-
-
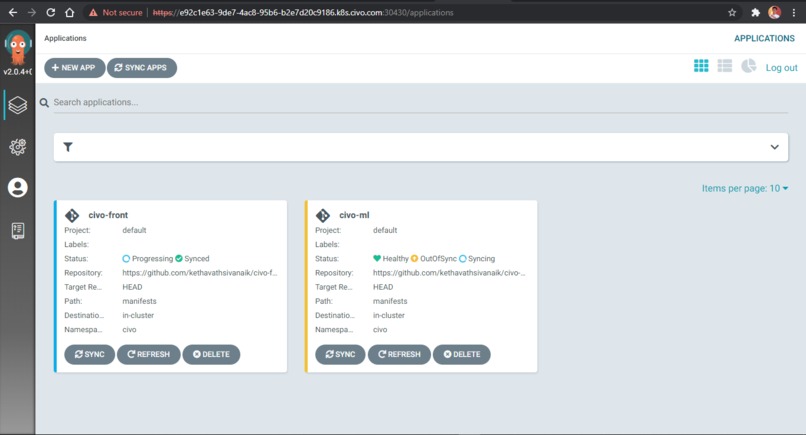
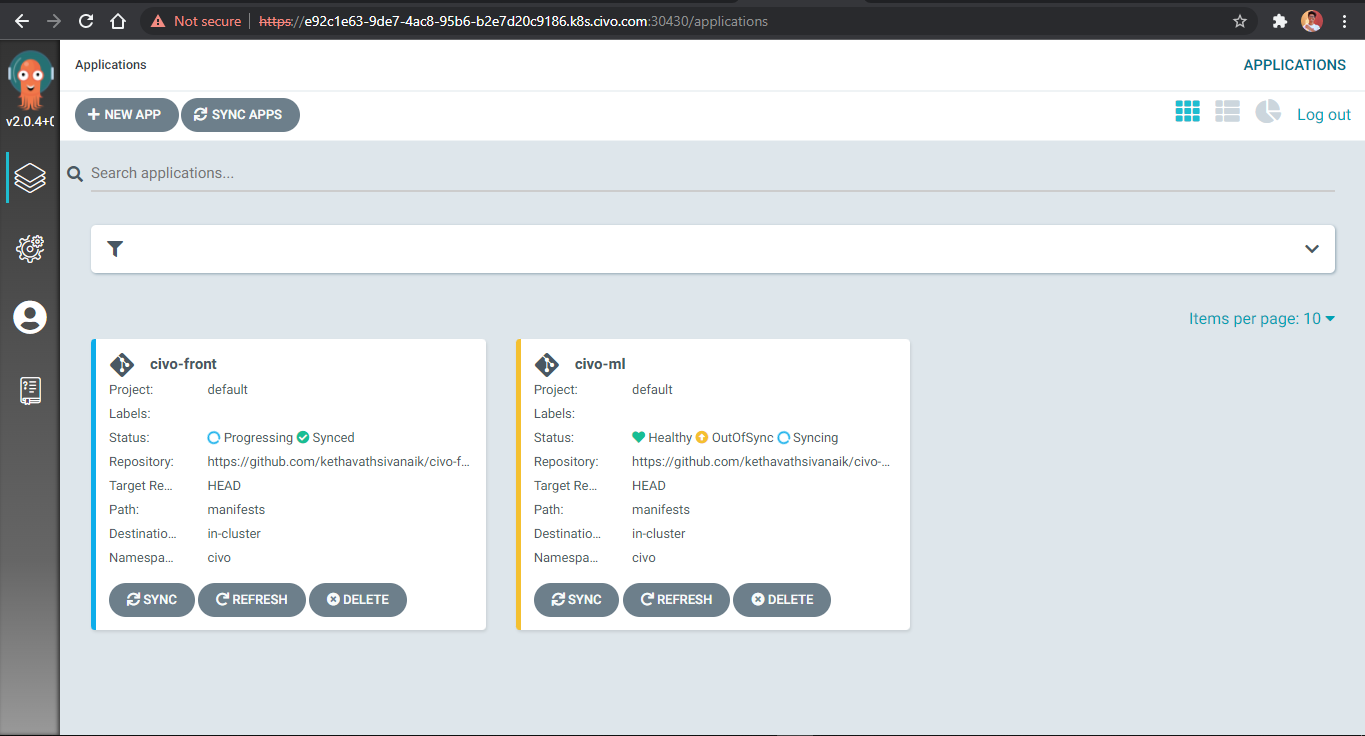
ArgoCD
-
civo-ml-repo
-
-

