-
-
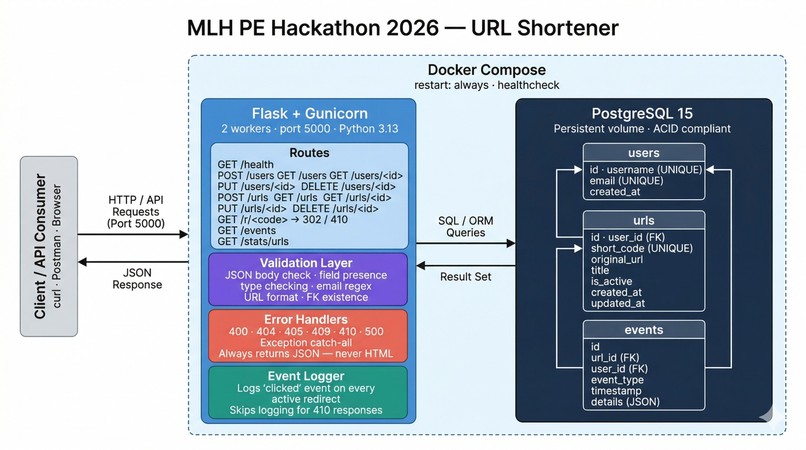
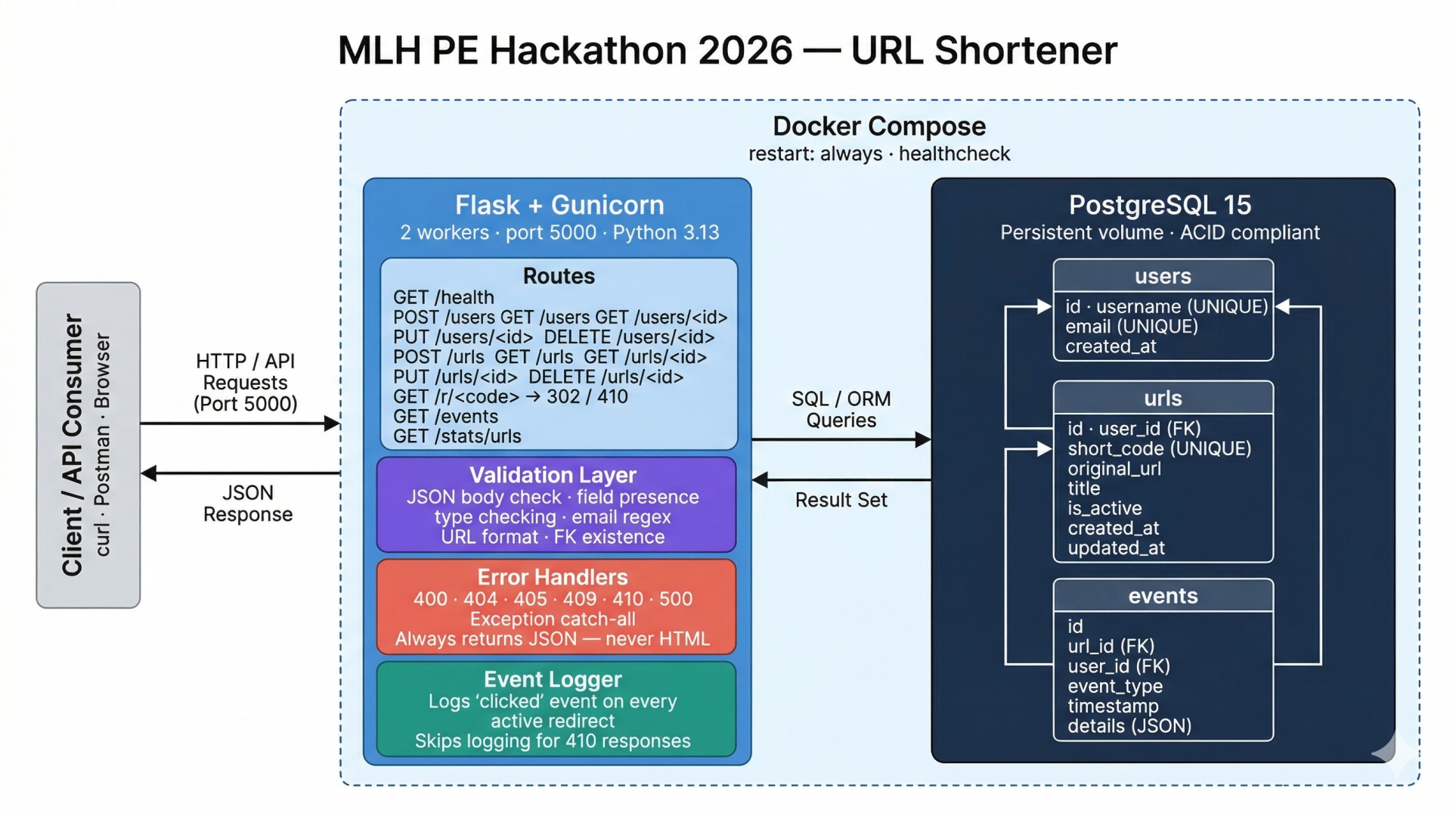
architecture
-
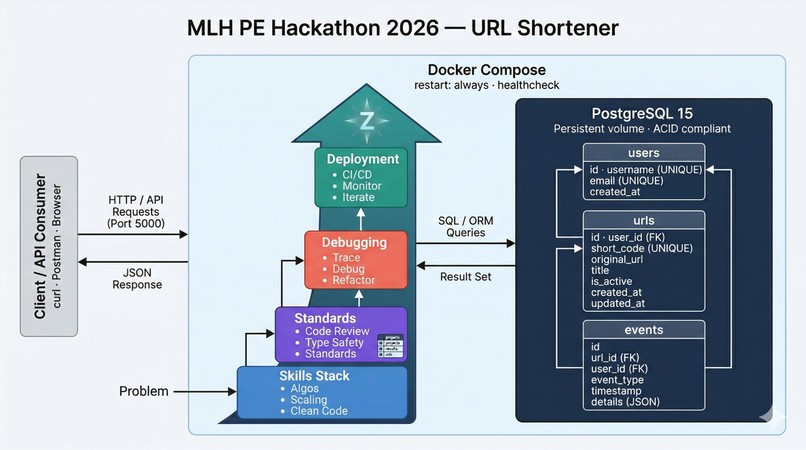
