
Inspiration
The inspiration for Misty came from my own struggles with organization across various codebases, PDF assignments, CSVs, and files with ambiguous naming conventions. I found myself constantly searching through countless folders, unable to quickly locate specific files or understand what my past code did. I needed a solution that could understand my files by their content, not just their names.
What it does
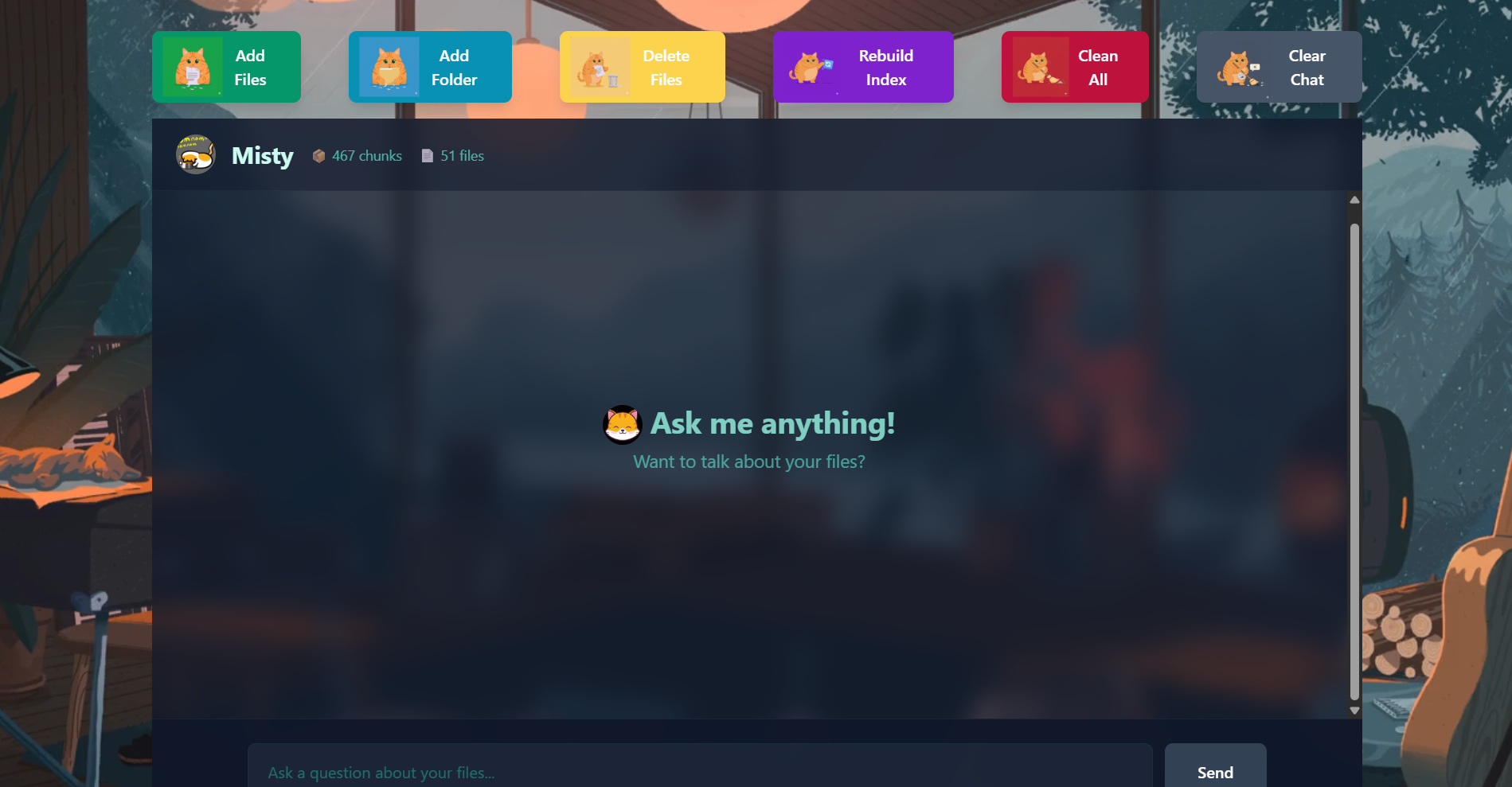
Misty is a local-first RAG (Retrieval-Augmented Generation) bot that prioritizes privacy by running entirely on your machine. It intelligently processes your files and entire folder structures, including nested folders containing up to 1,000 files. Supported File Formats:
Documents: PDF, DOC, DOCX, TXT, Markdown Data Files: CSV, JSON, XML, YAML Code Files: Python, JavaScript, TypeScript, JSX, TSX, C, C++, Java, C#, Kotlin, Ruby, Go, Rust, PHP, Swift, HTML, CSS, and more
Key Features:
Query files by description—no need to remember exact filenames Get file paths based on content descriptions alone Open files directly by describing what they contain Retrieve complete code implementations from your codebase Ask questions about assignments, functions, or any document content Everything runs locally—your data never leaves your machine
How I built it
I built Misty using a modern tech stack centered around Python and FastAPI for the backend: Core Technologies:
Backend Framework: FastAPI with Python for building the REST API Vector Database: ChromaDB for persistent storage of document embeddings Embeddings: Sentence Transformers (all-MiniLM-L6-v2) for converting text to vector representations RAG Framework: LlamaIndex for document ingestion, chunking, and retrieval LLM: Local Phi3:mini model running via Ollama for generating responses File Processing: Custom readers for PDF, DOCX, CSV, and various code formats
Challenges I ran into
Multi-format file handling: Supporting diverse file formats (PDFs, Word docs, code files, CSVs) required integrating multiple specialized readers and ensuring they all worked seamlessly together. Code-aware chunking: Initially, code files were being split mid-function, breaking context. I solved this by implementing language-specific CodeSplitter that respects syntactic boundaries, ensuring functions and classes remain intact. Smart folder filtering: Indexing everything was inefficient and cluttered results with dependency files. I implemented a blacklist system to exclude folders like node_modules, venv, and build directories, dramatically improving relevance and performance. Query intent recognition: Distinguishing between "show me the code," "where is this file," and "open this file" required careful keyword analysis and conditional logic to provide the right response type. Local-first architecture: Ensuring everything runs locally while maintaining good performance meant carefully selecting lightweight models (Phi3:mini) and optimizing the embedding pipeline. Metadata management: Tracking file paths, projects, splitter types, and maintaining consistency when files are updated or deleted required building a robust metadata system within ChromaDB.