Civo
-
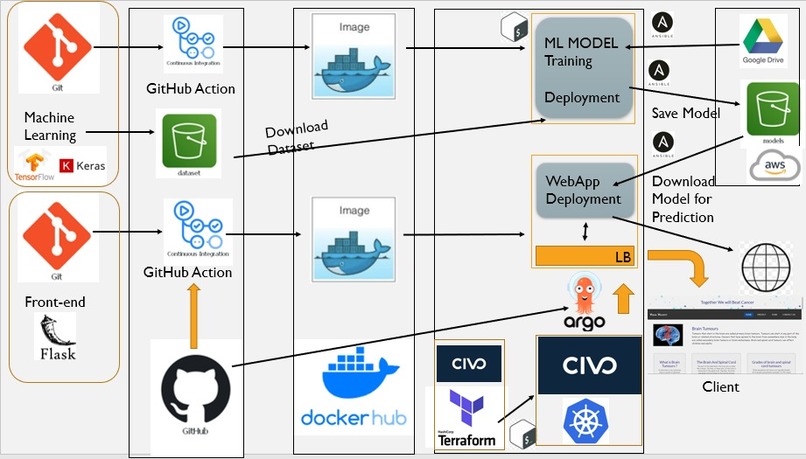
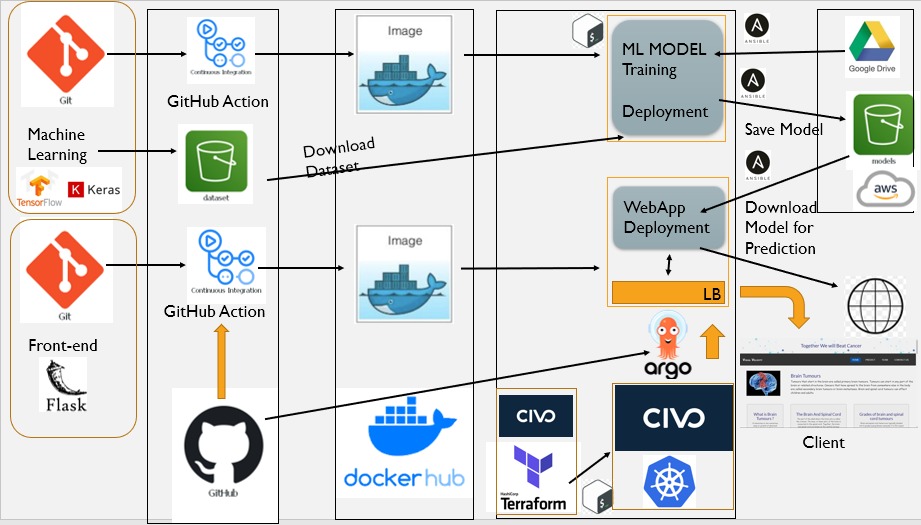
One of many Architectures

Inspiration
Despite the growing recognition of AI/ML as a crucial pillar of digital transformation, successful deployments and effective operations are a bottleneck for getting value from AI. Only one in two organizations has moved beyond pilots and proofs of concept. Moreover, 72% of a cohort of organizations that began AI pilots before 2019 have not been able to deploy even a single application in production. Algorithmia’s survey of the state of enterprise machine learning found that 55% of companies surveyed have not deployed an ML model. To summarize: models don’t make it into production, and if they do, they break because they fail to adapt to changes in the environment.
What it does
- The core activity during this ML development phase is experimentation. As data scientists and ML researchers prototype model architectures and training routines, they create labeled datasets, and they use features and other reusable ML artifacts that are governed through the data and model management process. The primary output of this process is a formalized training procedure, which includes data preprocessing, model architecture, and model training settings.
- If the ML system requires continuous training (repeated retraining of the model), the training procedure is operationalized as a training pipeline. This requires a CI/CD routine to build, test, and deploy the pipeline to the target execution environment.
- The continuous training pipeline is executed repeatedly based on retraining triggers, and it produces a model as output. The model is retrained as new data becomes available, or if model performance decay is detected. Other training artifacts and metadata that are produced by a training pipeline are also tracked. If the pipeline produces a successful model candidate, that candidate is then tracked by the model management process as a registered model.
- The registered model is annotated, reviewed, and approved for release and is then deployed to a production environment. This process might be relatively opaque if you are using a no-code solution, or it can involve building a custom CI/CD pipeline for progressive delivery.
- The deployed model serves predictions using the deployment pattern that you have specified: online, batch, or streaming predictions. In addition to serving predictions, the serving runtime can generate model explanations and capture serving logs to be used by the continuous monitoring process.
- The continuous monitoring process monitors the model for predictive effectiveness and service. The primary concern of effectiveness performance monitoring is detecting model decay—for example, data and concept drift. The model deployment can also be monitored for efficiency metrics like latency, throughput, hardware resource utilization, and execution errors.
How we built it
- We created the architecture to continuously train and deploy the model to production.
- Integrated multiple tool to achieve the continuous training and continuous deployment.
Challenges we ran into
- Flow of Data for training and prediction.
- Managing the data is the really great challenge in Machine Learning Operations. In software development the frontend and backend can be easily deployed with DevOps, Cause we don't have to think about the flow of data
Accomplishments that we're proud of
- Integration of the architecture with AWS S3 to make the flow of data free, We can make data flow possible with the integration of any solution
What we learned
- Integration is the key to make the world better
What's next for MLOps powered by civo
- Create ML Pipelines with Kubeflow on Kubernetes with civo
- We are looking forward to see the ML Applications in the civo marketplace
References & Further Readings
Built With
- argocd
- civo
- devops
- docker
- flask
- gitops
- keras
- kubernetes
- mlops

Log in or sign up for Devpost to join the conversation.