
Team Members:
Laneia Murray, Myriam Walden-Duarte, Shubha Rajan, Kimberly Fasbender, Hana Clements
Inspiration
Even when websites don't explicitly ask users for their gender, they often use predictive models to gender users based on data the sites collect. Twitter, for example, doesn't inquire a user's gender upon registration but instead assigns users a binary gender. Instead of acknowledging the diversity of people they skew towards gendering users as male, and often misgender trans and gender diverse users. Users can access this gender information by going into their settings and privacy, and clicking on 'Your Twitter Data'. While it is unclear what kinds of models or features Twitter uses to determine a user's gender, it is apparent that Twitter's gendering algorithm is biased and unreliable.
What it does
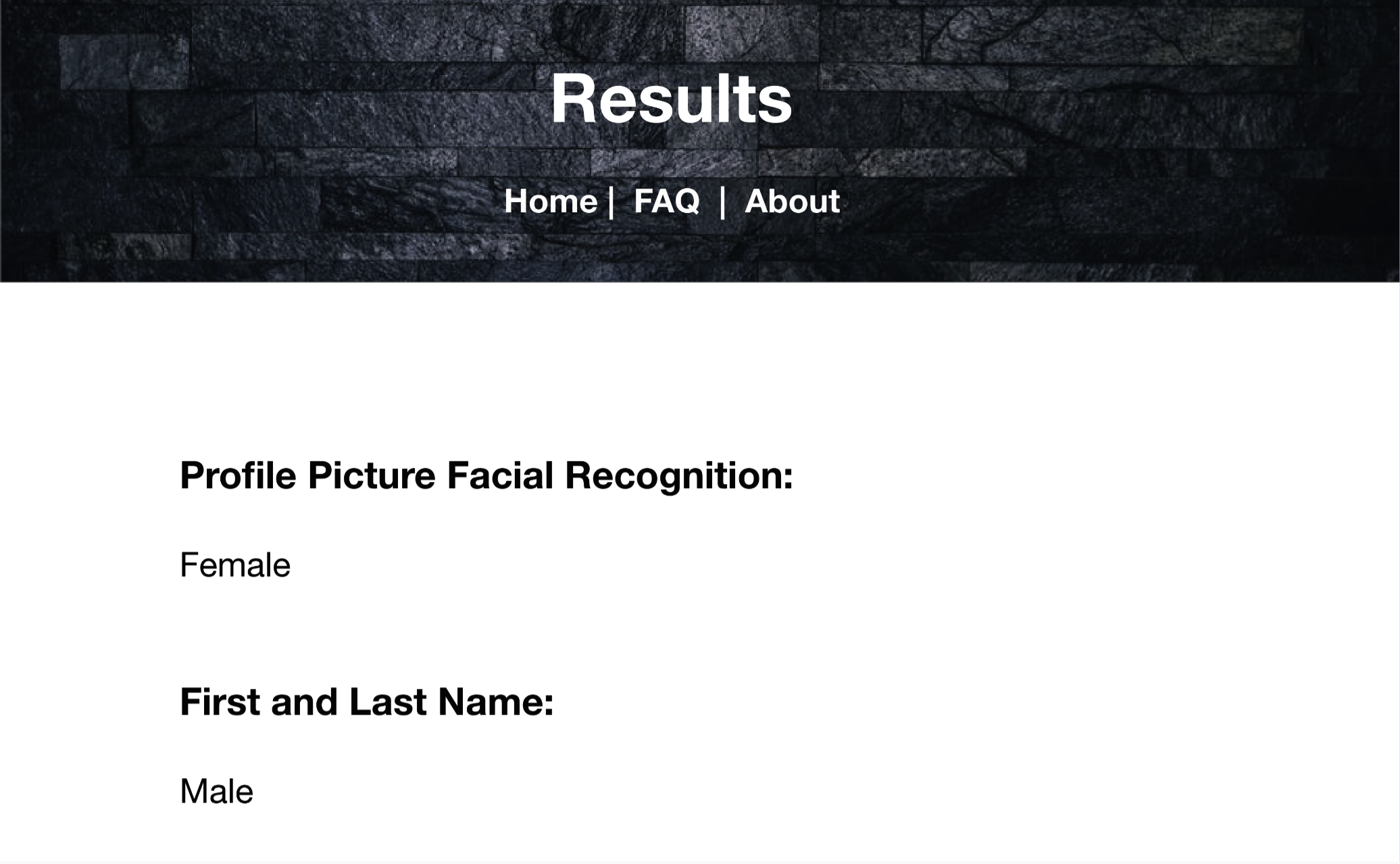
The aim of this WebApp is to call out the implicit bias in gendering algorithms by gendering users based on information collected from their twitter accounts, and collect information about how often users are misgendered in correlation with race and gender identity. After researching gendering algorithms in other APIs to attempt to understand Twitter's gender black box, we've identified three possible gendering technologies that may or may not correlate to how one would gender themselves:
- First name Twitter possibly uses the user's first name to assign them a gender, using a model trained on names corresponding to gender. This model may be problematic if the corpus is mainly based on names common in the US, and disregards names originating from other cultures. Ambiguously gendered names are often skewed towards being gendered as male.
