Mockly — The Best Way to Prep For Interviews
Inspiration
We wanted interview prep that felt human, but safe. We pictured "AI in a bubble": a friendly face you can speak to, not just a chat window. For classmates (and ourselves) who are introverted or anxious, voice practice lowers the barrier to start, repeat, and improve. Mockly began as a way to put a virtual face to a name, and grew into a path for low-pressure conversational practice.
What it does
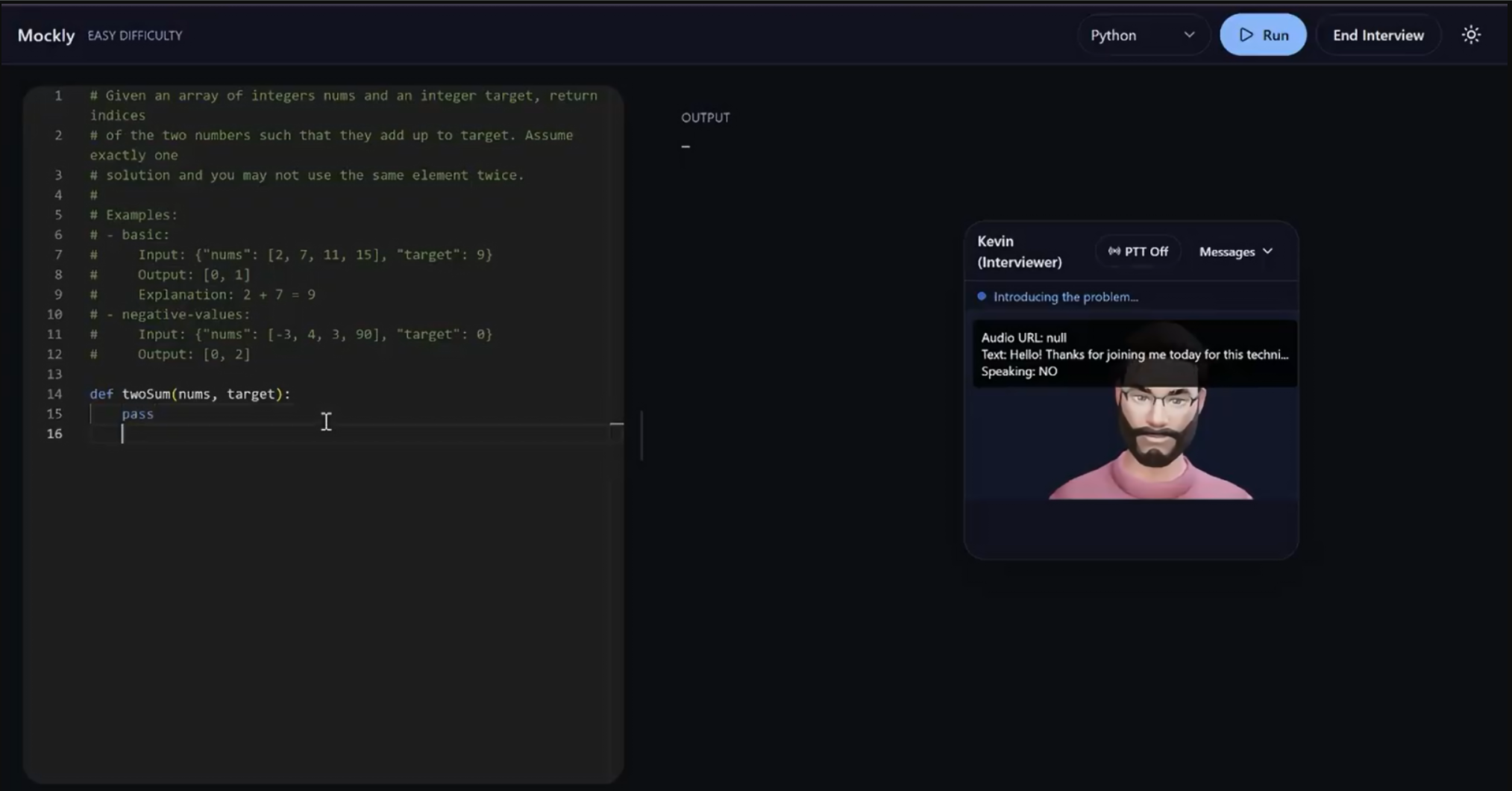
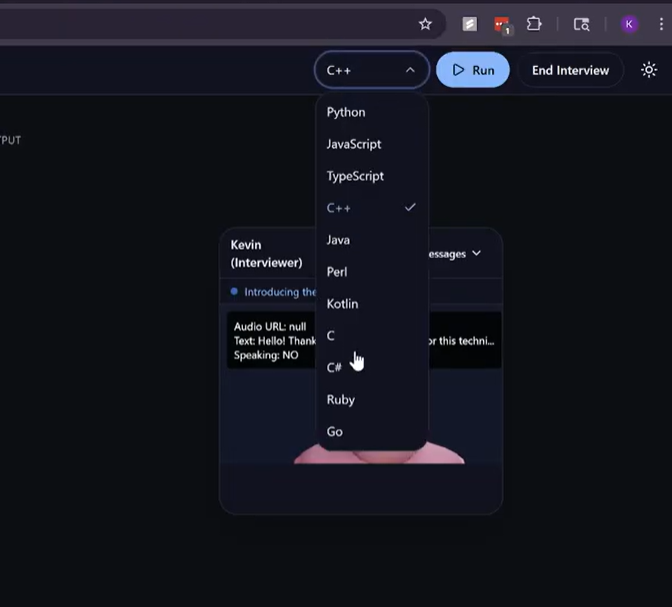
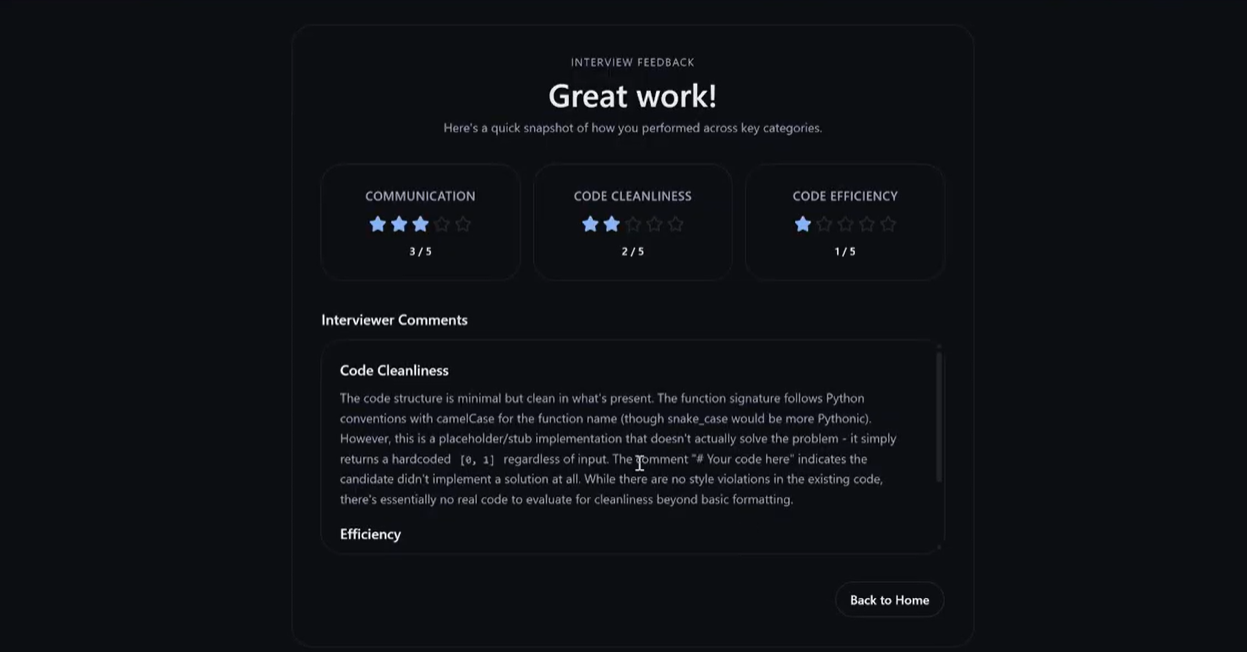
Mockly is a voice-enabled AI for coding interviews. A realistic interviewer presents a problem, listens to your reasoning, chats back, and runs your code in a live IDE (Python, JS/TS, C/C++, Java, Go, C#, Kotlin, Ruby, Perl). After a session, it summarizes performance across code cleanliness, communication, and efficiency.
