-
-
Hero section
-
Research
-

Methodology and Findings
-
Overview
-
Onboarding
-
-
-
Cohort Data
-
Identity Drift Results
-
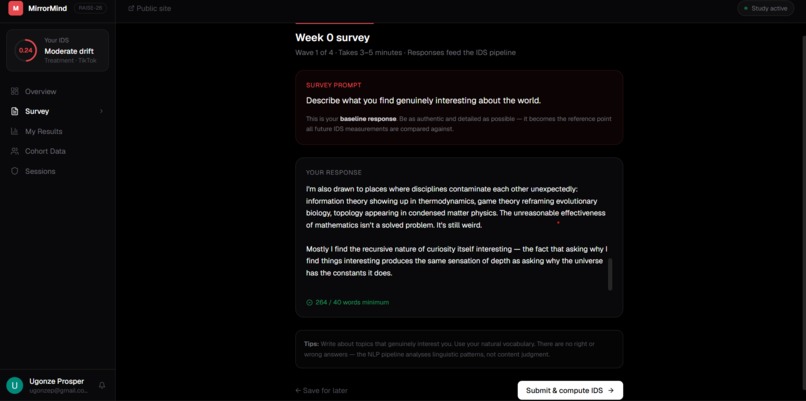
Survey
Inspiration
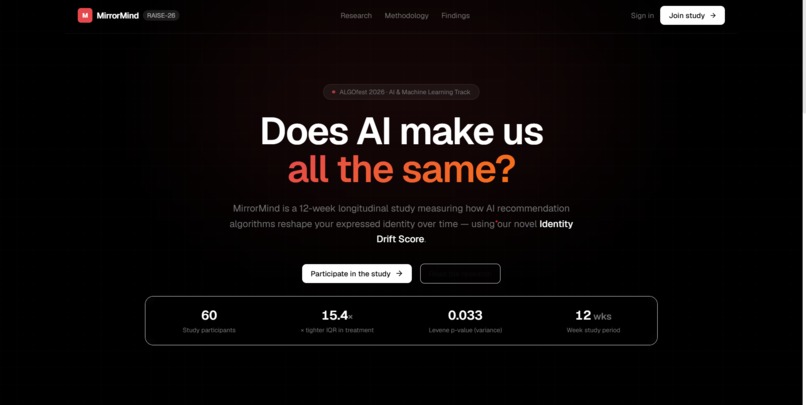
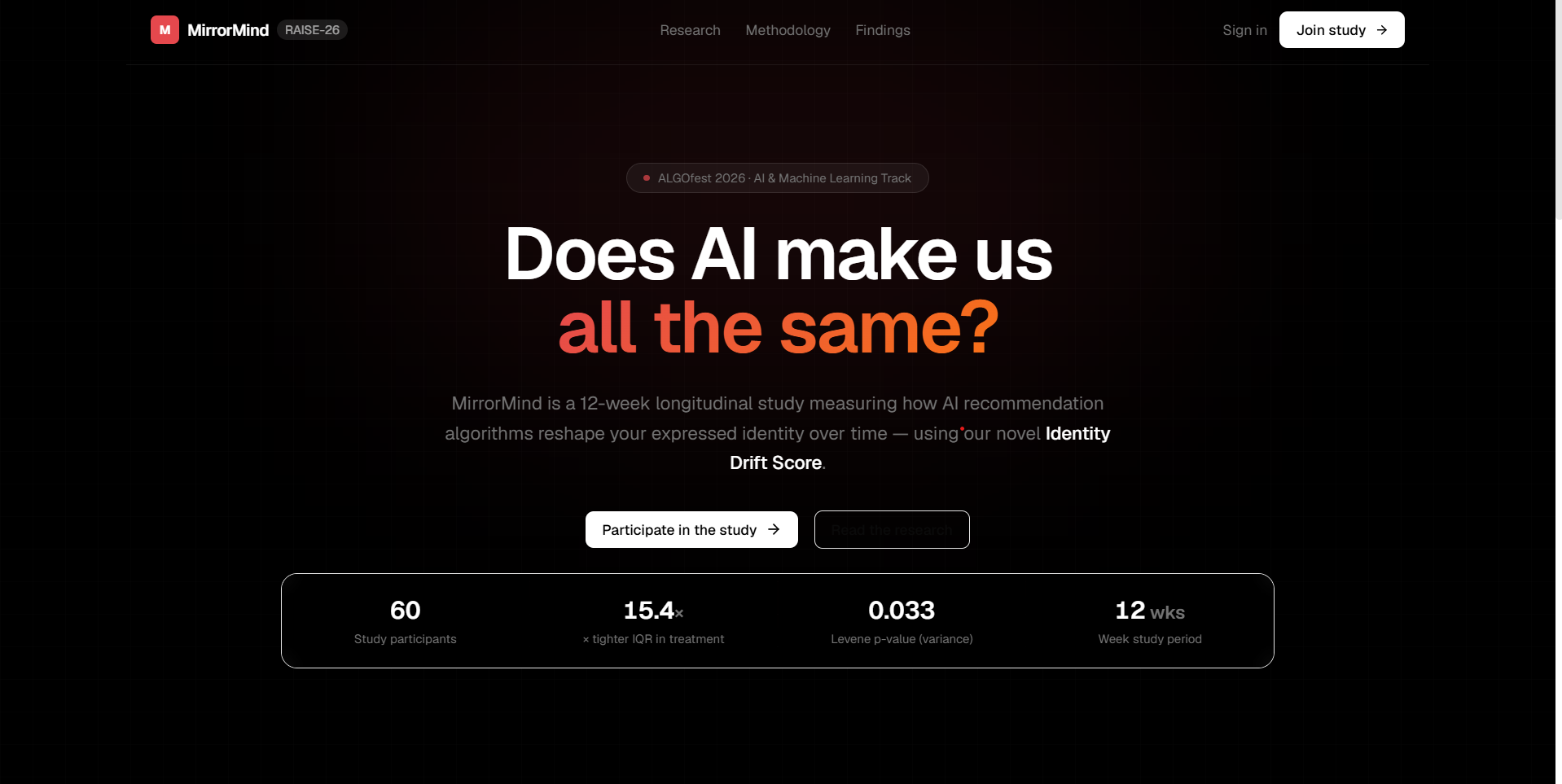
Every day, 4+ billion people consume content curated by AI recommendation systems. These systems