Inspiration
We've recently experienced the struggle of trying to find the best options for an Erasmus (or other) international mobility. The large amount of possibilities, each one with its own particularities, makes the task of choosing the best option an intimidating prospect at least.
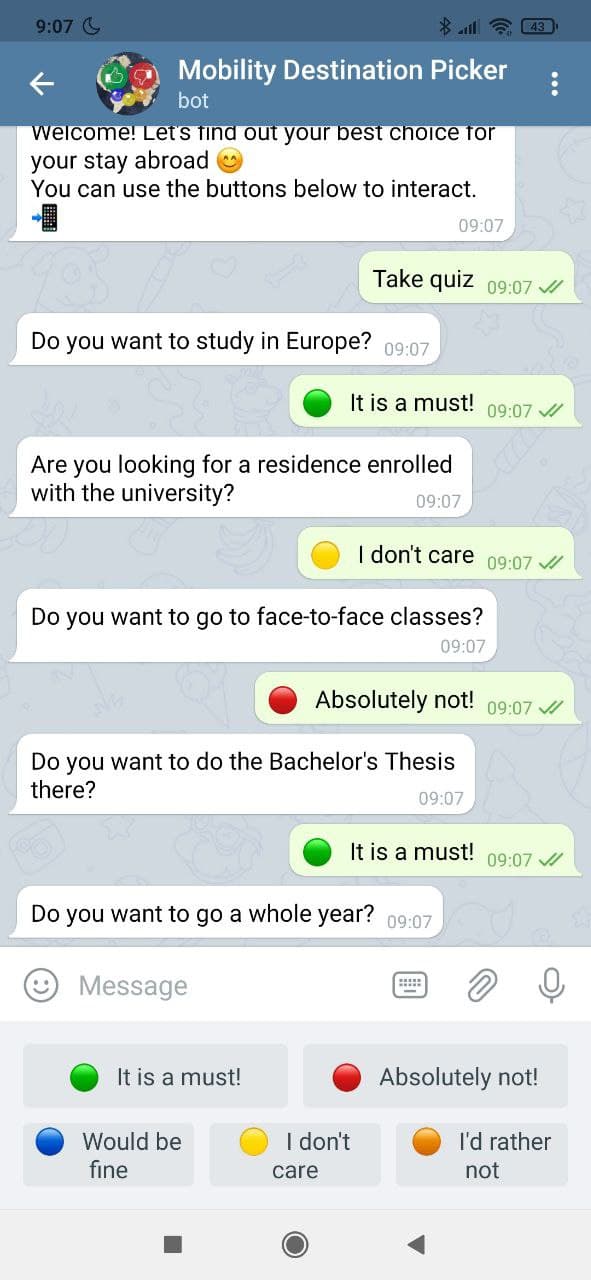
With this project we aim to simplify the process of choosing your next university for an international mobility with a quiz that is both easy and quick to answer.
We had been inspired by the popular mobile application Akinator, which is used to guess the name of a celebrity.
What it does
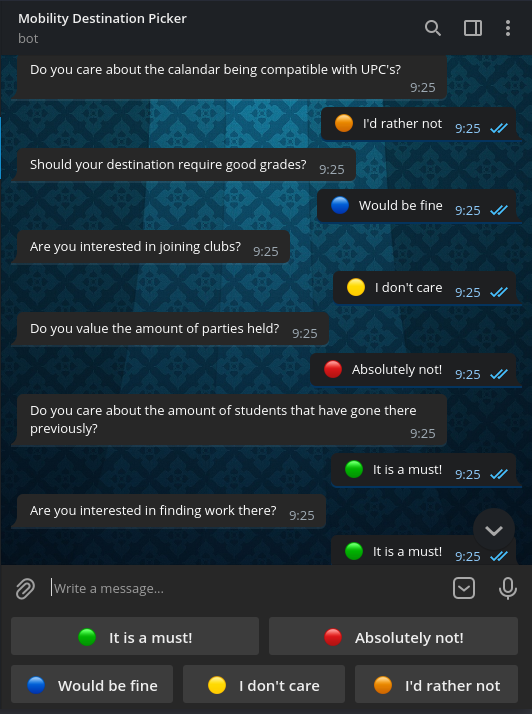
Given a data set of universities and its relevant (or not!) information, which would be provided by UPC from its current agreements or extracted from the internet, possibly complemented with information from past students, the program selects each time a question to discriminate between universities that is optimal in terms of separating them (taking into account the previous answers).
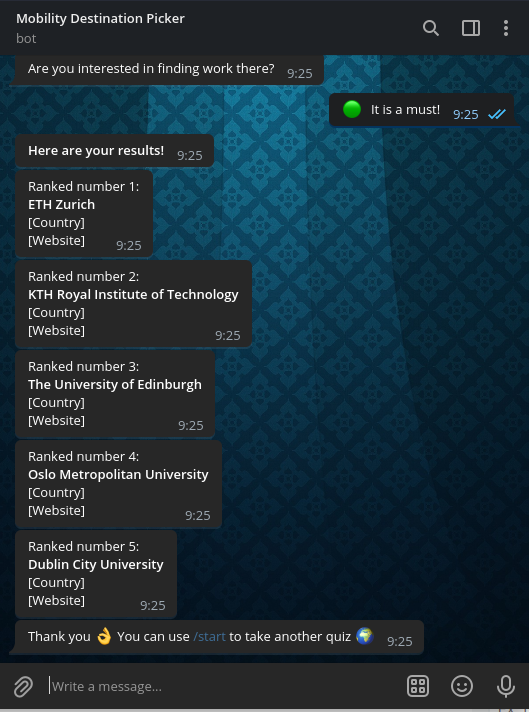
In the background, it builds an estimate of a probability distribution that is iteratively refined through questions until it is confident to having found the best university for the user. Then it presents the top 5 choices.
How we built it
The backend is coded in Python using ideas gathered from the internet and our knowledge of probabilty and Bayesian statistics. For the user interface, we opted to make a Telegram bot, since it is very easy to use in its web interface or desktop or mobile apps. The program is mainly navigated through buttons, making it very easy to use.
Finally, we created two artificial data sets. The first one was manually curated and consists of data from around 30 universities; this is used to illustrate how a real example would work (choosing questions based on the previous answers, getting coherent results, etc.). The second data set was extracted from the internet and expanded with artificial random data; its purpose was to test the programs capabilities when dealing with vasts amounts of data.
Challenges we ran into
Getting a coherent database was probably the largest trouble. It is very heart to judge if the program is outputting sound predictions when the data are purely random!
Accomplishments that we're proud of
We managed to finish it (mostly) on time :) And the bot seems to be stable and fast to run even with large data sets.
What we learned
We managed to improve our knowledge of how Telegram's bots work and how to deal with this kind of data in Python.
What's next for Mobility Destination Picker
Let's hear feedback from the users and see if their predictions are sound and useful. We also would have loved to establish better criteria to determine when to end the quiz and give feedback about its confidence (indicating if there are still many questions left or not).
From the university perspective (i.e. those dealing with the data set) we would have liked to implement the ability to have missing data (which is not hard to do, but time consuming...) and to generate human readable questions automatically given the variables on the data set.




Log in or sign up for Devpost to join the conversation.