Inspiration
I love baseball, but with 2,430 games in an MLB season, it is impossible to watch them all to keep up with the league. I needed a way to get clean, daily statistical insights without manually pulling data or spending hours scrolling through box scores. I chose Track 4: Open Innovation because it gave me the freedom to build a true data engineering solution rather than just a standard web app. This track allowed me to creatively push the boundaries of the Vercel and AWS stack by engineering a hands-off, automated data platform that delivers a clean analytical cheat sheet for the entire league every morning.
What it does
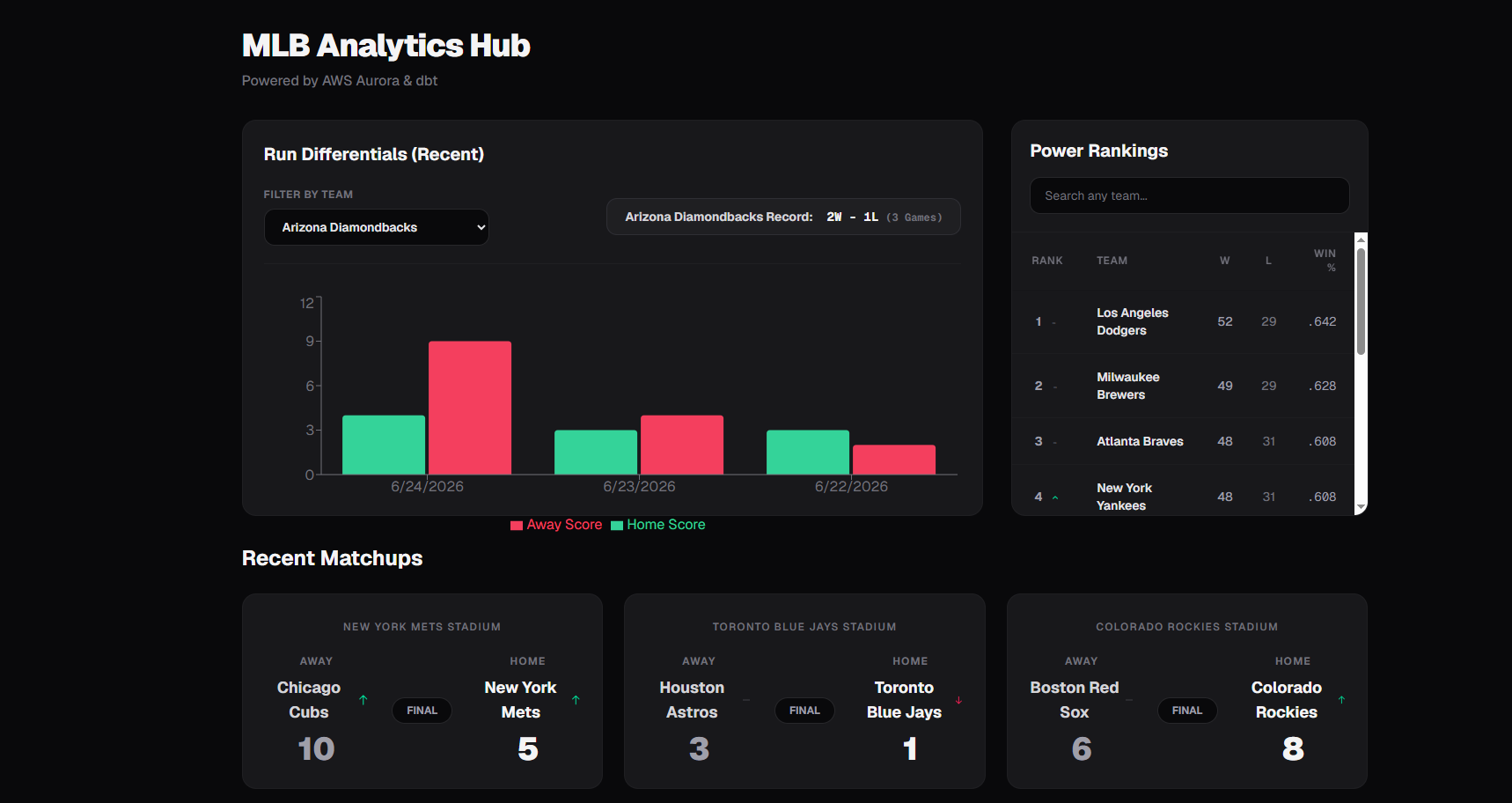
The MLB Analytics Hub is a fully automated ELT (Extract, Load, Transform) data pipeline and full-stack web dashboard. Every morning at 8:00 AM EST, the platform autonomously fetches the previous day's raw MLB game and player statistics, loads them into the cloud, cleans and models the data, and serves the refreshed metrics to a responsive, interactive web dashboard. It eliminates the need for manual data wrangling, giving sports analysts and fans instant access to aggregated league data.
How we built it
I engineered a modern ELT architecture separating data ingestion from data modeling to maximize cloud compute efficiency: Extract & Load: A custom Node.js script runs via a GitHub Actions cron job, asynchronously fetching raw JSON data from external MLB APIs and streaming it directly into an AWS Aurora database. Transform: Once the raw data lands, the pipeline initializes a Python environment and leverages dbt to execute modular SQL transformations inside the AWS database. Aurora handles the heavy computing to clean and aggregate the stats. Serve: The modeled data is queried by a Next.js frontend, which is continuously deployed and hosted on Vercel’s Edge Network for lightning-fast, real-time UI rendering.
Challenges we ran into
The biggest hurdle was orchestrating the CI/CD pipeline to handle a multi-language script. Because the data extractor runs in JavaScript and the dbt transformations run in Python, configuring the GitHub Actions runner to perfectly navigate the nested directory structures to find the correct files required extensive debugging of the runner logs.
Accomplishments that we're proud of
I am incredibly proud of successfully deploying a true ELT architecture. Instead of relying on legacy ETL methods that transform data in memory on a local server, I successfully offloaded the heavy SQL transformation lifting entirely to the AWS Aurora compute engine. Getting the GitHub Actions cron job to execute this multi-step pipeline completely hands-off with zero daily manual intervention was a massive victory.
What we learned
This project was a deep dive into modern cloud data infrastructure. I gained hands-on experience orchestrating dbt within a CI/CD workflow, managing secure cloud database connections via GitHub Secrets,
What's next for MLB Analytics Hub
Now that the daily pipeline is fully automated and stable, the next step is adding predictive analytics.
Built With
- amazon-web-services
- aurora
- dbt
- javascript
- next.js
- postgresql
- python
- sql
- vercel


Log in or sign up for Devpost to join the conversation.