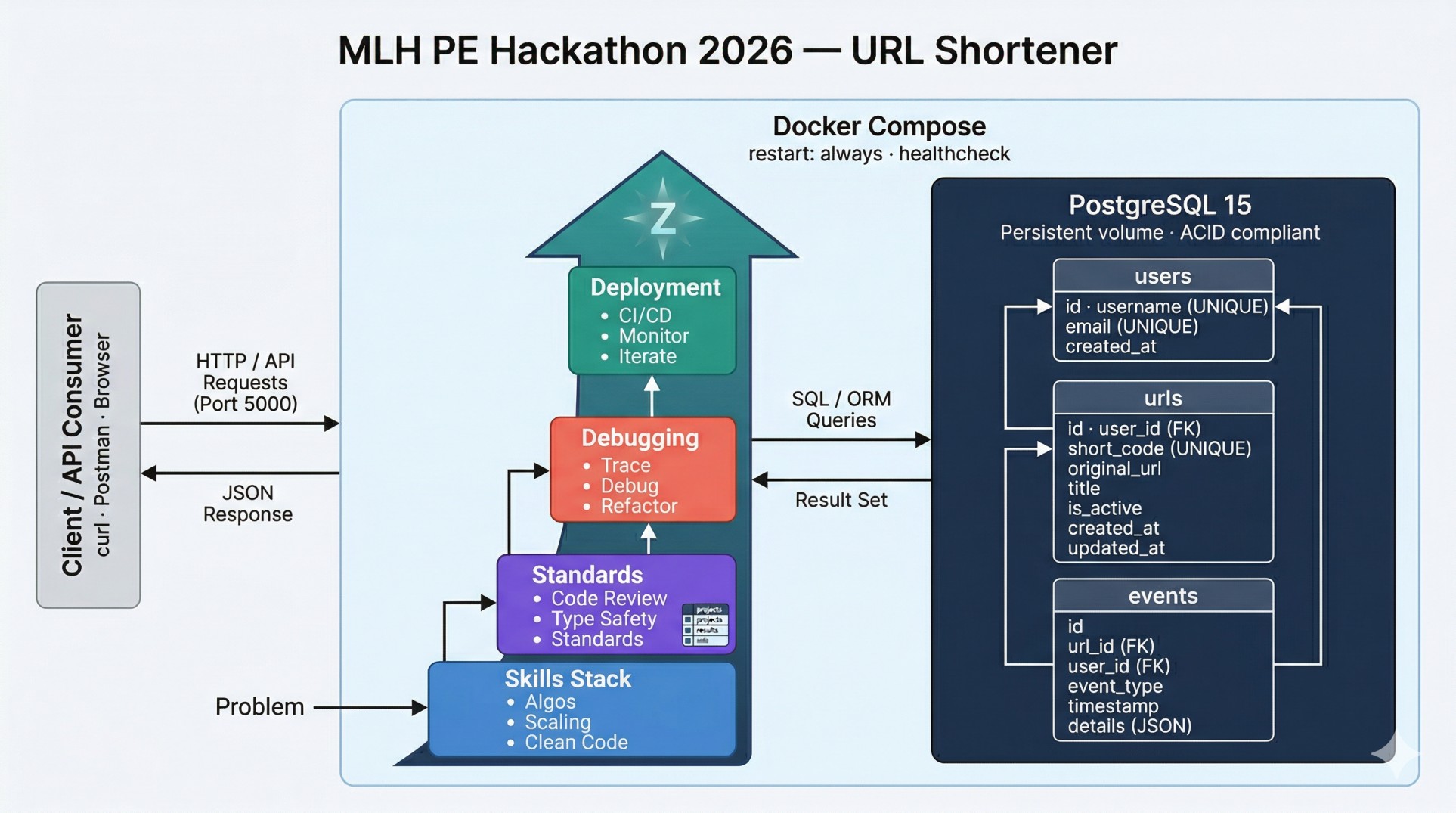
Here is your project story reformatted and expanded to perfectly fit the standard Devpost submission template!