Accomplishments that I am proud of
True privacy-first design: Built a fully local RAG system that never sends user data to external servers—everything from embeddings to LLM inference happens on the user's machine. Intelligent file opening: Successfully implemented cross-platform file opening (Windows, macOS, Linux) that works purely from natural language descriptions. Language-aware code processing: Created a sophisticated chunking system that understands 15+ programming languages and preserves code structure for better retrieval. Comprehensive file format support: Integrated readers for documents, presentations, data files, and code—handling everything from Python to C# to Markdown. Dynamic pipeline optimization: Built a caching system for ingestion pipelines that reuses configurations for files with similar characteristics, significantly improving indexing speed. Smart context retrieval: Implemented a scoring system that ranks chunks by relevance and deduplicates results to provide the most useful context without overwhelming the LLM.
What I learned
RAG system design: Learned the intricacies of building retrieval-augmented generation systems, including chunking strategies, embedding selection, and context window management. Vector databases: Gained deep understanding of ChromaDB's architecture, metadata filtering, and efficient similarity search. File format processing: Discovered the challenges and solutions for extracting text from various formats—PDFs are tricky, DOCX requires special handling, and code needs structure preservation. Local LLM deployment: Learned to work with Ollama for running local language models and optimizing prompts for smaller models like Phi3:mini. Cross-platform development: Implemented platform-specific logic for file operations that work seamlessly across Windows, macOS, and Linux. API design patterns: Built a clean REST API with FastAPI, implementing streaming responses, proper error handling, and CORS configuration.
What's next for Misty-Personal Knowledge Assistant
Multi-language UI: Build a more sophisticated frontend with syntax highlighting for code snippets and better file preview capabilities. Semantic code search: Implement more advanced code understanding using abstract syntax trees (AST) for deeper semantic analysis. Incremental indexing: Add file watching capabilities to automatically detect and index new or modified files in real-time. Git integration: Connect with Git history to enable questions like "What changed in this function between commits?" Collaborative features: Allow sharing of knowledge bases (while maintaining privacy) with team members for collaborative learning. Advanced filtering: Implement date-based queries, file size filters, and project-specific search scopes. Export functionality: Add ability to export search results, code snippets, and answers as organized documentation. Plugin system: Create an extensible architecture for users to add custom file readers and processing log
Built With
- fastapi
- javascript
- ollama
- python
- react

Log in or sign up for Devpost to join the conversation.