Inspiration
Every AI code reviewer today is stateless — it reads your code, gives feedback, and forgets everything. Next merge request? Same generic advice. Same false positives. Zero memory of what your team has already fixed, what patterns your codebase follows, or what violations keep recurring.
We asked: what if a code reviewer could remember?
What it does
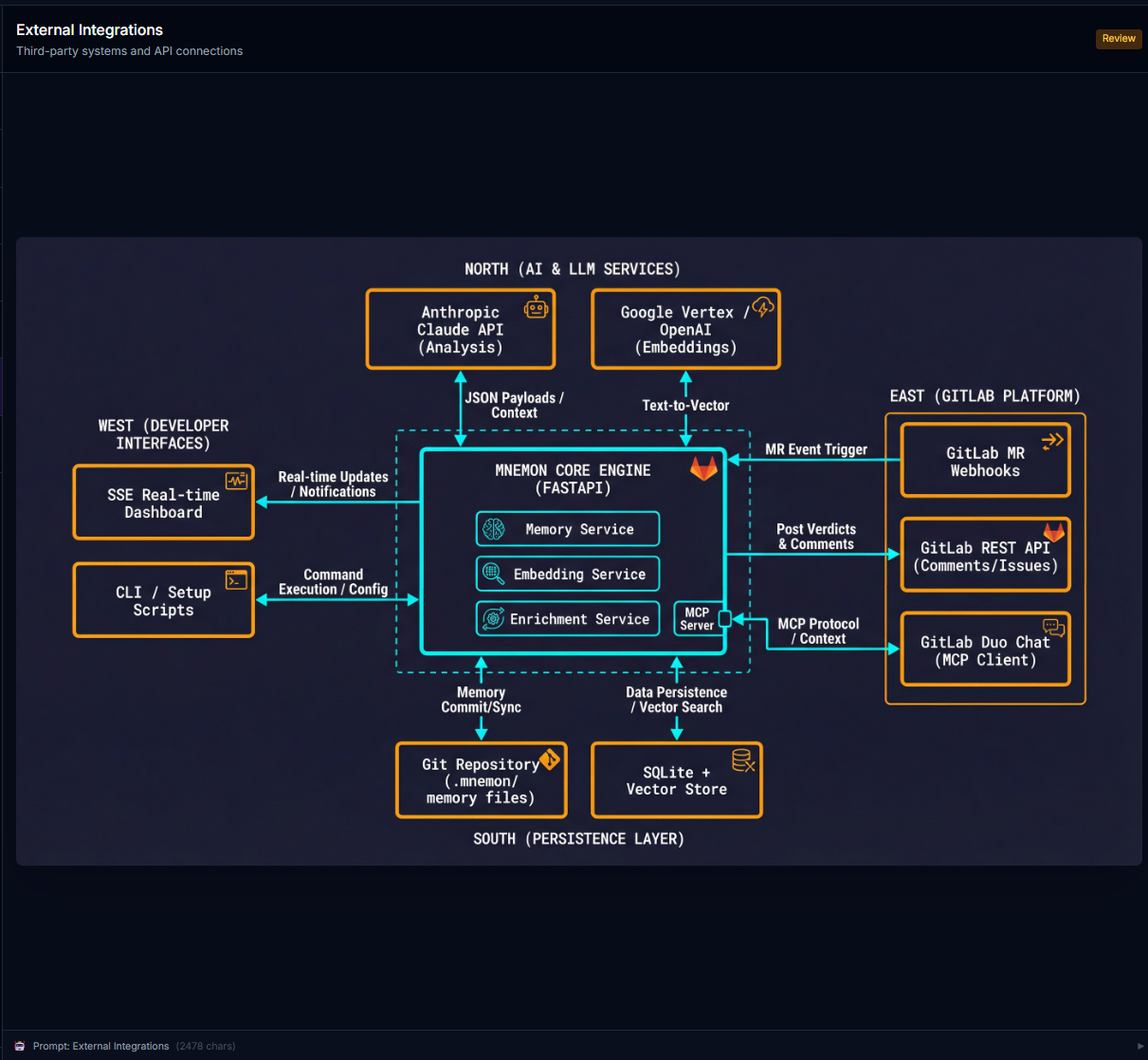
Mnemon is a three-agent code review system for GitLab that builds persistent memory across every merge request:
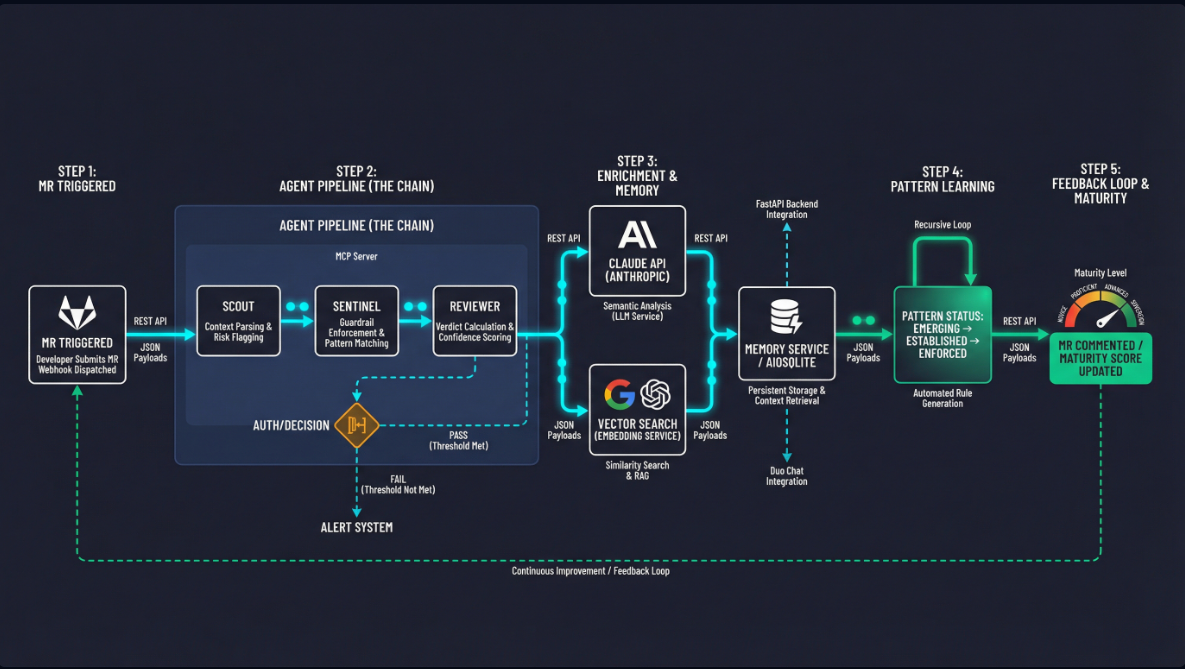
MR Created → Scout → Sentinel → Reviewer → Memory Committed
- Scout reads changed files and loads project memory (past patterns, review history, developer profiles)
- Sentinel enforces guardrails, matches learned patterns, runs a 10-category security scan, and detects regressions
- Reviewer posts a verdict with confidence score, inline comments, and follow-up issues — then commits updated memory back to the repo
Each review makes the next one smarter:
- Recurring violations get escalated through a lifecycle (EMERGING → ESTABLISHED → ENFORCED) with automatic severity boost
- Fixed issues get acknowledged and improve the project's maturity score
- Developer profiles track fix rates and adapt the reviewer's tone (NOVICE → COMPETENT → SENIOR → SOVEREIGN)
- The system reports token savings from memory-informed reviews — quantifying the value of context
How we built it
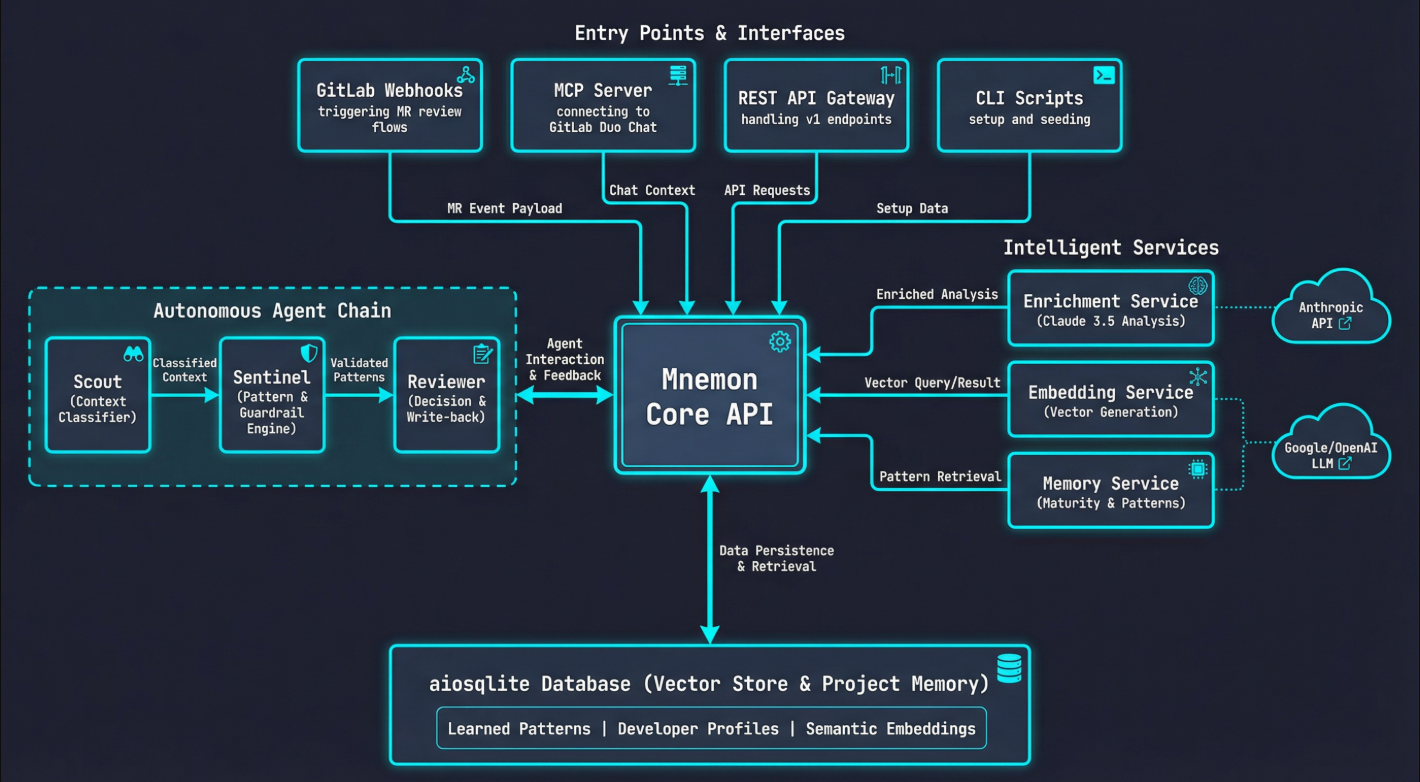
- GitLab Duo Agent Platform — Three YAML-configured flows (
review,onboard,recall) with the Scout → Sentinel → Reviewer agent chain - FastAPI Backend — Async Python with aiosqlite, 14+ REST endpoints, SSE streaming, and webhook integration
- MCP Server — 6 tools (
