
Misty - Personal Knowledge Assistant
Inspiration
I got tired of hunting through folders for that one file I needed. Between codebases, PDFs, CSVs, and cryptically named files, I'd waste too much time searching. I needed something that could actually understand what was in my files, not just what they were called.
What it does
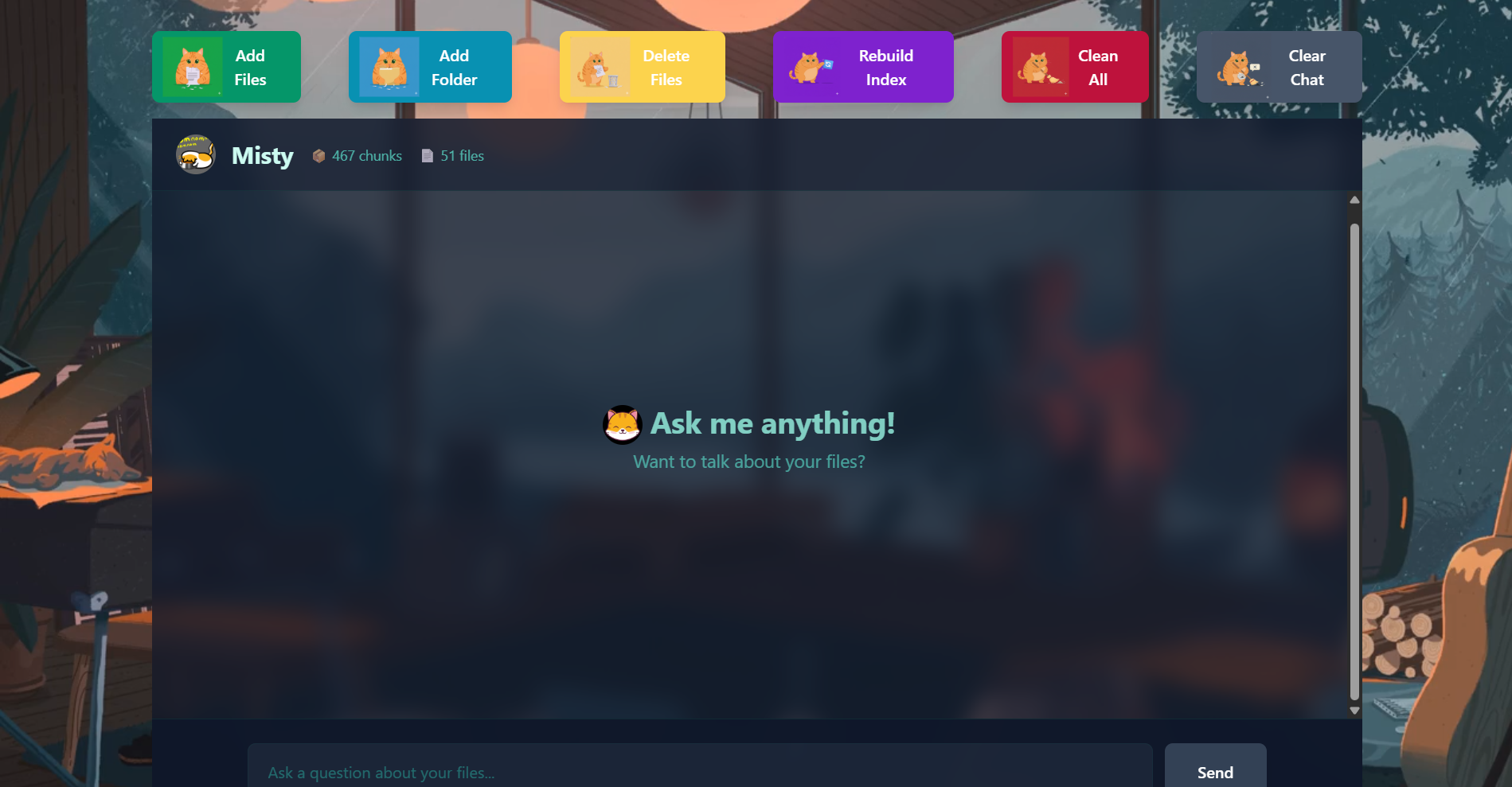
Misty is a local-first RAG (Retrieval-Augmented Generation) bot that runs entirely on your machine. No cloud, no data leaving your computer. It indexes your files and folder structures (up to 1,000 files) so you can ask questions in plain English and actually get answers.
Supported formats: PDF, DOC, DOCX, TXT, Markdown, CSV, JSON, XML, YAML, Python, JavaScript, TypeScript, JSX, TSX, C, C++, Java, C#, Kotlin, Ruby, Go, Rust, PHP, Swift, HTML, CSS, and more.
How I built it
Backend: FastAPI with Python
Vector Database: ChromaDB for storing embeddings
Embeddings: Sentence Transformers (all-MiniLM-L6-v2)
RAG: LlamaIndex for document processing and retrieval
LLM: Local Phi3:mini via Ollama
File Processing: Custom readers for PDFs, DOCX, CSVs, and various code formats
Challenges I ran into
Multi-format file handling: Getting PDFs, Word docs, code files, and CSVs to play nice together took some work.
Code-aware chunking: My first attempt split functions in half, which was useless. Fixed it by implementing language-specific splitters that respect code structure.
Smart folder filtering: Indexing node_modules and venv was a disaster. Added a blacklist system that dramatically improved performance and relevance.
Query intent recognition: "Show me the code" vs "where is this file" vs "open this file" required careful parsing to give the right response.
Local-first architecture: Keeping everything on-device while maintaining speed meant choosing lightweight models and optimizing the embedding pipeline.
Metadata management: Tracking file paths, projects, and keeping things consistent when files change required a solid metadata system.
Accomplishments that I'm proud of
True privacy-first: Everything runs locally. Your files never leave your machine.
Natural language file opening: You can describe a file in plain English and Misty will open it. Works across Windows, macOS, and Linux.
Language-aware code processing: Understands 15+ programming languages and keeps your functions and classes intact when indexing.
Comprehensive format support: From Python to PDFs to presentations—if you've got it, Misty can read it.
Pipeline caching: Reuses processing configurations for similar files, making indexing way faster.
Smart deduplication: Returns relevant chunks without drowning you in repetitive results.
What I learned
RAG systems: Chunking strategies, embedding selection, and context window management matter more than I thought.
Vector databases: ChromaDB's metadata filtering and similarity search are powerful once you understand them.
File formats are messy: PDFs are inconsistent, DOCX needs special handling, code needs structure preservation.
Local LLMs: Working with Ollama taught me how to optimize prompts for smaller models like Phi3:mini.
Cross-platform dev: File operations that work everywhere require platform-specific logic.
API design: Built a clean REST API with FastAPI, including streaming responses and proper error handling.
What's next for Misty
Better UI: Syntax highlighting, file previews, and a more polished frontend.
Semantic code search: Use ASTs for deeper code understanding beyond text matching.
Real-time indexing: Watch for file changes and update the index automatically.
Git integration: Answer questions like "What changed in this function between commits?"
Team sharing: Let users share knowledge bases with teammates (while keeping data local).
Advanced filters: Search by date, file size, or specific projects.
Export functionality: Turn search results and answers into documentation.
Plugin system: Let users add custom file readers and processors.
Built With
- fastapi
- llamaindex
- ollama
- react

Log in or sign up for Devpost to join the conversation.