-
-
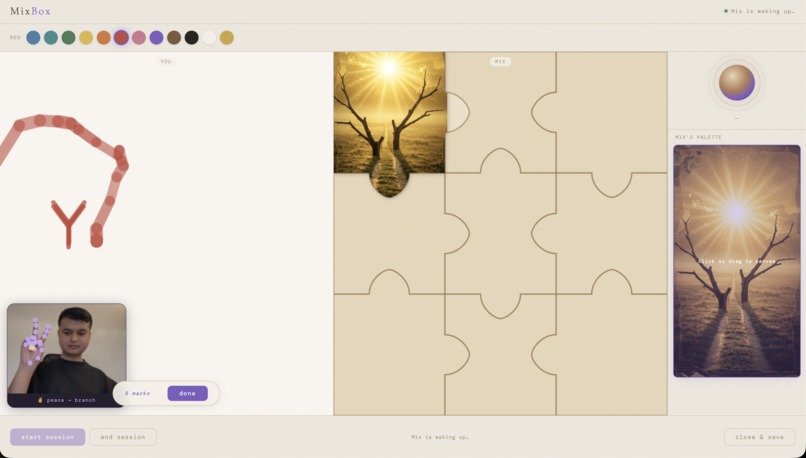
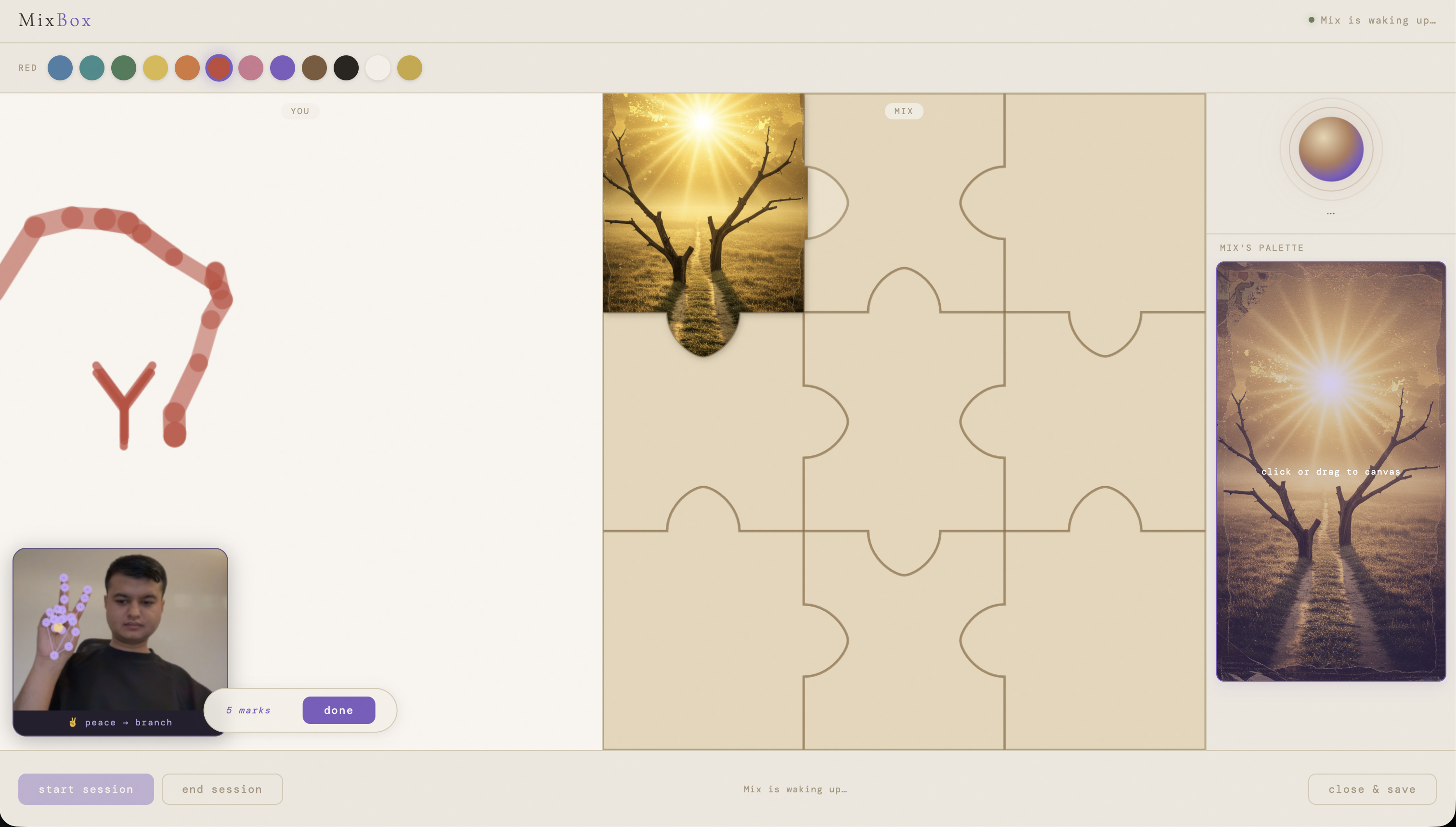
UI Screenshot
MixBox — About the Project
What Inspired This
I've spent time thinking about what it means to actually feel heard by a machine. Most AI products today are impressive but fundamentally transactional — you ask, it answers. There's a text box. You type. It responds. Even the most sophisticated chatbots are still, at their core, a terminal prompt with better grammar.
