-
-
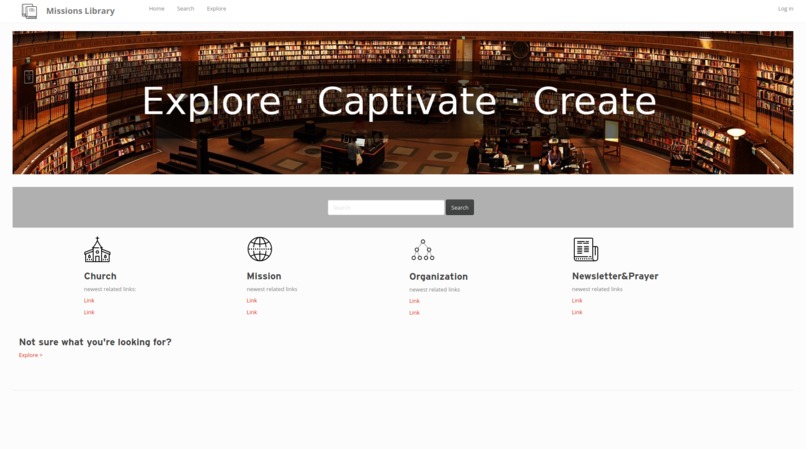
Home Page
-
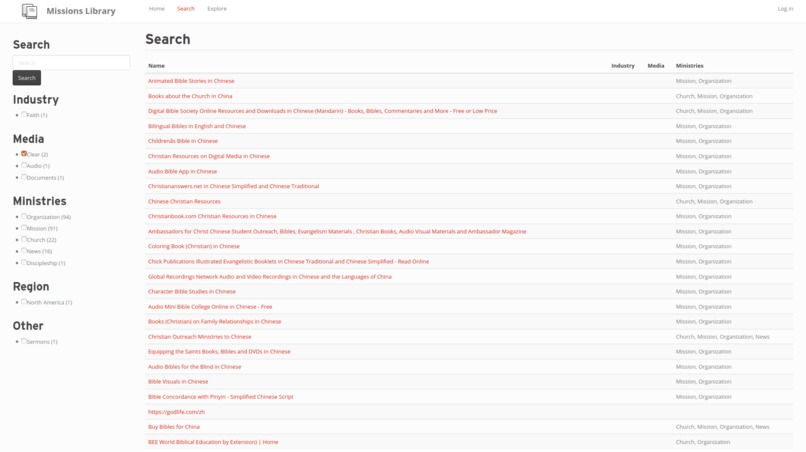
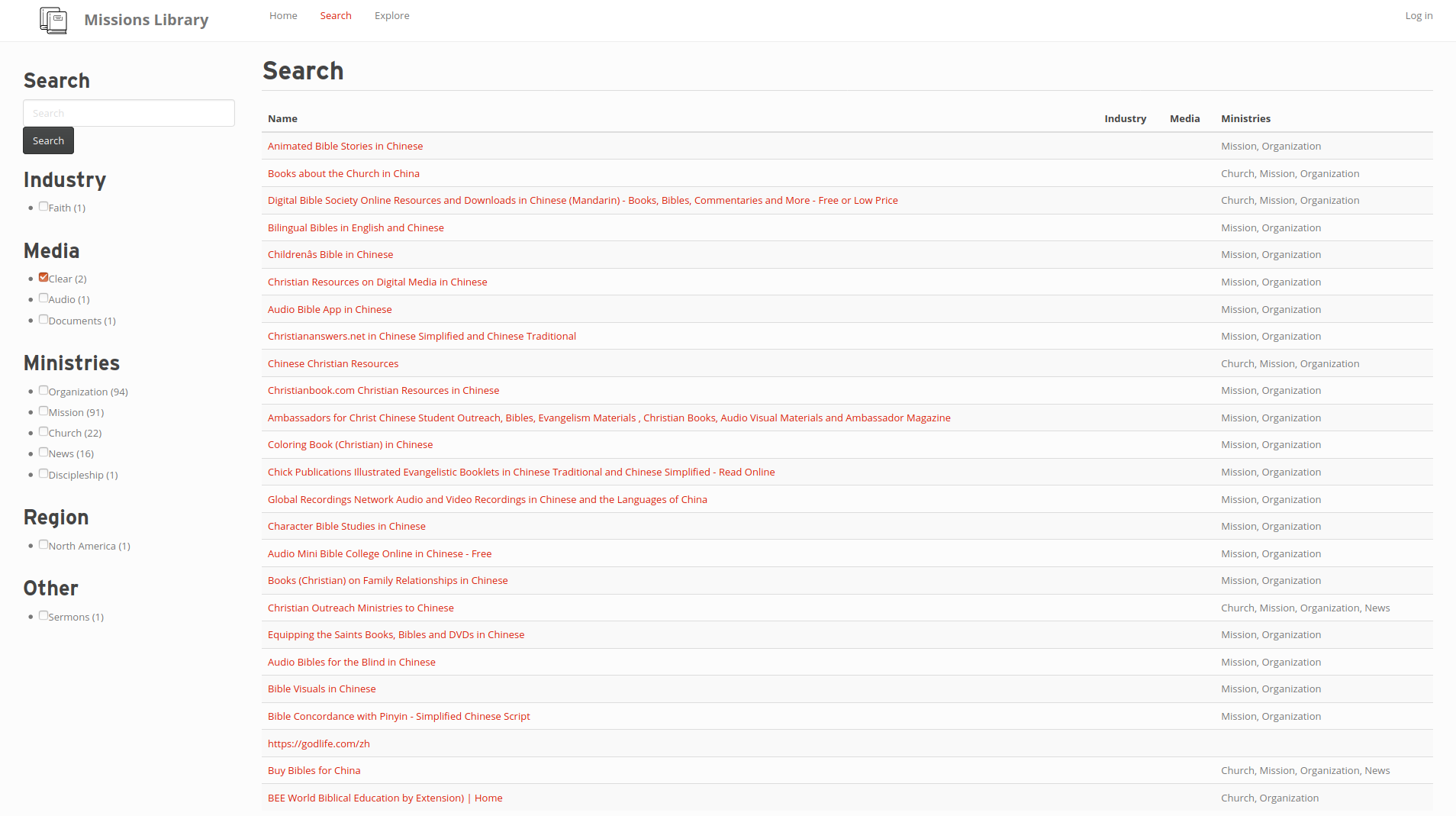
Search
-
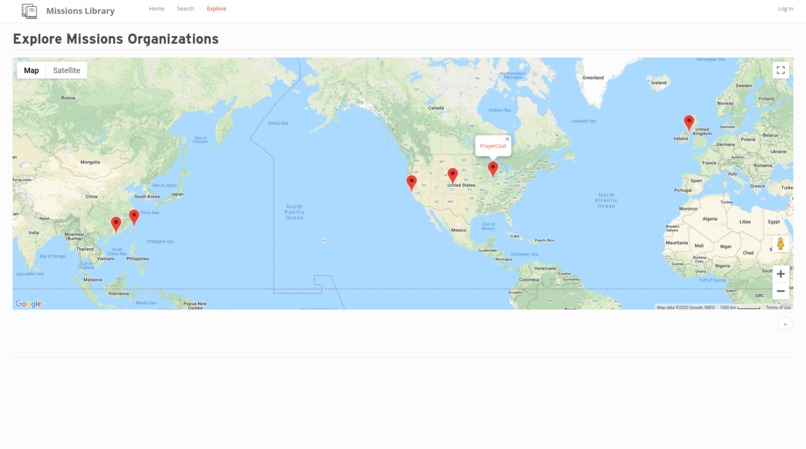
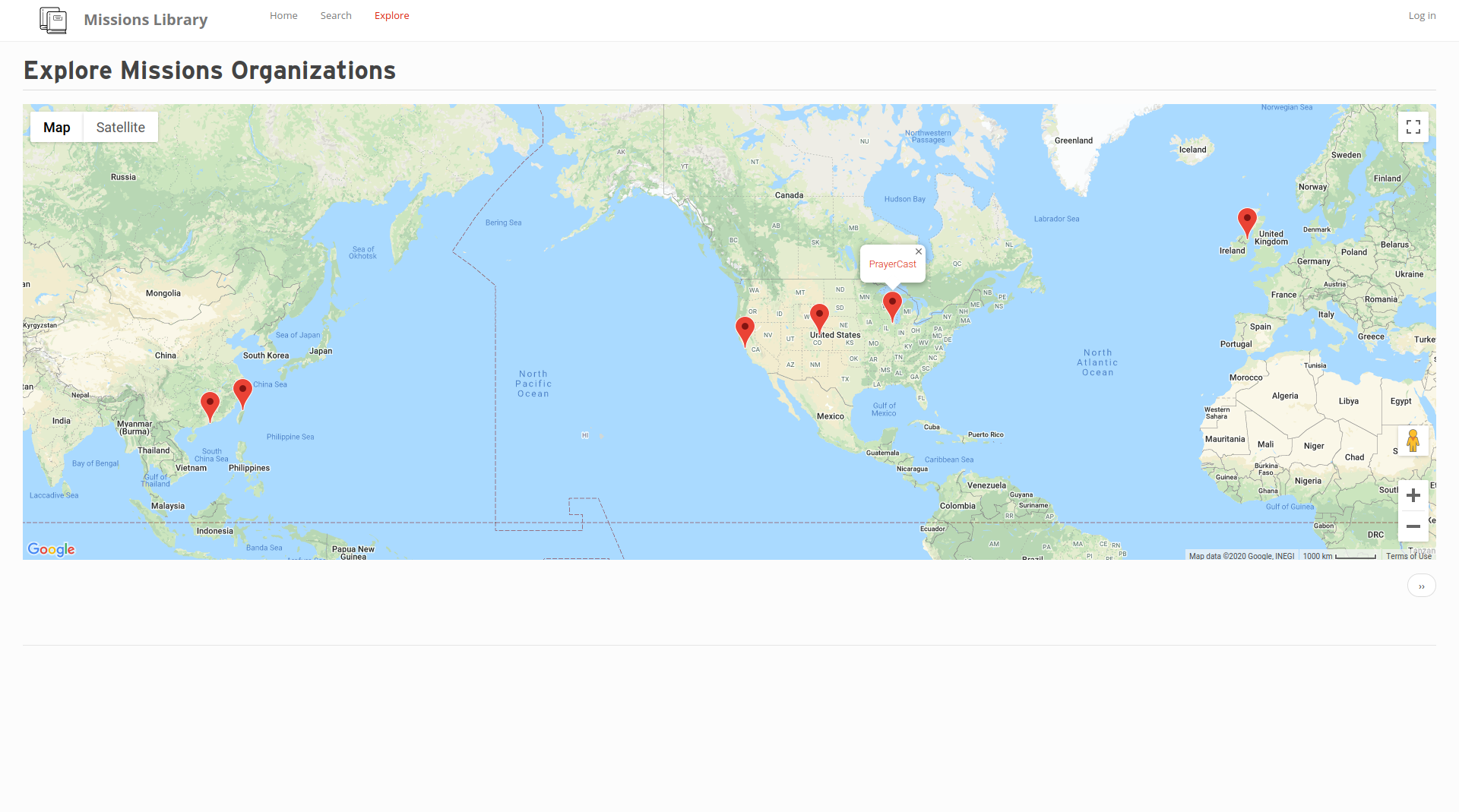
Map of Organizations
Inspiration
Curated Search
Before working on Missions Library specifically, I was having trouble with the major search engines when looking for websites I know are still in existence, and are merely old (10-15 years). Since SEO has come a long way relative to how sites were constructed originally, there are a number of great works and resources that are being left behind. This gave me an interest in developing search engines that could be managed by "search communities," and that these engines could be linked together in a manner similar to how Reddit links many thousands of discussion groups together. We could surface these sites again, and possibly come up with a way to pair students with site owners to modernize these resources.