mnemon_recall,mnemon_patterns,mnemon_stats,mnemon_similar,mnemon_review_history,mnemon_developer) exposed via Streamable HTTP for GitLab Duo Chat - Vector Search — Google Gemini embeddings (3072-dim) with OpenAI fallback, cosine similarity search across past findings stored as numpy BLOBs
- Anthropic Claude — Powers the enrichment pipeline with semantic analysis of recurring patterns
- Git-Backed Memory — Patterns, project profiles, and review history stored as JSON in
.mnemon/and committed to the repo — zero external infrastructure - Guardrail Engine — 8 default rules, 10-category security scanner, layer violation detection, lifecycle severity boosting, framework-specific filtering
Challenges we ran into
- GitLab AI Catalog 64 KiB limit — Flow YAML version definitions have a hard size cap. We had to compress the three-agent review flow without losing functionality, which forced us to make every prompt token count
- Pattern quality control — Not every finding should become a learned rule. We built a lifecycle system where patterns must recur across 2+ sessions before EMERGING, 5+ for ESTABLISHED, and 10+ for ENFORCED — with automatic deprecation after 10 reviews of inactivity
- Token budget management — Large MRs with many changed files can exceed context limits. We implemented file prioritization, chunking, and token savings reporting (
PATTERNS_REUSED × 500 + PAST_REFS × 300) - Dual persistence model — The Duo agents need git-committed files (
.mnemon/), but the backend needs a database for vector search and analytics. Keeping both in sync without race conditions required careful design - Tone calibration — Making the reviewer's communication style adapt based on maturity level and developer experience without being condescending or too terse
Accomplishments that we're proud of
- 430+ tests passing with zero failures — covering the full stack from API routes to MCP tools to flow YAML validation