Art therapy sits at the opposite end of that spectrum. The research of Bessel van der Kolk on trauma and the body, Vija Lusebrink's Expressive Therapies Continuum, and John Diamond's work on body-based awareness all converge on a single idea: healing happens not through explanation, but through embodied expression. The hand moving across paper. The choice of a color before you've consciously named why. The gesture that communicates what language hasn't yet reached.
What struck me is that nobody has built an AI that inhabits this space. Not a therapist — that's not what this is. But a companion. A warm, unhurried presence that watches you make something, listens to your voice, and responds not with advice or analysis, but with genuine witness.
That's what MixBox is.
The idea was simple to state and hard to build: what if the AI was sitting beside you, watching what you make, hearing what you say, and responding as a present, caring friend — not a chatbot? What would it take to make that feel real?
MixBox is a brain-child of my collaborator Maria who fundamentally believed in the power of art-therapy.
What I Built
MixBox is a trauma-informed digital collage therapy platform. At its center is Mix — a live AI companion powered by Gemini Live bidirectional streaming — who:
- Sees the collage canvas in real-time as the user draws and creates
- Hears the user's voice, and responds to what they actually say
- Speaks with warmth, slowness, and genuine presence — observing, reflecting, never diagnosing
- Generates images woven directly into a jigsaw-puzzle canvas, where each piece is created from the user's color choices, hand gestures, and spoken words
The creative ritual moves through intentional stages:
- Mix opens with a single question: "Hi... how are you feeling today?" — and listens fully
- The user picks a color from a palette of twelve
- Mix responds with a brief, warm observation and invites the user to gesture with their hand
- The user draws and gestures using MediaPipe-detected hand poses (a fist, a point, a peace sign, a pinch) — each held for 1.5 seconds to "stamp" a mark onto the canvas
- When ready, the user says "I'm done" or presses the done button
- Mix says "I'll create something for you" — and an image appears, snapping into a jigsaw puzzle slot on the canvas with a subtle pop animation
- Mix asks: "How does it feel... to look at that?"
The canvas fills piece by piece — a jigsaw collage, each tile generated from a distinct emotional moment in the session.
Architecture
The system runs as two independent services on Google Cloud Run, communicating via the ADK Agent-to-Agent (A2A) protocol:
Browser (React + Fabric.js + MediaPipe)
│
│ WebSocket (PCM audio + JPEG canvas frames + canvas actions)
▼
mixbox-main (FastAPI + Gemini Live + ADK)
│
│ HTTP A2A
▼
mixbox-architect (Gemini 2.5 Flash + Imagen 3)
Mix (the mixbox-main service) is the user-facing Dispatch agent. It runs Gemini Live in full bidi-streaming mode — hearing the user's microphone audio and seeing JPEG canvas frames every two seconds. It holds the persona, manages the flow state, and delegates image generation.
The Image Architect (the mixbox-architect service) is a specialist agent that never speaks to the user. It receives structured prompts from Mix — color, gesture poses, and a voice mood transcript — enriches them through a prompt pipeline, and calls Imagen 3. The separation keeps image generation from ever blocking the voice stream.
The prompt enrichment pipeline maps emotional inputs to visual language:
- Color → visual base: blue becomes "deep ocean surface, layered blues, cool depths"; red becomes "volcanic surface, deep crimson, heat and pressure"
- Gesture → quality: a fist becomes "dense and contained, kinetic energy compressed"; a peace sign becomes "two-fingered, branching outward, lightness and division"
- Voice mood → tone: if the user sounds hopeful, the image carries "first light through morning fog"; if anxious, "tangled roots, dense undergrowth"
The final Imagen 3 prompt is always styled as torn paper collage, mixed media, visible brushstrokes, aged paper grain — never photorealistic, never faces, never text. The images are designed to sit inside a jigsaw puzzle and feel like they belong there.
What I Learned
On building live, multimodal AI
The Gemini Live bidirectional streaming API is genuinely unlike anything I've worked with before. Audio, vision, and language are happening simultaneously, in real time, in a single session. The model is hearing your voice while watching your canvas while maintaining a persona and managing conversational context — all at once.
