-
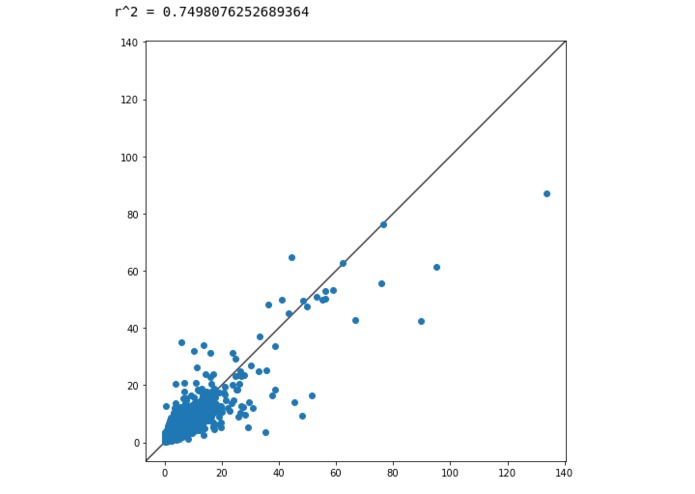
Model Accuracy
-
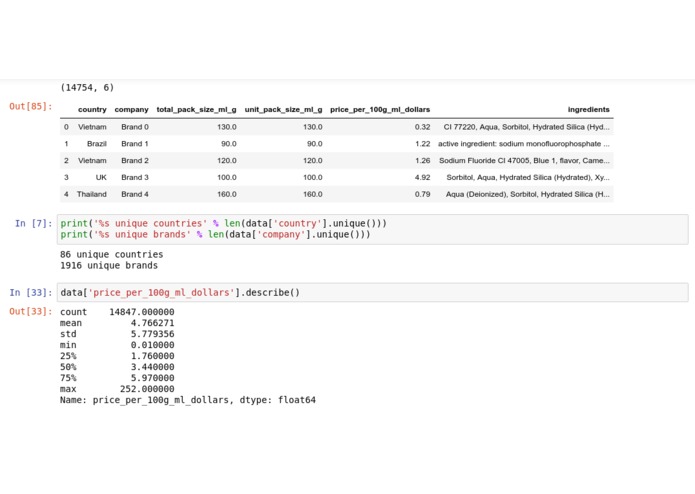
Data Overview
-
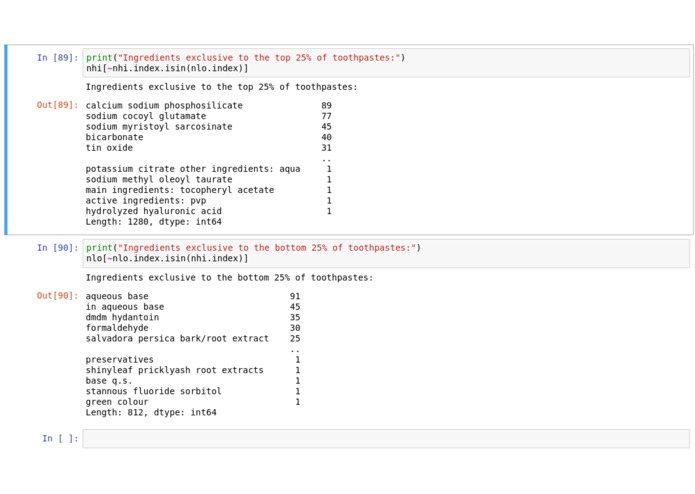
Ingredients Analysis
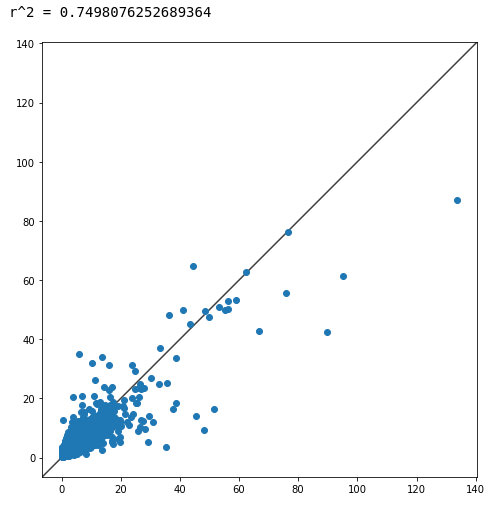
Summary
In essence, we trained a machine learning model to predict the prices of toothpaste given some parameters/market data. Our final model used a Gradient Boost Decision Tree Regression algorithm and achieved a statistically significant accuracy.