- Three-agent architecture where each agent has distinct read/write permissions — Scout and Sentinel are read-only, only the Reviewer can write
- Pattern lifecycle system that automatically graduates, boosts severity, and deprecates rules based on real evidence
- Developer profiles that track per-person fix rates, streaks, and adapt the review tone accordingly
- Zero infrastructure requirement — SQLite + git-committed JSON means the entire memory system lives in the repo itself
- 6-tool MCP server that gives Duo Chat conversational access to the full review memory
What we learned
The biggest insight: memory transforms a tool into a mentor. A stateless reviewer is just a function call. A reviewer with memory becomes a teammate that grows with your project.
The second insight: maturity scoring changes behavior. When developers can see their project's health score trending upward (rendered as a sparkline: ▁▂▃▄▅▆▇█ ↑), they're motivated to fix issues rather than dismiss them. The gamification is subtle but effective.
The third insight: tone matters as much as accuracy. A NOVICE project needs patient, educational feedback. A SOVEREIGN codebase needs concise peer-level observations. Getting this wrong makes developers ignore even valid findings.
What's next for Mnemon
- Cross-project learning — Share proven ENFORCED patterns across repositories within an organization
- Live dashboard — Real-time SSE-powered view of review activity, pattern trends, and team health (SSE endpoint already built)
- IDE integration — Surface Mnemon memory in VS Code / JetBrains via the MCP server
- Regression alerting — Notify team leads when a previously-fixed pattern reappears
- Multi-language guardrail presets — Expand beyond the current minimal/standard/strict presets to framework-specific rulesets

Log in or sign up for Devpost to join the conversation.