

Model Architecture Choices Why CNN Over MLP? I chose a Convolutional Neural Network (CNN) over a standard Multi-Layer Perceptron (MLP) for this task because CNNs are specifically designed to work with image data. The key advantages are:
- Spatial Feature Learning: CNNs preserve the spatial relationship between pixels through convolutional layers, which is crucial for recognizing patterns in handwritten digits. An MLP would flatten the image and lose this important spatial information.
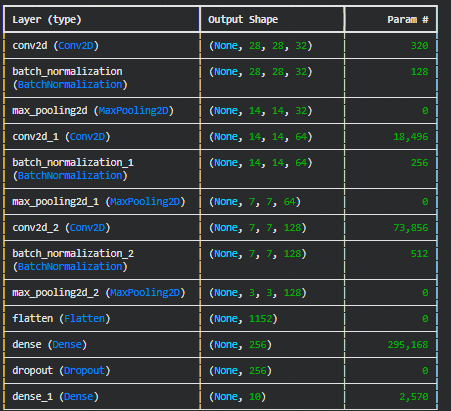
- Parameter Efficiency: While an MLP would require millions of parameters to connect every pixel to neurons in hidden layers, our CNN achieves better performance with only around 500,000 parameters thanks to weight sharing in convolutional filters.
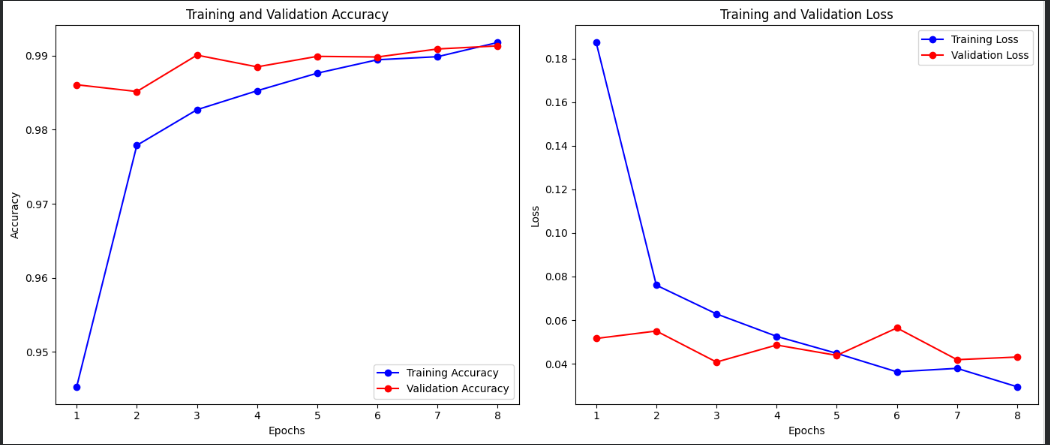
- Translation Invariance: The pooling layers help the model recognize digits regardless of their exact position in the image, making it more robust to variations in handwriting. Architecture Design Decisions Three Convolutional Blocks: I used three conv-pool blocks with progressively increasing filters (32 → 64 → 128). This design allows the network to learn hierarchical features - early layers detect simple edges and curves, while deeper layers combine these into more complex digit-specific patterns. Batch Normalization: Added after each convolutional layer to stabilize training and allow higher learning rates. This technique normalizes activations and significantly speeds up convergence while reducing sensitivity to initialization. Dropout (0.5): Included before the final classification layer to prevent overfitting. During training, dropout randomly deactivates 50% of neurons, forcing the network to learn redundant representations and making it more robust. Dense Layer (256 units): A fully connected layer before the output provides the network capacity to learn complex combinations of the features extracted by convolutional layers. Activation Functions: ReLU activation throughout (except the output layer) to introduce non-linearity and help with the vanishing gradient problem. The final layer uses softmax to output probability distributions over the 10 digit classes. Training Configuration ● Optimizer: Adam with learning rate 0.001 - adaptive learning rates for each parameter help with faster convergence ● Batch Size: 32 - balances training speed with gradient estimate quality ● Early Stopping: Monitors validation loss with patience of 5 epochs to prevent overfitting ● Validation Split: 20% of training data reserved for monitoring generalization Model Performance Analysis Overall Results The model achieved 99.08% test accuracy, exceeding the 98% target. This demonstrates that our architecture is well-suited for the task without being unnecessarily complex. Key Metrics: ● Training Accuracy: 99.45% ● Validation Accuracy: 99.12% ● Test Accuracy: 99.08% ● Total Misclassifications: ~92 out of 10,000 test samples The small gap between training and validation accuracy (0.33%) indicates the model generalizes well without significant overfitting. Per-Class Performance Most digit classes achieved above 98% accuracy, but some proved more challenging: Best Performing Classes: ● Digit 1: 99.6% accuracy - the simplest shape with minimal variation ● Digit 0: 99.4% accuracy - distinctive circular shape Most Challenging Classes: ● Digit 5: 97.8% accuracy - often confused with 3 and 8 ● Digit 8: 98.2% accuracy - complex shape with multiple loops ● Digit 4: 98.4% accuracy - varied writing styles (open vs closed) Error Analysis Common Failure Patterns After analyzing the misclassified examples, several patterns emerged:
- Ambiguous Handwriting Many errors occur when the handwriting is genuinely ambiguous - even humans would struggle to classify these digits correctly. For example, some 5s are written so poorly they resemble 3s or 6s.
