Inspiration
In the modern age, our heads are increasingly being crammed with a seemingly endless stream of information at every moment of our daily life.
This project is the product of our accumulated frustration having to input lengthy and confusing credit card details, gift card codes and passwords or communicate serial numbers to technical support. We thought that surely there was a way to preserve security while improving simplicity and ease of use when handling such data.
The most secure passwords are those that combine different characters in a non-trivial order. However, this is unfeasible to remember as humans, we aren’t supposed to remember sequences of unrelated symbols well - they aren’t just as meaningful as words. It’s not just passwords though, student ids, phone numbers, credit card numbers, authentication codes, product codes, all use unintelligible sequences of random numbers and characters that are a pain to remember and use with no error, yet still contain vital information about ourselves
Reducing this information overload without sacrificing our privacy will declutter our heads and enable all individuals who participate in modern life to focus on what really matters.
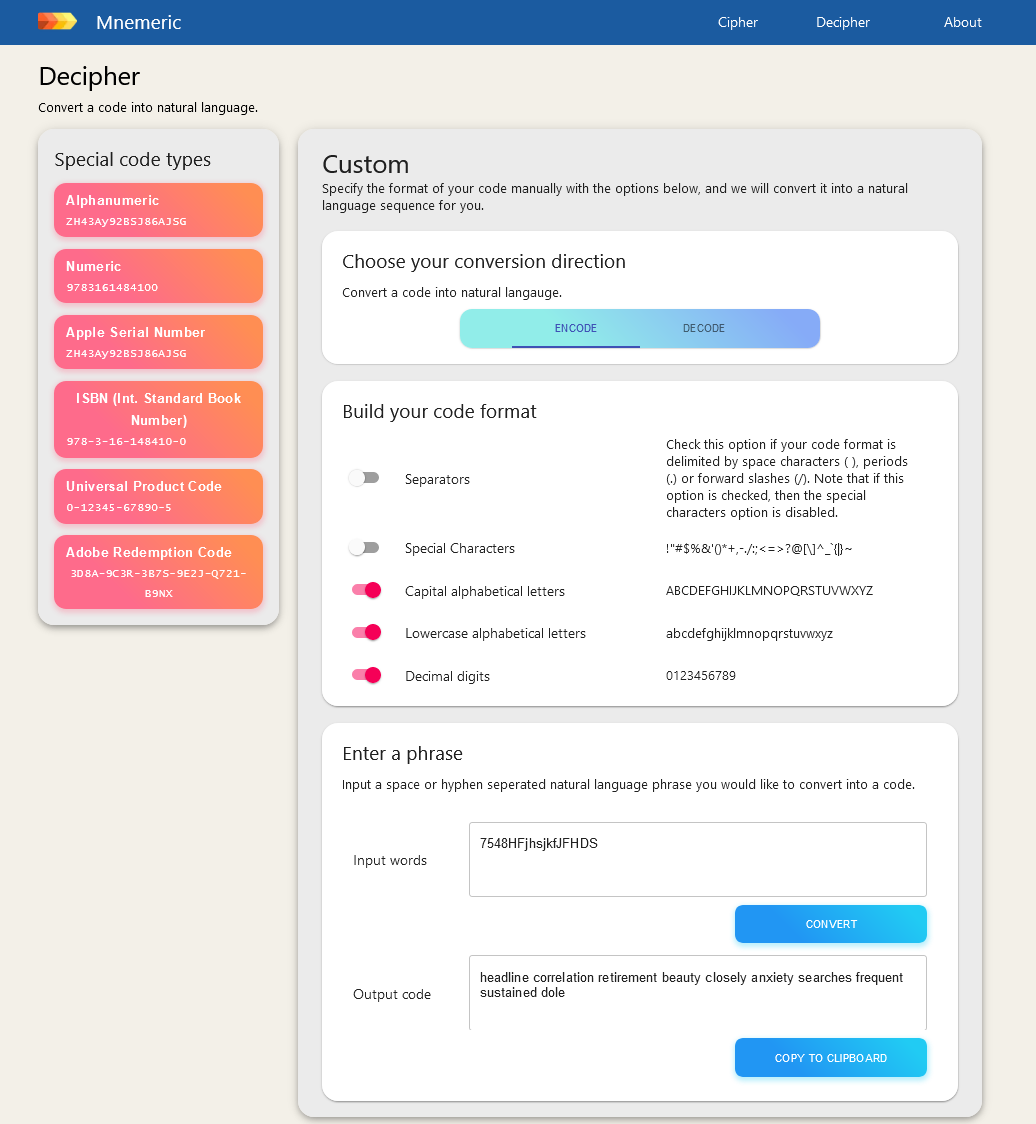
What it does
Mnemeric is a cipher that translates between binary data and natural language. Users can supply complex sequences of ASCII characters on our website and encode them into simple, memorable words. They are able to customise the settings to cater for various code types (numeric, alphanumeric, UPC, ISBN…) Inversely, English phrases can also be decoded back into ASCII code.
