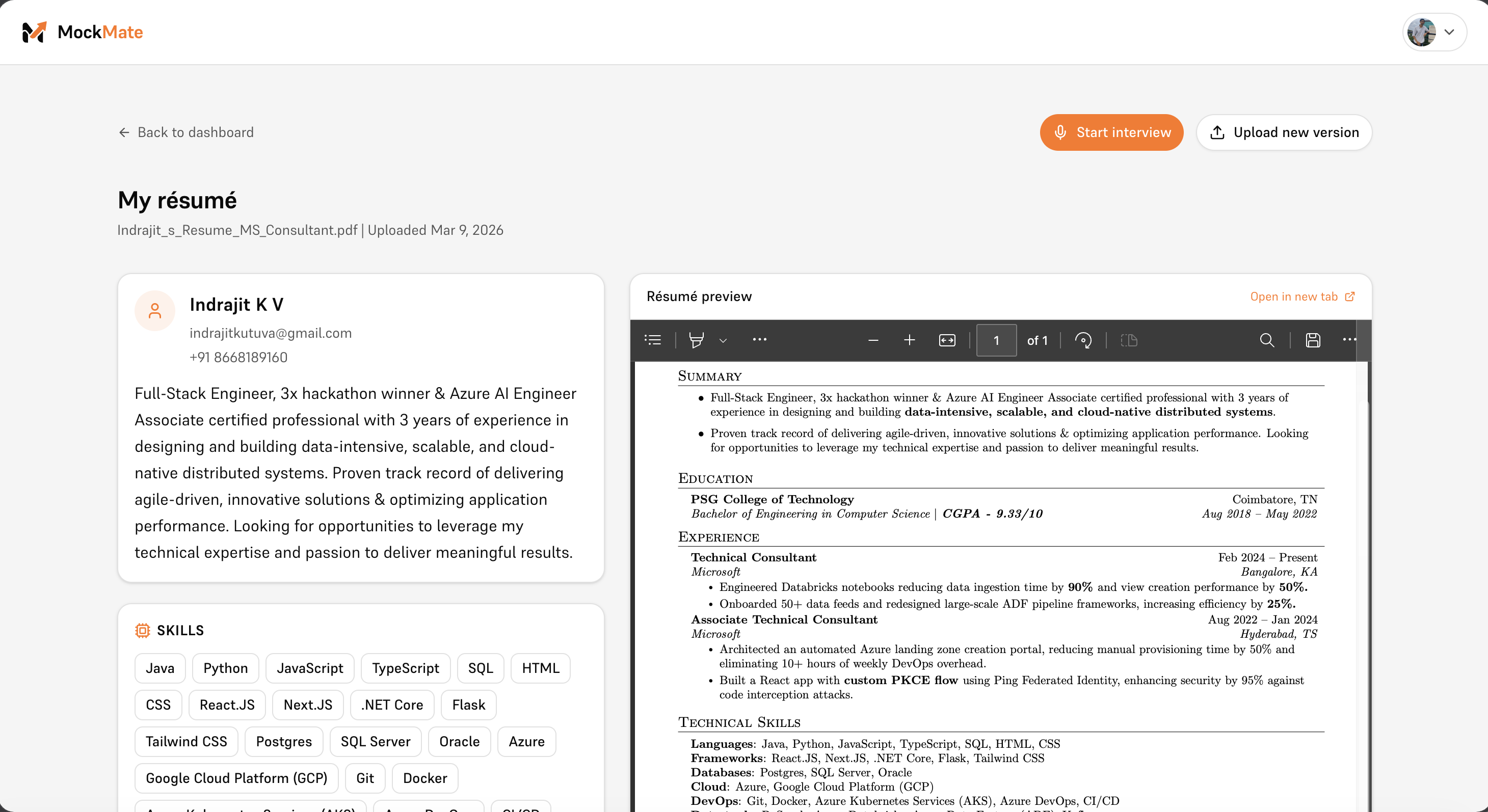
Your résumé
-
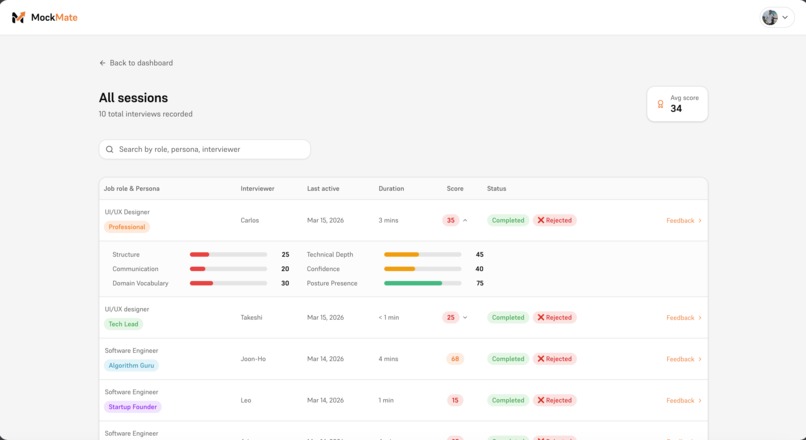
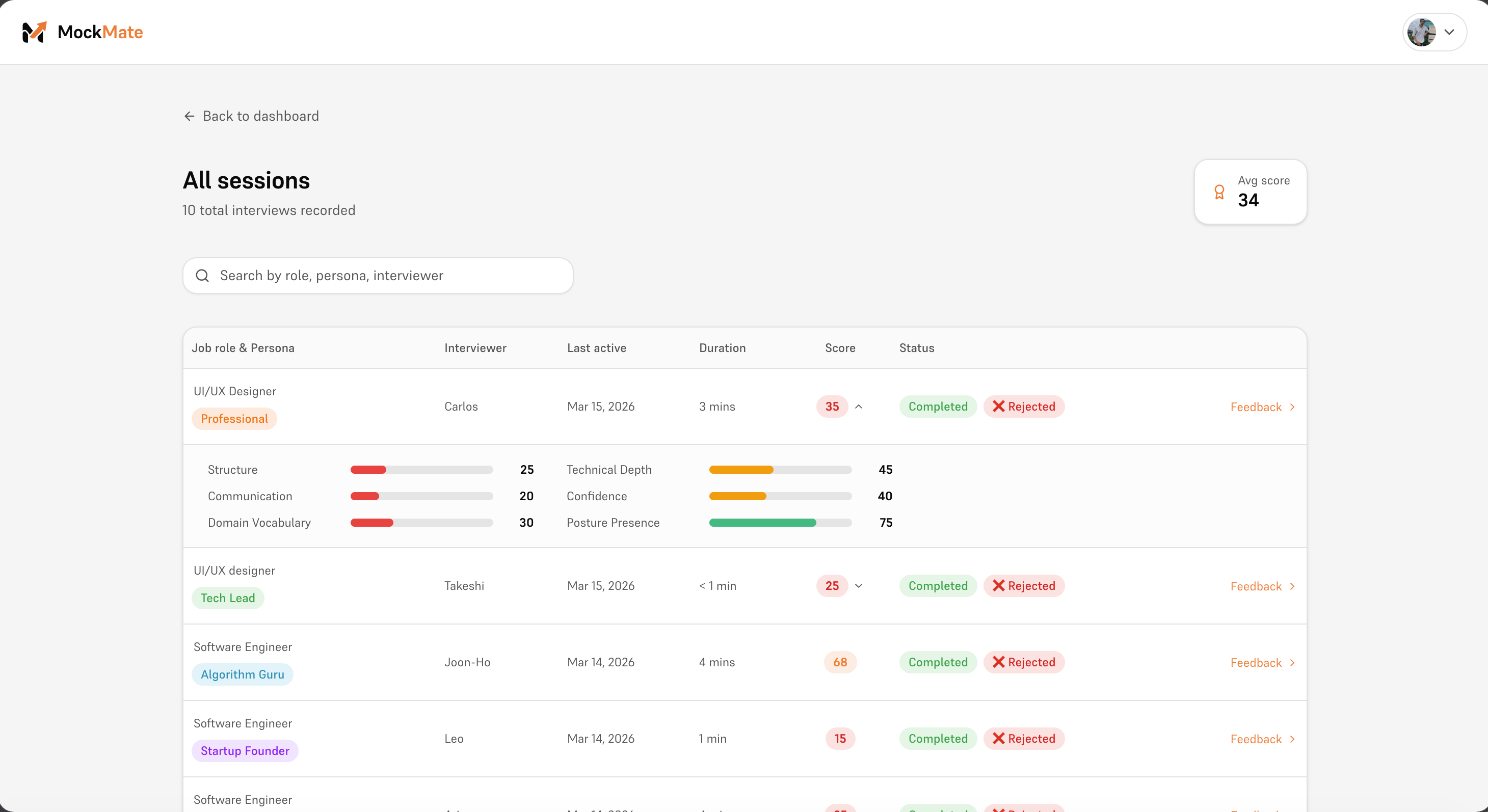
Your sessions
-

MockMate Logo

Inspiration
A few months ago, I was deep in interview prep myself. I'd grind LeetCode, read system design blogs, rehearse STAR stories in my head — but the moment I got on an actual call, everything fell apart. My answers rambled. My pacing was off. I'd freeze on follow-ups I hadn't anticipated. The gap between knowing the material and performing under pressure was massive, and nothing I was using helped bridge it. Mock interview platforms felt like flashcard apps with a microphone icon — type a question, read an answer, repeat. Paid coaching was too expensive. I just wanted to sit down and talk to someone who'd push back, ask "why?", and make me feel the pressure — on my own time, as many times as I needed.
That frustration is what sparked MockMate. Real interviews are spoken, unpredictable, and deeply personal. I wanted to break out of the text-box paradigm entirely. I wanted to build an AI interviewer you actually sit across from, one that watches your body language, listens to your voice in real time, and responds like a real person would.
The Gemini Live API made that possible for the first time: true bidirectional and adaptive voice conversation backed by multimodal understanding. That was the spark — what if preparing for an interview felt exactly like being in one?