Explanation of Features
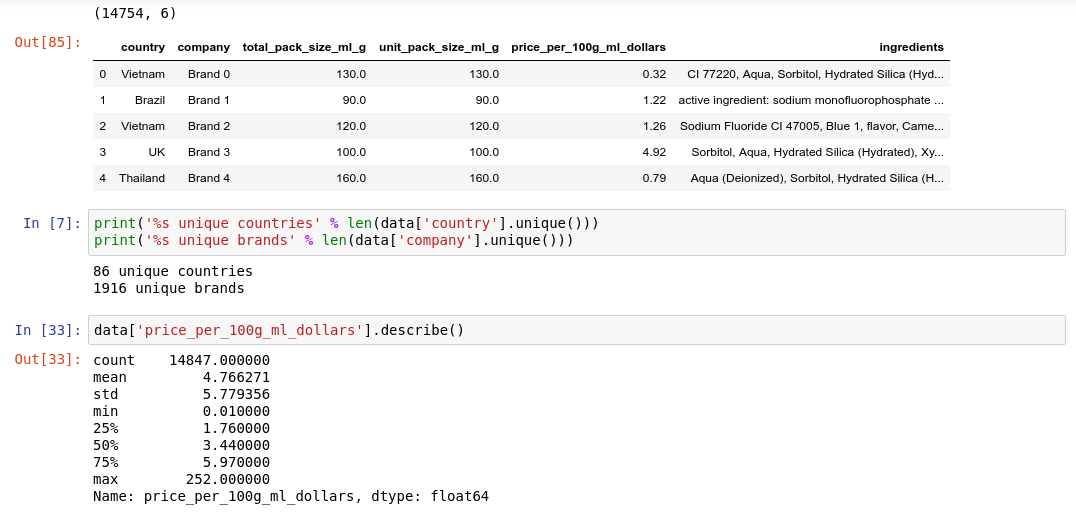
In order to find which parameters had the most feature impact, we first started off by dropping columns from the dataframe and observing which parameters made the most difference in terms of the accuracy of our model. The most significant features were country and brand, which agreed with our initial hypothesis.
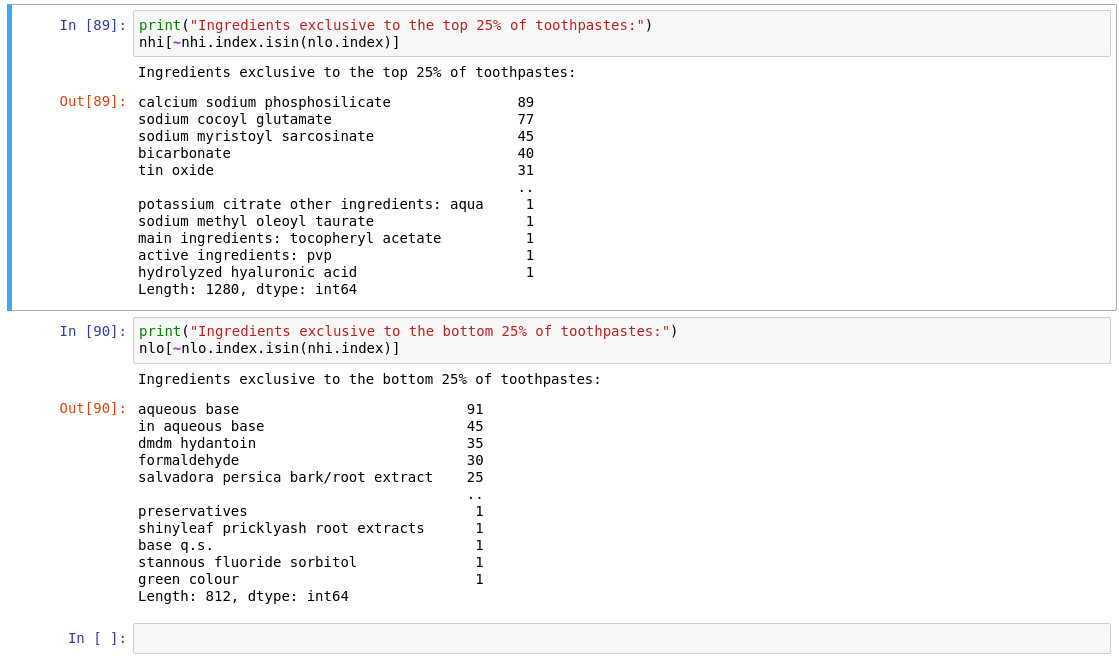
We tried many ways of incorporating the ingredients into our model. Our ideas included computing a global average price for each unique ingredient, and trying to determine if any ingredients were unique to the upper or lower end toothpastes. These tests showed that the average prices of ingredients were all relatively the same, and of the unique ingredients, only 0.6% of them appeared exclusively in higher or lower end toothpastes. In essence, each end of the spectrum shared many commonalities and therefore we concluded that there was not a very high correlation between ingredients and price. Better data might be needed to better differentiate between different types of toothpaste in the model.