What surprised me most is how sensitive the model is to the system prompt's example distribution. Early in development, Mix would answer every question — no matter how deep or personal — with a 3-5 word poetic fragment. "I see you..." "Something's present today." I couldn't understand why. The "respond fully" instruction was there. But so were twenty examples of short witnessing phrases.
The model learns from examples first, instructions second. The fix wasn't to add more instructions — it was to restructure the prompt so that conversational examples appeared before witnessing examples, and to include explicit WRONG/RIGHT pairs showing exactly what deflection looks like versus genuine engagement. Once I did that, Mix transformed.
On the difference between witnessing and deflection
This is the hardest design problem in the project and the most interesting one. Mix needs to be quiet and observant when someone is creating in silence — that stillness is valuable, not a bug. But the moment someone speaks to Mix, the mode has to shift completely. Not gradually. Immediately.
Getting a language model to genuinely hold two such different response modes — and to switch between them in real time based on whether the human is speaking or silent — required much more explicit prompt engineering than I expected. The solution was treating them as named, distinct modes with their own rules, rather than a single voice that adjusts its length.
On the send_realtime vs send_content distinction
This was a subtle but important technical insight. In the Gemini Live ADK:
send_realtimecarries passive context — audio frames, image frames. The model receives them but does not automatically respond.send_contentis a conversational turn. It prompts a response.
Early versions of MixBox sent canvas frames via send_content, which caused Mix to speak every two seconds — one observation per JPEG, in an endless torrent. Moving canvas frames to send_realtime made them passive visual context, and the voice stream became what it should be: quiet unless there's something genuine to say.
On voice activity detection and echo
One subtle bug cost me several hours: the browser's ScriptProcessor node was connected directly to the AudioContext destination, which routed the user's microphone back through their speakers. This created a feedback loop that confused Gemini's voice activity detection — the model was hearing its own output treated as new speech input, which suppressed or mangled responses. Fixing it was simple (a silent GainNode between the processor and destination), but finding it required understanding the entire audio pipeline from browser to model.
Challenges I Faced
Making an AI feel genuinely warm
This was the challenge I underestimated most. It's not hard to make an AI sound warm. It's very hard to make it feel warm. The difference is whether it's actually responding to you — to the specific thing you said, the specific color you picked, the specific moment — or whether it's pattern-matching to "warm sounding response."
The research foundation helped. Van der Kolk's work on embodied trauma processing, Lusebrink's Expressive Therapies Continuum, and Diamond's body-awareness work all point toward the same thing: presence is not about what you say. It's about what you receive. Mix had to be built to receive first, then respond — not to reach for the nearest warm phrase.
Concretely, this meant removing every hard cap on response length, banning specific words ("wonderful", "amazing", "beautiful" — all performance, not presence), and writing explicit instructions against deflection. The system prompt grew and shrank many times before it reached something that felt right.
The jigsaw canvas
The jigsaw puzzle canvas was the most technically demanding piece of the frontend. Each of the nine slots is a custom SVG path — cubic Bézier curves with interlocking tabs and blanks, deterministically seeded so adjacent pieces always fit. Generated images are clipped to their jigsaw shape using Fabric.js's absolutePositioned: true clipPath, which keeps the clip fixed regardless of how the image scales or moves during the snap animation.
The snap animation itself required fabric.util.animate with easeOutBack easing — the image arrives at 1.2× scale and overshoots slightly before settling, which creates the tactile "snap" feeling that makes each new image feel like it belongs in the puzzle.
The hardest bug was the puzzle appearing in the top-left corner of the canvas, occupying a tiny fraction of the space. The issue: clientWidth and clientHeight were being read inside useEffect before the CSS grid had computed its layout. The fix was a ResizeObserver that defers canvas initialization until the container reports non-zero dimensions.
Keeping the system stable under pressure
The submission deadline creates a specific kind of pressure that changes how you make decisions. After March 10, no new features — only bugfixes and polish. The hardest thing was holding that line. Every interesting idea that came up in the final week had to be evaluated against a single question: does this make the demo more reliable, or less?
The voice "done" detection that was removed and reintroduced several times is a good example. The first version used apostrophe-stripped tokenization to catch "I'm done" → "im done", which failed on contractions and ambient speech. Rather than make it cleverer, I simplified it to a short phrase list and added an explicit done button that always works. Reliability over cleverness, every time.
The Thing I'm Most Proud Of
Not the architecture. Not the jigsaw animation. It's the moment — which I've seen happen consistently in testing — when someone picks a color, Mix says something specific and quiet about it, and the person pauses. Not because they're waiting for instructions. Because they actually felt seen.
That's what this is for.
Built solo for the Gemini Live Agent Challenge — Creative Storyteller track. Stack: React + Fabric.js + MediaPipe · FastAPI + Google ADK · Gemini Live 2.5 Flash · Imagen 3 · Cloud Run · Firestore
Built With
- fabric.js
- fastapi
- javascript
- mediapipe
- python
- react
- vertex


Log in or sign up for Devpost to join the conversation.