-
-

Frontpage of Mitate
-

Screen Loading
-
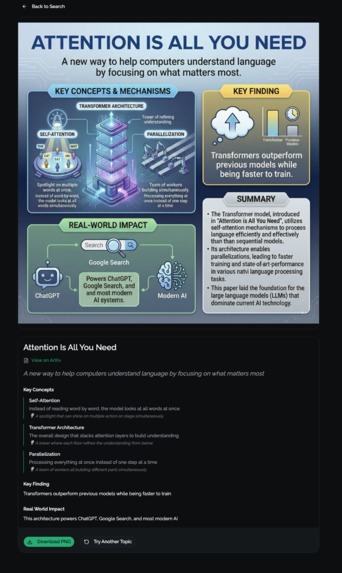
Final Results


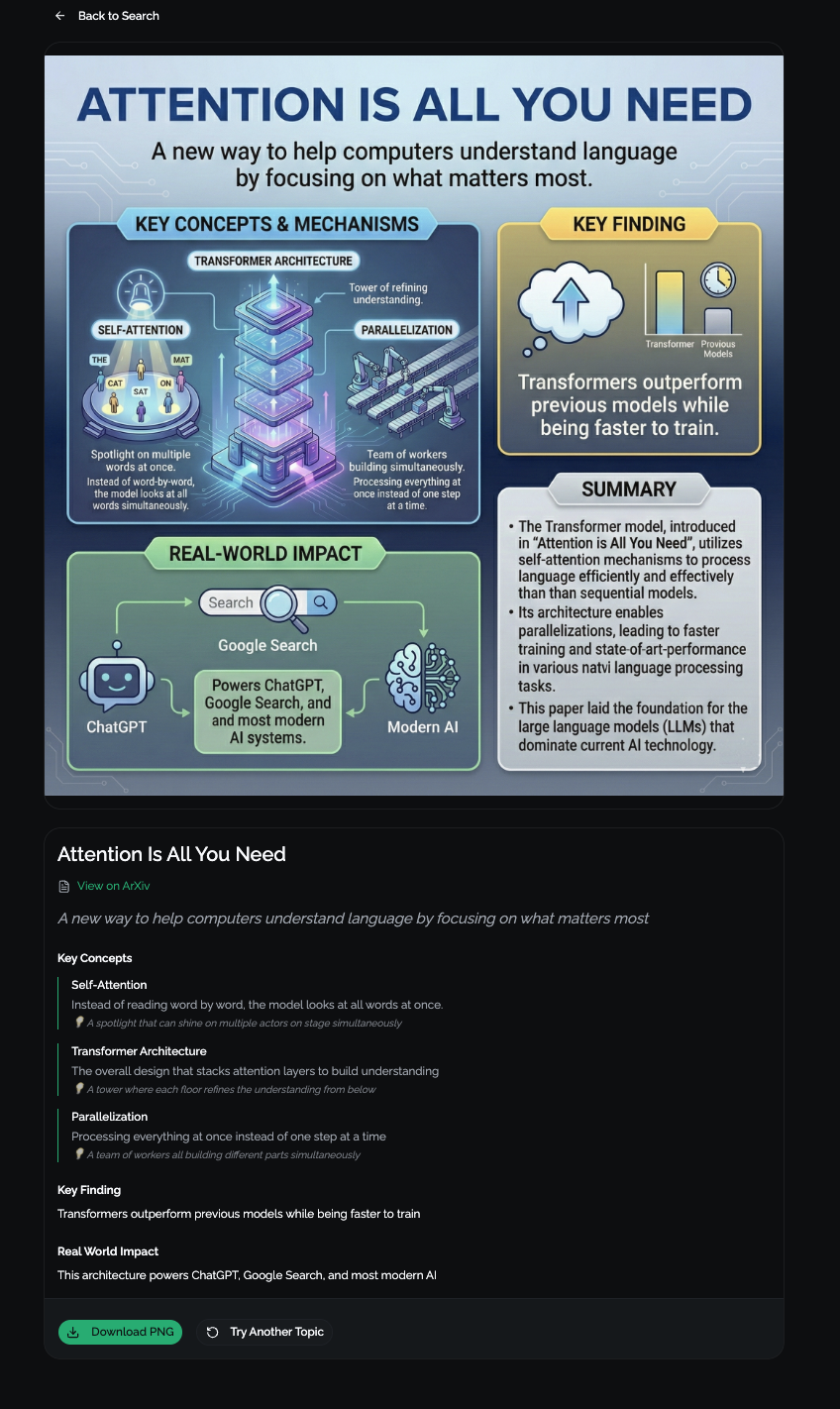
Inspiration Making complex logic and structured knowledge accessible to everyone—regardless of age, background, or domain expertise.
What it does Mitate transforms dense textual knowledge (like academic papers or formal ontologies) into clear, visually engaging infographics that accelerate understanding and learning.
How we built it We built Mitate using a multi-stage pipeline that combines open-source large language models (LLMs) for knowledge extraction and structuring, followed by an open-source image generation system to produce intuitive visual summaries.
Challenges we ran into Early outputs suffered from low-quality ("sloppy") visuals and sometimes extracted irrelevant or overly technical snippets from sources like FIBO/BIRA, making the infographics hard to interpret for non-experts.
Accomplishments that we're proud of Successfully integrating a full-stack workflow—from ArXiv paper ingestion and semantic search to automated infographic generation—using open-source tools and cloud infrastructure.
What we learned We gained hands-on experience with a wide range of technologies: fine-tuning LLM pipelines, deploying serverless functions on DigitalOcean, designing robust APIs, and orchestrating text-to-image generation at scale.
What's next for Mitate We plan to expand beyond ArXiv by incorporating current affairs, open-source documentation, and community-driven knowledge bases. Future work includes supporting multi-paper synthesis, enhanced search relevance, and interactive, dynamic infographics that adapt to user needs.
Built With
- appwrite
- digitalocean
- digitaloceanapphosting
- digitaloceandatabase
- javascript
- llm
- tanstack
- typescript

Log in or sign up for Devpost to join the conversation.