We spent a considerable amount of time on processing and parsing the ingredients list for the series but there were still lingering formatting issues we were not able to address, but they didn't have a statistically significant effect on our conclusion.
Applications
The applications of this project are multifaceted. At face value, the model is able to take data for a series of toothpastes and use that data to train itself to predict the price of a new toothpaste with substantial accuracy. The accuracy comes from the numerical parameters already in the data set, but more importantly our transformation of the country and company parameters, and our decision to use a Gradient Boost Regression. This is especially relevant for toothpaste manufacturers who are attempting to break into an emerging market, or even an established manufacturer seeking to price new products. Although there are certainly internal parameters used to price toothpaste that are not included in the data frame, a manufacturer could use this model to decide whether their pricing is inline with the market trend. On the consumer side, an individual could input the parameters of a toothpaste they intend to purchase to gauge whether they are getting a fair price.
Process
Goals
Given a large set of collected toothpaste data, train a regression model to predict the price of new toothpastes. Additionally, validate the model by testing points from the given data set not used to train the model.
First Steps
The team’s first steps were to do exploratory data analysis to get a feel for general trends, numbers, and sizes for the dataset using jupyter/python. We cleaned up the data set to transform the ingredients parameter to a more usable format and deal with missing values in certain columns.
Validation Metrics
To validate the model we decided to use a test/train 25:75 split of the dataset. The model was trained using 75% of the given data, and the remaining 25% of the data that the model had never seen before was used to score predictions. The output of our program was a scatter plot whose dependent variable was the given price of toothpastes, and whose independent variable was our predicted price for those same toothpastes. To evaluate the accuracy of this result we used a least squares regression value (r²) and used visual estimation to assess how close the data fit the line of y = x (perfectly predicted prices). The r² value gives a statistical data point comparing our model to a perfect regression, represented by r² = 1.
Training a Model
Our first challenge with creating a model was to assign meaningful numerical values to non-numerical parameters: country, company, and ingredients. Due to the inherent difficulty of numerically categorizing ingredients our first approach involved only country and company. At first, we label encoded the two categorical variables into arbitrary numerical values, later assigning to a continuous scale based on other metrics. We accomplished this by filtering the list by country and taking the average price per unit of all toothpastes for each country.
For our first naive iteration of the model, we selected a K Nearest Neighbors regression algorithm to fit the data. KNN is a basic regression technique commonly used with machine learning algorithms that has its cons, but was easy to get started with. After retraining, our model achieved r² = .37, which was not a substantial correlation.
We used this same process of taking average price per unit by some category to remap our company labels to a numeric scale and after further training the model achieved r² = .67 for fitting the test data. For most applications .66 is considered nearly substantial, but we felt that we could train a stronger model.
After our first draft we took several measures to improve the accuracy of our model. We recognized that our arbitrary numerical placeholders for countries and companies were skewing the data and decided that would be our first objective. Secondly, we decided that KNN was not a strong enough model because it assumes a linear regression. Finally, we wanted to find a way to process the ‘ingredients’ column of data and use it in our fit.
Our final modification to the model was changing our regression model from KNN to Gradient Boost Decision Tree Regression. While KNN assumes a linear relationship between the feature and target variables, decision trees make no such assumptions and learn arbitrarily complex decision boundaries. Decision trees also prevent overfitting due to collinearity. After shifting to a Gradient Boost regression the model achieved r² = .749, which is generally considered substantially significant.
What We Would Change
We would have experimented with a better transformation on the brand column, possibly as an aggregate of percentiles in each market that the brand is present in. This might more accurately capture the overall rank of the brand within the global market. Another major change we would make is to either incorporate the ingredients list to some effect, or gather more data that more accurately correlates different toothpaste brands to prices.
Built With
- matplotlib
- pandas
- python
- scikit-learn

Log in or sign up for Devpost to join the conversation.