What it does
MockMate is an AI-powered mock interview platform that conducts real, adaptive interview sessions using voice, vision, and résumé-personalized question generation. It analyzes not just what you say but how you say it — scoring your tone, posture, vocabulary, and confidence in real time. At the end of every session, you receive a detailed feedback report and a mock hiring decision letter, so you walk into every real interview already knowing how it ends.
- 📄 Upload your résumé → pick a role and difficulty → step into a live conversation with a personalized AI interviewer
- 🎭 13 distinct interviewer personas — each with their own voice, pacing, accent, warmth, and questioning style — from a warm HR manager to an aggressive investment banker
- 🎙️ Entirely voice-driven — the agent asks context-aware follow-up questions, handles follow-ups naturally, and adapts in real time
- 🧠 8 specialized agents orchestrate every session:
- 📄 ResumeParserAgent — extracts structured skills and experience from your résumé
- ❓ QuestionGeneratorAgent — crafts a tailored question bank based on selected role, persona and difficulty
- 🎨 InterviewerAvatarAgent — generates a unique avatar for the interviewer using Imagen 4.0 Fast
- 🗣️ InterviewEngineAgent — drives the live voice conversation via the Gemini Live API, managing pacing, follow-ups, and graceful closings
- 👁️ PostureAnalyzerAgent — evaluates body language from periodic webcam snapshots during the interview