Missions Library
While talking with a member from Cru (Andrew Feng), I was surprised at his depth of knowledge about missions resources, including many sites that could benefit from curated search. Thus the idea for MissionsLibrary.org was born. We could focus specifically on missions resources, thus making content readily available for missionaries and mentors, and we could also help existing organizations find opportunities to collaborate.
What it does
MissionsLibrary.org is a digital library and atlas. Visitors will be able to search a digital catalog of web pages, as well as a map of missions organizations. For data input, we have also developed an enhancement to the Zeomine Web Crawler to generate import files that allow us to bulk import hundreds of links at a time, with rudimentary tagging information to enable more in-depth search.
How I built it
MissionsLibrary.org is built on the Volunteer Center distribution of the Drupal CMS, Apache Solr, and the Python-based Zeomine Web Crawler. MissionsLibrary.org was built by making targeted enhancements to Volunteer Center and Zeomine, specific to the needs of our project.
Challenges I ran into
As the team leader, one challenge I saw was my own lack of documentation for the open source projects we would be building on. After this hackathon, I took notes on which features need to be better documented for new contributors. One other challenge was communications over the tagging system - our UI/UX team developed several tags the crawl team were not able to program for, given the time frame, but after some negotiation we picked one set of tags as a proof-of-concept.
Accomplishments that I'm proud of
Some of the team members have never performed coding before, and were able to understand the Drupal CMS and become contributors quickly. I could also leave sub-teams alone and they could manage themselves. At the end, some students were also talking in terms of what they may like to do for projects of their own, given what they have learned from the hackathon. At the end some students were also sharing some major life questions and life stories, and even after we "finished" we stayed on to pray for each other.
Something I mentioned to one organizer before starting was that "the least important outcome of a hackathon is the code." To be sure, MissionsLibrary.org looks good and will be an excellent contribution to the world of missions, but the discussions, new perspectives, and learning about how to develop and manage a project were in my view the greatest accomplishment.
What I learned
As a team leader, I learned that one expectation I had at the beginning was true: for a hackathon, we should expect students who are new to coding, or at least new to coding the projects we will be working on, and therefore we must have elements ready that range from total novices who will be happiest with design work, to intermediate coders for whom the project must conform to the 30 Minute Rule (a developer must be able to understand and be able to work with the project in 30 minutes).
On the code side, I see that there will be a need to further document the project, and make contribution of code and data as straightforward as possible.
Finally, I think a hackathon is an excellent opportunity to teach basic project management by doing it. We had two scrum meetings during the day, and were able to keep everyone engaged.
Team videos: Justin
What's next for MissionsLibrary.org
The next steps for MissionsLibrary.org are going to focus on the contribution and community aspects. The crawl and upload process will need to be further automated so people can submit sites, and we may eventually look at machine learning for some of the more advanced tagging (i.e. identifying an image gallery). For contribution, we will need to explain the entire process and identify how people can contribute either resources, or new code for the crawler and database.
For the community, it is well known in open source that a great new contribution (in this case, a DIY search engine) will become common after a fairly short time. With this in mind, beyond the technology we will start building a community of people who have a passion either for archiving content or doing research through the archives, along with a developer community that could reach out to older websites for modernization.
As the owner of CeriumSoft, I will be using my organization to continue to drive the technological development, and between existing contacts and also some of the students, I will look into creating a team and potentially a non-profit organization around MissionsLibrary.org and its potential as a template for similar resource libraries in faith and tech.





Log in or sign up for Devpost to join the conversation.