Inspiration
We were inspired by the core challenge of modern Production Engineering: building systems that don't just work under ideal conditions, but fail gracefully when everything is on fire. URL shorteners are deceptively simple—generating a 6-character random string is easy, but ensuring the system remains resilient to concurrent writes, database connection drops, and unpredictable network latency requires serious architectural thought. We set out to take a seemingly simple utility and engineer it to the rigorous, fault-tolerant standards of a professional Site Reliability Engineer (SRE).
What it does
At its core, this is a high-performance URL Shortener and Analytics API. It allows administrators to securely bulk-load users via CSV and exposes a deeply robust CRUD interface for generating heavily validated short links. Beyond just redirecting traffic (via HTTP 302 Found), it actively logs analytics events, handles pagination, and correctly serves terminal states—for example, returning a semantic 410 Gone if an administrator deactivates a short link!
Most importantly, it protects the client experience. No matter what is broken internally (a downed database, a malformed JSON payload, or a duplicate entry), the API will never leak an HTML 500 Internal Server Error traceback.
How we built it
- Backend: We utilized Python and Flask, chosen for their lightweight footprint which allowed us to rapidly iterate on API routing.
- Database: PostgreSQL alongside the Peewee ORM forms our storage layer, providing absolute ACID compliance.
- Containerization: The application is entirely strictly containerized using Docker and orchestrated via
docker-compose. - Pipelines: We tied everything together using GitHub Actions for CI/CD, creating a ruthless gatekeeper pipeline that uses
pytestto reject any pull request that drops test coverage below $70\%$. - Environment Management: We adopted
uvfor lightning-fast, highly reproducible virtual environments.
Challenges we ran into
Handling data race conditions under high concurrency was our biggest threat. When distributing load across multiple Gunicorn workers, the probability of generating a duplicate short code is governed by the Birthday Paradox.
For a short code of length $L = 6$ using a Base-62 alphabet, the total permutations are $N = 62^6 \approx 56.8 \times 10^9$. The collision probability $P(n)$ after generating $n$ URLs grows quadratically: $$P(n) \approx 1 - e^{-\frac{n^2}{2N}}$$
Rather than bottlenecking the app with threading locks, we leveraged our infrastructure. We enforced strict UNIQUE constraints in Postgres and caught IntegrityError exceptions in the Flask routing layer to gracefully return a 409 Conflict.
Another major blocker was DevOps friction limiters: rogue binary coverage files and invisible Unicode tracking bugs were actively crashing our pytest CI environments, requiring a deep audit of our .gitignore and caching logic to fix.
Accomplishments that we're proud of
We are incredibly proud of our operational maturity. We didn't just build an app; we built the observability and resilience to back it up.
We wrote a bespoke chaos_test.sh script that actively seeks out and kills our own application's web containers mid-flight to verify that our Docker restart: always configurations and database retry-logic auto-heal the app under 10 seconds. We successfully achieved a deeply verifiable, highly structured CI/CD pipeline passing all automated SRE checks.
What we learned
We learned the profound difference between "code that works on my laptop" and "production-ready infrastructure":
- Error Contracts: You have to protect the client stringently. Field-level validation returning clean
{ "error": "...", "fields": [...] }dictionaries is vastly superior to generic400 Bad Requestdrops. - Chaos Engineering: Documentation is just a suggestion until it is tested. Actually bringing down databases to review error logs is the only way to prove a system works.
- Determinism: A single untracked
uv.lockfile can completely destroy the reproducibility of a build pipeline.
What's next for MLH Hackathon project - Url Shortener
To evolve this project to the next tier of extreme scalability, we plan to:
- Cache Layer Integration: Introduce a Redis instance to cache hot
GET /r/<code>read requests, protecting the Postgres database from heavy, localized traffic spikes. - Table Partitioning: The
eventstable will grow exponentially. We plan to introduce monthly PostgreSQL table partitions to allow for scalable data archiving and faster analytical queries. - Observability Expansion: Actually wiring up our existing
alerts.ymlPrometheus configurations to a live Grafana dashboard to visualize real-time request latencies and error rates!
Built With
- bash
- docker
- flask
- github-actions
- gunicorn
- peewee
- postgresql
- pytest
- python
- rest


Log in or sign up for Devpost to join the conversation.