- 📊 FeedbackCompilerAgent — produces a scored competency report with a role- and difficulty-aware hiring decision (offer or rejection) and a reasoned explanation
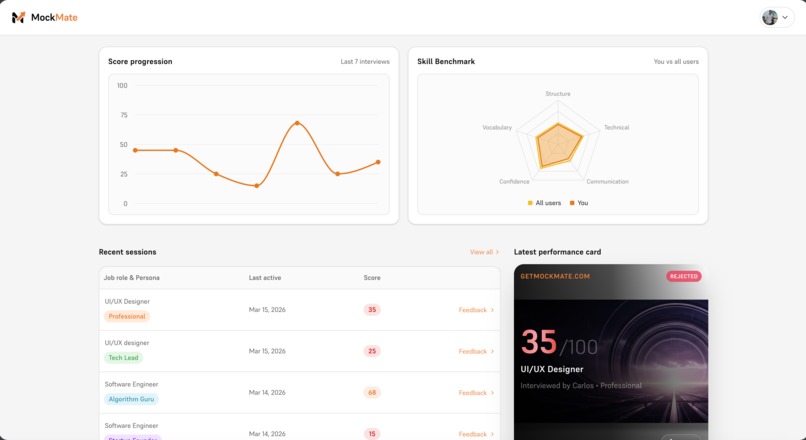
- 🏆 PerformanceCardAgent — renders a shareable visual performance summary card with an artistic background
- 🧭 NextInterviewRecommenderAgent — suggests what to practice next based on identified gaps
- ✅ The result: a single, end-to-end session from "upload résumé" to "here's your feedback letter" — all through voice, vision, and live interaction. Not a single text box in the loop. 🚫⌨️
How I built it
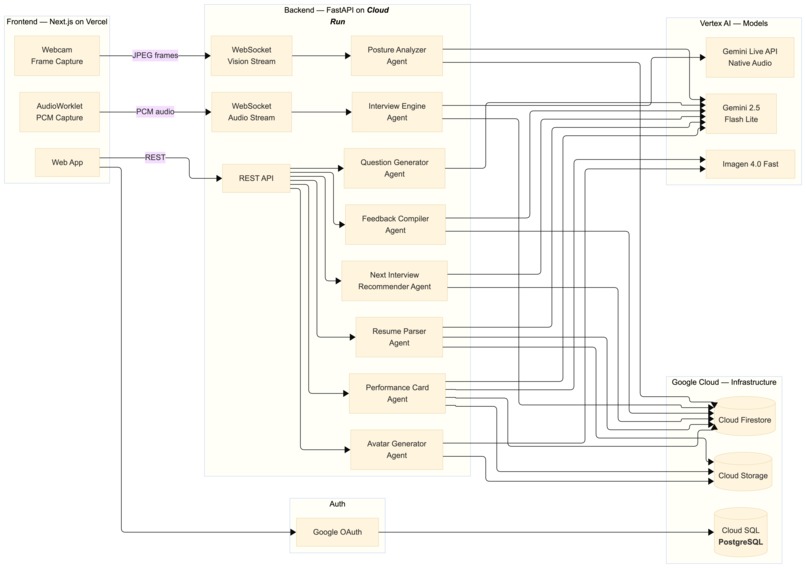
- 🏗️ The backend is a FastAPI application running on Google Cloud Run, built entirely on the Google GenAI SDK and Google ADK (Agent Development Kit)
- 🤖 Each of the 8 agents is implemented as a discrete ADK agent with its own system prompt, tool bindings, and guardrails
- 🎙️ The live interview is powered by the Gemini Live API over WebSockets — the server holds a persistent bidirectional session with Gemini and relays audio between the browser and the model in real time
- 🔄 The agent maintains a multi-phase state machine (rapport → core questions → follow-ups → closing) driven entirely by the system prompt, with a coverage-floor contract ensuring a minimum of 10 questions before wrapping up