How we built it
Frontend
- React + Vite + TypeScript, Monaco Editor for code, Zustand for state
- A "talking head" avatar via
@met4citizen/talkingheadwith real-time lipsync - WebRTC mic streaming (user gesture to enable), and a resilient WS client for voice events
- Direct backend calls (bypassing dev proxy) to stabilize requests in Docker
- Lightweight Markdown renderer for assistant messages
Backend
- FastAPI with CORS, Dockerized
- Anthropic Claude for interview logic and feedback text
- Deepgram for speech: prerecorded STT (Listen) and low-latency streaming TTS (Speak)
- Code execution service: subprocess compile/run for multiple languages
- Question management: YAML questions, examples, and per-language starter code
- WebRTC via
aiortcfor mic capture; sentence-chunking of model tokens → TTS frames for responsive audio
Challenges we ran into
Voice/TTS auth and streaming
Deepgram Speak 401s surfaced only after the first WS write; added diagnostics, safe fallbacks, and a browser SpeechSynthesis fallback for silent turns.WS handshake churn (localhost vs 127.0.0.1) in Docker/Windows; added multi-candidate WS URLs and backoff.
Browser interaction rules
getUserMediawithout a click left the mic "busy" and the button disabled; we deferred mic warmup until user intent.Dev proxy vs direct origin
Vite restarts caused intermittent 404/connection refused; we switched the client to call the backend origin directly.Frontend gotchas
JS automatic semicolon insertion (IIFE after state call) broke sending; fixed with explicit semicolons.
Markdown showed raw asterisks; added a small, escaped renderer.Starter code and UX papercuts
C++ examples missing headers (vector); Java lacking aMainentry; updated YAML for out-of-box runs.
Accomplishments that we're proud of
- A cohesive voice + avatar + IDE loop that feels personal, not robotic
- A multi-language runner that lets candidates practice in their preferred stack
- Real-time token chunking → TTS streaming for responsive, conversational delivery
- Cleaner DX: robust WS reconnection, direct backend routing, and safer markdown
What we learned
- Voice UX matters: short, sentence-aware streaming is miles better than long, monolithic replies
- WebRTC and WS in containers need pragmatic fallbacks (origin resolution, candidate lists)
- Getting a robust frontend-backend integration and communication with continuous, rigorous testing and validation
- Aligning the displayed question with the interviewer's prompt is critical for trust
What's next for Mockly — The Best Way to Prep For Interviews
Today, Mockly focuses on technical interviews with voice and live code execution. The same stack is well-suited to expand thoughtfully:
- Short-term: richer transcripts, rubric tuning, exportable reports, and typed-reply TTS
- Medium-term: scenario packs (behavioral rounds), pacing controls, and structured follow-ups
- Long-term: a supportive practice space for broader conversations that's designed for students, the socially anxious, the introverted, so confidence grows one conversation at a time
Built With
- aiortc
- claude
- css(tailwind)
- deepgram
- docker
- fastapi
- httpx
- javascript
- monacoeditor
- node.js
- npm
- poetry
- python
- react
- talkinghead
- typescript
- vite
- webrtc
- yaml
- zustand



Log in or sign up for Devpost to join the conversation.