- Facial recognition Facial recognition algorithms often misgender transgender and gender non-conforming people. There have also been studies that observe a pattern of misgendering women of color, especially black women. The video below, from MIT's Gender Shades project, discusses why these biased algorithms are problematic in a society that increasingly integrates them into everyday life.
- Content of posts Twitter possibly uses the text of users' posts as a factor to determine gender. While this may lead to accurate results when users use gendered language in reference to themselves ("woman", "girl", "mom"), but it may also gender people based on topics they commonly post about or words they use. We noticed that the use of the word "sorry" when testing text gender analysis APIs resulted in text being identified as female with high confidence. In our research, we also saw that in one model, "software" was an "anti-selector" for identifying females. We're not kidding ¯_(ツ)_/¯

How we built it
As students of Ada Developers Academy we have had previous exposure to Ruby, limited HTML, CSS and APIs. We began our process by identifying key user stories that would drive the interface of our application and ultimately our UML design driven by the MVC model. We then delegated our workload, rotating between retrieving HTTP get responses through pre-established gems, Twitter, Face++, Gender-API, and Text-Gain. While three of us parsed through the JSON responses using Ruby, one team member was in charge of the live site using HTML/CSS, and the last (but not least!) member created our database using Ruby on Rails. Using Github as our repository we were able to commit changes made locally and collaborate towards our collective goal. Throughout our whole process we checked in regularly, making sure that no one person was overloaded and reassigning tasks as needed.
Challenges we ran into
Our exposure to APIs were limited so we ran into many bugs as we attempted to close the gap in our knowledge. After hours of debugging code, relying heavily on Postman and documentation, we were able to locate, convert and parse through four different APIs for usable data for our application. Between revoked tokens, mismatched parameters, and understanding the difference between headers and bodies, we were able to put our heads together as a team and use pry, a runtime developer console, to live test our code and step through break points to identify syntax errors and breaks in logic. We also ran into the problem with limitors, introducing VCRs to call recorded API and debating whether or not to execute tests to drive our development.
Accomplishments that we're proud of
We are very proud to report that we set aside our insecurity of feeling unprepared and dove eagerly into the project at hand. We were able to identify a real problem within the industry and deliver a product that helps both educate and advocate. We were also able to solve multiple, multiple merge conflicts!
What we learned
As a team we have learned that collaboration takes priority over competition and that the team can only be successful as a whole. We also learned how to Google sleuth our way into learning and implementing a brand new language (Ruby on Rails) on the fly, and how to hack our way to a tangible deliverable. We also learned how to incorporate multiple languages into one application, and create a user experience powered by the MCV model.
What's next for misgender.me
By casting a light on and illuminating people who are marginalized on using present algorithms, misgender.me will be able to restore the identity of genderfluid, nonbinary, transgender, and cis people. We can expand this application by tearing down previously held stereotypes and profiling. Instead we can focus on tracking trends that can will allow more users to feel empowered in using these social platforms and increase accessibility. We hope that this could be compatable for future machine learning technology and implemented in a future that embraces the differences of it's users. Biases, both implicit and explicit, can be detected, rooted out and overcome by being intentional in our designs and implementation of software.





Log in or sign up for Devpost to join the conversation.