- 🎭 Each interviewer persona is defined with structured SPEECH STYLE blocks (tone, pace, warmth, filler words, energy) and ACCENT GUIDANCE (22 accent types) — all encoded in the system prompt so the Gemini Live API produces naturally distinct voices without any external TTS
- 🔒 All structured reasoning — résumé parsing, question generation, feedback compilation, posture analysis — uses Gemini 2.5 Flash Lite with JSON-schema-constrained output to eliminate hallucinations and guarantee grounded, parseable responses
- 🖼️ Interviewer avatar and performance card images are generated with Imagen 4.0 Fast on Vertex AI
- 🗄️ Data layer runs on Firestore (sessions, transcripts, feedback) and Google Cloud Storage (résumés, images)
- 🌐 The frontend is a Next.js app deployed on Vercel, using the Web Audio API and AudioWorklet to stream microphone input to the backend with minimal latency
Check out the full architecture diagram here - Architecture diagram
Challenges I ran into
- 🗣️ Making the Gemini Live API feel truly conversational was the hardest part. Early versions felt robotic — the agent would ask a question, wait for silence, and move on. I spent significant time tuning the system prompt to handle natural overlaps, and the subtle social cues that make a real interview flow (like brief acknowledgments before follow-ups). The PHASE 3 evaluation logic classifies every answer as STRONG, WEAK, or GIBBERISH before responding, and the guardrails section implements a 4-strike escalation protocol for nonsensical answers.
