-
-
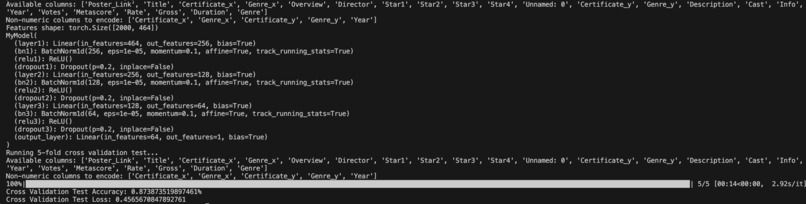
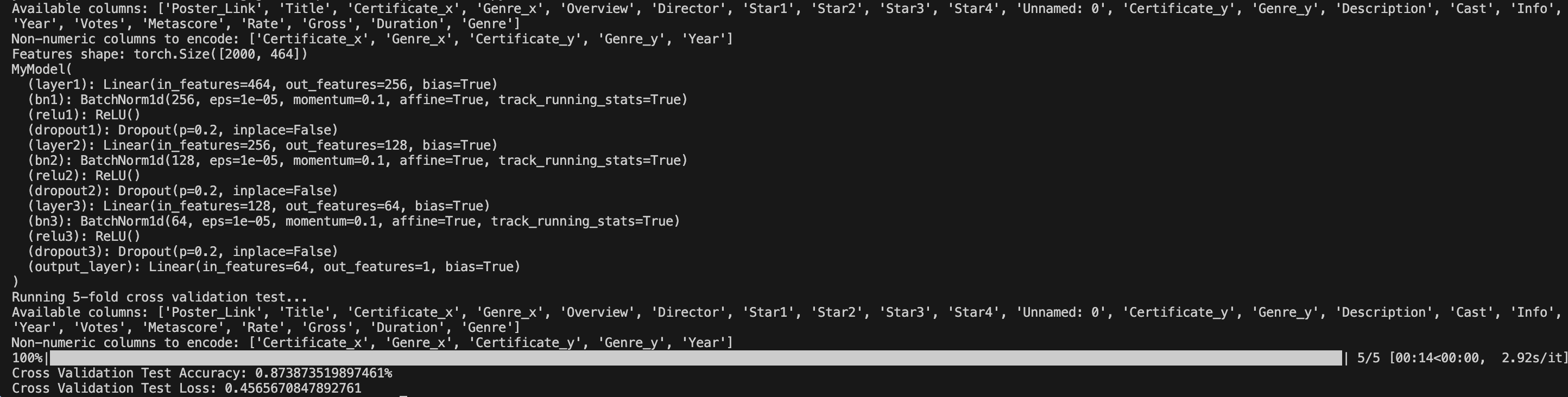
Output from main.py
Inspiration
Movies are a unique blend of art and analytics—while creativity drives storytelling, financial success often hinges on quantifiable patterns. I wanted to explore whether machine learning could bridge this gap. My goal was to build a tool that predicts box office revenue using features like genre trends, audience engagement (IMDb ratings, votes), and critical reception (Metascores), empowering filmmakers and investors to make data-driven decisions.
What It Does
This project is a deep learning model that predicts a movie’s financial success (log-transformed Gross) based on 464 engineered features, including:
- Genre combinations (encoded into 20+ binary columns via MultiLabelBinarizer)
- Log-transformed Votes and Gross to handle skew
- Runtime, Metascores, and IMDb ratings
The neural network achieves 87.3% accuracy (validated via 5-fold cross-validation) and generalizes well across diverse film budgets and genres.
How I Built It
Data Engineering:
- Merged messy CSV files, resolving column conflicts (Certificate_x vs. Certificate_y).
- Extracted Gross revenue from unstructured text in the Info column using regex.
- Applied log transforms and one-hot encoded categorical features.
- Merged messy CSV files, resolving column conflicts (Certificate_x vs. Certificate_y).
Model Architecture:
- Built a 3-layer feedforward neural network (256 → 128 → 64 neurons) with PyTorch.
- Added dropout (20%) and batch normalization to combat overfitting.
- Trained using RMSprop (learning rate 0.0005) and validated with 5-fold cross-validation.
- Built a 3-layer feedforward neural network (256 → 128 → 64 neurons) with PyTorch.
Training:
- Split data into 80% training and 20% validation sets.
- Ran 500 epochs with MSE loss, achieving a final validation loss of 0.458.
- Split data into 80% training and 20% validation sets.
Challenges I Ran Into
- Data Preprocessing: Standardizing inconsistent column names (e.g., Box Office vs. Gross) and handling missing values.
- Feature Extraction: Parsing unstructured text in the
Infocolumn to isolate Gross revenue. - Overfitting: Initial models memorized training data; adding dropout and batch norm was critical.
- Abandoned Experiment: Attempted to analyze director/cast fame using ChatGPT’s API but faced time constraints automating prestige scoring.
Accomplishments I’m Proud Of
- Achieving 87.3% accuracy with a custom neural network.
- Successfully preprocessing messy data into 464 robust features
- Implementing cross-validation to ensure model reliability.
- Transforming a vague idea into a functional tool that could impact real-world film budgeting.
What I Learned
- Data quality > model complexity: Log transforms and genre encoding improved performance more than tweaking layers.
- Regularization is key: Dropout and batch norm turned an overfit model into a generalizable one.
- Optimizers matter: RMSprop outperformed Adam/SGD for this dataset.
- Not all features are worth it: The director/cast fame experiment taught me to prioritize actionable data.
What's Next for ML Movie Gross Prediction
- Integrate external APIs: Automate director/cast fame scoring using tools like ChatGPT or IMDb’s API.
- Real-time data: Pull live metrics (social media buzz, trailer views) for dynamic predictions.
- Deployment: Package the model into a user-friendly web app for filmmakers and studios.
- Explore transformers: Test if attention-based models (LSTMs) better capture temporal trends in release cycles.

Log in or sign up for Devpost to join the conversation.