How we built it
Step One: Sourcing Word Dictionary
We calculated the frequencies of all the words in the OANC (Open American National Corpus), applied some length filtering and character filtering (lowercase, remove hyphen etc.), then after filtering profanity using a profanity list from Carnegie Mellon University, we took the top 8196 most frequent words. This allows us to encode 13 bits into a single dictionary word. 2^13 = 8196
Step Two: Encoding Scheme and Control Word
Since encoding directly between ASCII and dictionary words will only provide a word to character ratio of 13/8, which is quite poor, and the fact that many types of data in the real world have a limited alphabet of characters, we decided to implement an encoding scheme to optimise the encoding of different types of data. Our scheme uses a **13 bit control word **at the start of the code phrase to store data about the encoding scheme (5 bits), a message length offset (4 bits) which is necessary for accurate decoding, room for a small checksum (2 bits) for validation, and a encoding number (2 bits) which allows the user to select between four possible encodings. The encoding number serves to allow users to avoid rare code phrases which contain several duplicate words, or specific words.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Encoding Scheme | End of Message Offset | Checksum | Hash |
Please note that the checksum and hash components are not implemented in the demo. The Encoding Scheme is a set of five boolean values that determine whether a common set of characters is present in the encoded data, this makes the encoding of data that has a limited character set (such as numeric only) much more efficient.
| 0 | 1 | 2 | 3 | 4 |
| Encoding Scheme huffman encoding | ||||
| Separators | Special | Capital | Lowercase | Numeric |
Note that the Separators character set is a subset of the Special character set, so these values are mutually exclusive. If both of these values are set to true, we consider the following three bits to represent an extended encoding type.
Step Three: Building the Website
This is a Next.js project bootstrapped with create-next-app.The front end was built with react and used the materials UI components. It implements a dynamic re-rendering of the numeric cipher algorithm.
Challenges we ran into
As we are a team comprising entirely of first years, most of us lacked the technical knowledge sufficient to build and develop a large scale product. There were many more ambitious and creative ideas we first conceived of which we simply had to pass up. Although we believed in the intrinsic value of the product, we had to formulate the means to define a target group and communicate this need to an audience.
Naturally, time limited how much better we could improve the efficiency of the algorithm and the dataset quality through filtering. We were forced to prioritise some aspects over others, meaning that we could not implement every feature we wanted, or experiment with adjustments to the user interface.
Accomplishments that we're proud of
We are all extremely proud of our grit, having pushed the project to completion even when we faced many doubts about the ultimate viability of the concept and our programming capabilities as first years. Our developers impressed with innovative solutions to the technical implementation, creatively using control words, bit manipulation and Huffman Coding. However, at times, we struggled to understand and coordinate with each other due to the varying technical backgrounds of our team members. After everything though, we still built a working, useful product we can take pride in but more importantly we learned a lot of valuable lessons along the way.
What we learned
Although we were not short of ideas, we had to evaluate which of them objectively had the greatest chances of becoming a minimum viable product. This taught us to temper a flexibility and openness to wild ideas with a more rigorous approach to the ideation process. Even when we eventually settled on a concept, many of us were forced to adapt and discover avenues to make ourselves useful while alleviating the burden of those with the more fundamental roles of implementing the product. On the technical side, our developers solidified our understanding of client-side state management. We learned the importance of data quality and where to source useful datasets, upon which our link between binary data and natural language hinged.
What's next for Mnemeric
The immediate goal for Mnemeric is to improve the user interface and functionality, as some features were dropped in the last minute when they were yet to become functional.
Further refinements to the algorithm can reduce the number of words required to represent a character sequence. We were just shy of being able to convert a ten digit sequence of numbers for a phone number into three words, however some bugs meant that the feature was scrapped in the last moments.
It might also help to manually fine tune the word dictionary by filtering out words with a grammatical function such as prepositions, and words which are similar or unpopular. This could improve the efficacy of the service.
In the long term, we want to make this product more convenient and widespread changing its form into a universal standard. This could allow companies and governments to use the cipher on physical cards, devices, digital services, and other formats where it may be helpful to have a human readable form of machine readable data. Specifically, gift cards, serial numbers, phone numbers, and account numbers, and two factor authentication codes would be suitable mediums in which Mnemeric could be applied.
Built With
- java
- javascript
- next.js
- node.js
- react


Log in or sign up for Devpost to join the conversation.