- 🎭 Giving each persona a genuinely distinct voice and personality was incredibly difficult. I needed 13 interviewers who don't just ask different questions but sound different — different pacing, different energy, different accents, different filler words. A fast-talking startup founder should feel nothing like a measured management consultant. Getting the Gemini Live API to produce these distinct speech patterns consistently required dozens of prompt iterations, adding structured SPEECH STYLE and PERSONALITY blocks in
personas.json, building 22 accent-specific phonetic guidance blocks (from Indian English to Scandinavian English), tuning 5 randomized flavor dimensions (3^5 = 243 unique style combinations per session), and testing exhaustively to make sure the personas didn't bleed into each other. - 📋 Building a reliable coverage-floor contract — ensuring the agent asks enough substantive questions before closing without sounding scripted — required multiple iterations of prompt engineering and runtime guardrails. The coverage contract (Section 3B) enforces that all 6 distinct bank primaries are asked exactly once with 1–2 follow-ups each, while the per-persona question-type policies control which types of questions each persona is allowed to ask.
- 👁️ Posture analysis without breaking the flow — I needed periodic webcam snapshots analyzed without adding perceptible latency or interrupting the conversation. I ended up running posture analysis asynchronously, batching snapshots and processing them in parallel while the voice session continued uninterrupted.
- ⚖️ Fair scoring across role levels and difficulties required careful calibration — a dynamic threshold system with role-level inference (mapping role strings to seniority 0–4) and difficulty offsets, clamped within a sensible range, so that an intern-level easy interview isn't graded on the same curve as a staff-level hard one.
Accomplishments that I'm proud of
- 🚫⌨️ Zero typing after résumé upload — the entire interaction, from interviewer greeting to final feedback letter, happens through real-time voice and vision. The résumé parser extracts structured data including
bold_claims(probing targets), which feeds into the question generator and ultimately the live interview prompt — all without the candidate typing a word. - 🎭 13 personas that actually sound different — each interviewer has a distinct voice, pacing, accent, warmth, and personality. A fast-talking, high-energy investment banker feels completely different from a calm, methodical system design expert. This is driven entirely by structured persona definitions with PERSONALITY and SPEECH STYLE blocks, 22 accent guidance mappings, and per-session flavor randomization. The Gemini Live API produces these naturally from the system prompt alone — no external TTS, no post-processing — and it genuinely feels like talking to different people 🎉
- 🧠 Intelligent, résumé-grounded follow-ups — the agent digs deeper based on the candidate's actual experience and claims, not generic scripts. The résumé-as-source-of-truth rule prevents the model from ever attributing skills not on the résumé, while the role-relevance filter ensures questions match the target role.
- 📬 Consequential feedback — a structured hiring decision with a reasoned explanation, not vague suggestions. The feedback prompt produces dimension scores with speaker attribution rules (never evaluate the interviewer's words), and the dynamic decision threshold calibrates pass/fail by role seniority and difficulty.
- 🏗️ Clean agent architecture — 8 specialized agents, each with a clear responsibility, orchestrated through ADK with clean handoffs and no monolithic prompts. The system is modular enough that I can swap out any agent independently — from the avatar generator to the performance card renderer to the next-interview recommender.