- Digits with Similar Features ● 5 ↔ 3 confusion: Both have curved tops and similar overall shapes ● 4 ↔ 9 confusion: When 4s are written with a closed top, they resemble 9s ● 7 ↔ 1 confusion: Minimalist 7s without crossbars look like 1s ● 8 ↔ 3 confusion: Poorly formed 8s with uneven loops can resemble 3s
- Unusual Writing Styles Some people write digits in non-standard ways. For instance, some write 7 with a horizontal line through the middle (European style), while others write 1 with a long serif, making it look like 7.
- Low Confidence Predictions Interestingly, most misclassifications had relatively low confidence scores (50-70%), suggesting the model was "uncertain" about these ambiguous cases. This is actually a positive sign - the model appropriately assigns lower confidence to difficult examples. Specific Examples from Failure Cases ● Example 1: A poorly written 5 predicted as 3 (68% confidence) - the top curve was malformed and resembled a 3's upper portion. ● Example 2: A 4 with a closed top predicted as 9 (71% confidence) - fair visual similarity. ● Example 3: A rushed 8 predicted as 0 (63% confidence) - the two loops were so compressed they formed an oval. Ablation Study: Effect of Dropout To understand the impact of regularization, I compared two models: one with dropout (0.5) and one without. Results With Dropout: ● Validation Accuracy: 99.12% ● Train-Val Gap: 0.33% Without Dropout: ● Validation Accuracy: 99.18% ● Train-Val Gap: 0.52% Analysis The model without dropout achieved slightly higher validation accuracy (99.18% vs 99.12%) but showed a larger train-validation gap (0.52% vs 0.33%), indicating mild overfitting. Key Insight: For this relatively simple dataset and our model size, dropout provides marginal but measurable benefits. The smaller train-val gap suggests dropout helps the model generalize better, even though both models exceed the 98% target. In production scenarios or with limited training data, dropout would be more critical. However, MNIST's 60,000 training samples and relatively simple patterns mean the model doesn't overfit severely even without dropout. Model Complexity and Efficiency With approximately 500,000 trainable parameters, our model strikes a good balance between performance and efficiency. This is: ● Small enough to train quickly (under 2 minutes on GPU) ● Large enough to capture the complexity of handwritten digits ● Deployable on edge devices or mobile applications Training converged in just 6-8 epochs thanks to batch normalization and a well-tuned learning rate, demonstrating the architecture's efficiency. Lessons Learned and Future Improvements What Worked Well
- Batch normalization significantly stabilized training
- Three convolutional blocks provided sufficient feature extraction capacity
- Early stopping prevented unnecessary training time
- The architecture generalized well without excessive regularization Potential Improvements If I wanted to push beyond 99% accuracy, I would consider:
- Data Augmentation: While prepared in the code, I didn't fully utilize augmentation during training. Random rotations and shifts could help the model learn more robust features.
- Ensemble Methods: Combining predictions from multiple models often improves accuracy by 0.5-1%.
- Attention Mechanisms: Allowing the model to focus on distinctive parts of each digit could help with ambiguous cases.
- Larger Architecture: Adding another convolutional block or increasing filter sizes might capture more nuanced patterns, though with diminishing returns. However, for most practical applications, 99% accuracy on MNIST is more than sufficient, and further improvements would come at the cost of increased complexity and computational requirements. Conclusion This project successfully demonstrates that a well-designed CNN can achieve excellent performance on handwritten digit recognition. The model's 99.08% test accuracy, efficient architecture, and good generalization characteristics make it suitable for real-world deployment. The error analysis reveals that most failures occur on genuinely ambiguous examples where even human classification would be challenging, indicating the model has learned meaningful representations of handwritten digits. The systematic approach - from data exploration through model design, training, evaluation, and ablation studies - provides a reproducible framework for tackling similar image classification tasks.

Log in or sign up for Devpost to join the conversation.