What I learned
- 🎙️ Prompt engineering for voice is a different discipline — timing, pacing, and conversational repair matter as much as content. Writing prompts for real-time audio agents is fundamentally different from writing prompts for text
- 🔒 Schema-constrained generation prevents hallucinations — every agent that returns structured data uses JSON-schema-constrained output, and it made the entire multi-agent pipeline dramatically more reliable
- 🤯 The Gemini Live API's voice is shockingly steerable from the prompt alone — This genuinely fascinated me 🤯🙀! I expected I'd need an external TTS engine, voice cloning, or at least some audio post-processing to make interviewers sound different. Instead, I found that just injecting the right values into structured SPEECH STYLE and ACCENT GUIDANCE blocks in the system prompt completely transformed who you were talking to. Change
pace: "rapid-fire"topace: "measured, deliberate", swapaccent: "AMERICAN ENGLISH"toaccent: "INDIAN ENGLISH", crankwarmthfrom 3 to 9, and suddenly the same model sounds like an entirely different human being. No code changes, no voice parameters, no API flags — just words in a prompt reshaping a voice in real time. It felt like discovering a cheat code. I'd tweak a few adjectives, reconnect, and hear a completely new person greet me. That moment — realizing the audio model was interpreting personality descriptions and translating them into distinct speech patterns — was the most exciting part of this entire build. - 🎭 Persona distinctiveness lives in the system prompt — rather than managing voice parameters in application code, I encode speech style, accent, warmth, and pacing rules directly in the prompt, and the Gemini Live API follows them remarkably well
- 🧠 The Gemini Live API + system prompt state machine is powerful — I can encode phase transitions, coverage contracts, and pacing rules directly in the prompt, and the model follows them reliably without external orchestration code
- 🏗️ ADK simplifies agent orchestration — Google's Agent Development Kit handled session management, request queuing, and streaming to/from the Gemini Live API, letting me focus on product logic rather than infrastructure plumbing
- 🗄️ Firestore's flexibility accelerated iteration — schemaless storage let me iterate on data structures without migration overhead
What's next for MockMate
- 🌍 Multi-language interviews — leveraging Gemini's multilingual capabilities to conduct interviews in the candidate's preferred language
- 👥 Panel interviews — multiple AI interviewers with distinct personas and specializations taking turns, simulating real panel dynamics
- 🖥️ Live screen-sharing rounds — integrating Gemini's vision capabilities to observe the candidate's screen during coding or system design interviews for real-time technical assessment
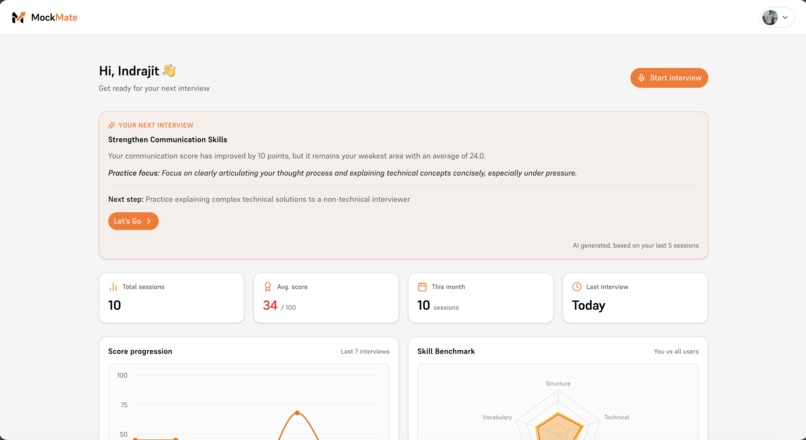
- 📈 Longitudinal progress tracking — analytics across multiple sessions showing improvement trends, recurring weaknesses, and personalized study plans
- 📱 Mobile-native experience — a dedicated mobile app for practicing interviews on the go, using on-device audio processing for lower latency. The good news is that the web app is responsive, so you can take mock interviews in mobile too!
Links
| Resource | URL |
|---|---|
| 🌐 Live App | getmockmate.com |
| 💻 GitHub Repository | github.com/mockmate-app/mockmate |
| ✏️ Architecture Diagram | Architecture diagram - Mermaid |
| 📹 Demo video | Demo video - YouTube |
| 📝 Blog Post | Introducing MockMate — Medium |
| 👥 Google Developer Group | GDG Profile |
Built With
- better-auth
- cloud-sql
- cloud-storage
- fastapi
- firestore
- gemini-2.5-flash-lite
- google-adk
- google-cloud
- google-cloud-run
- google-gemini
- imagen
- nextjs
- python
- react
- tailwind
- typescript
- vercel
- vertex-ai




Log in or sign up for Devpost to join the conversation.