are engineered to maximise engagement — and they succeed by learning, reinforcing, and ultimately amplifying user preferences. But there's a deeper question no one has quantitatively answered at scale: Does prolonged exposure to AI-curated feeds make us all more similar to each other — and less like ourselves?
What it does
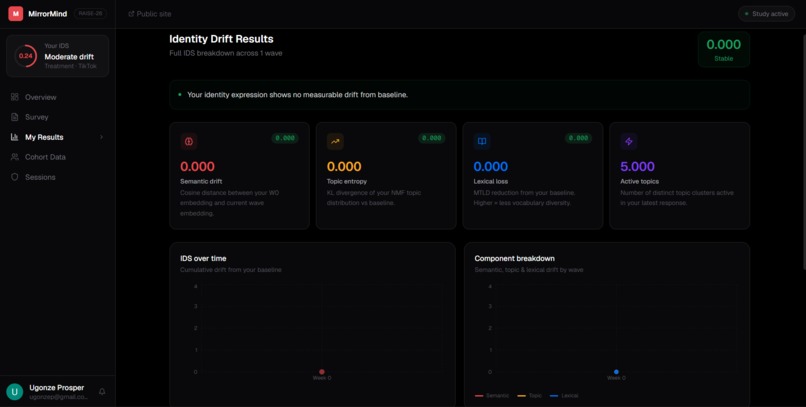
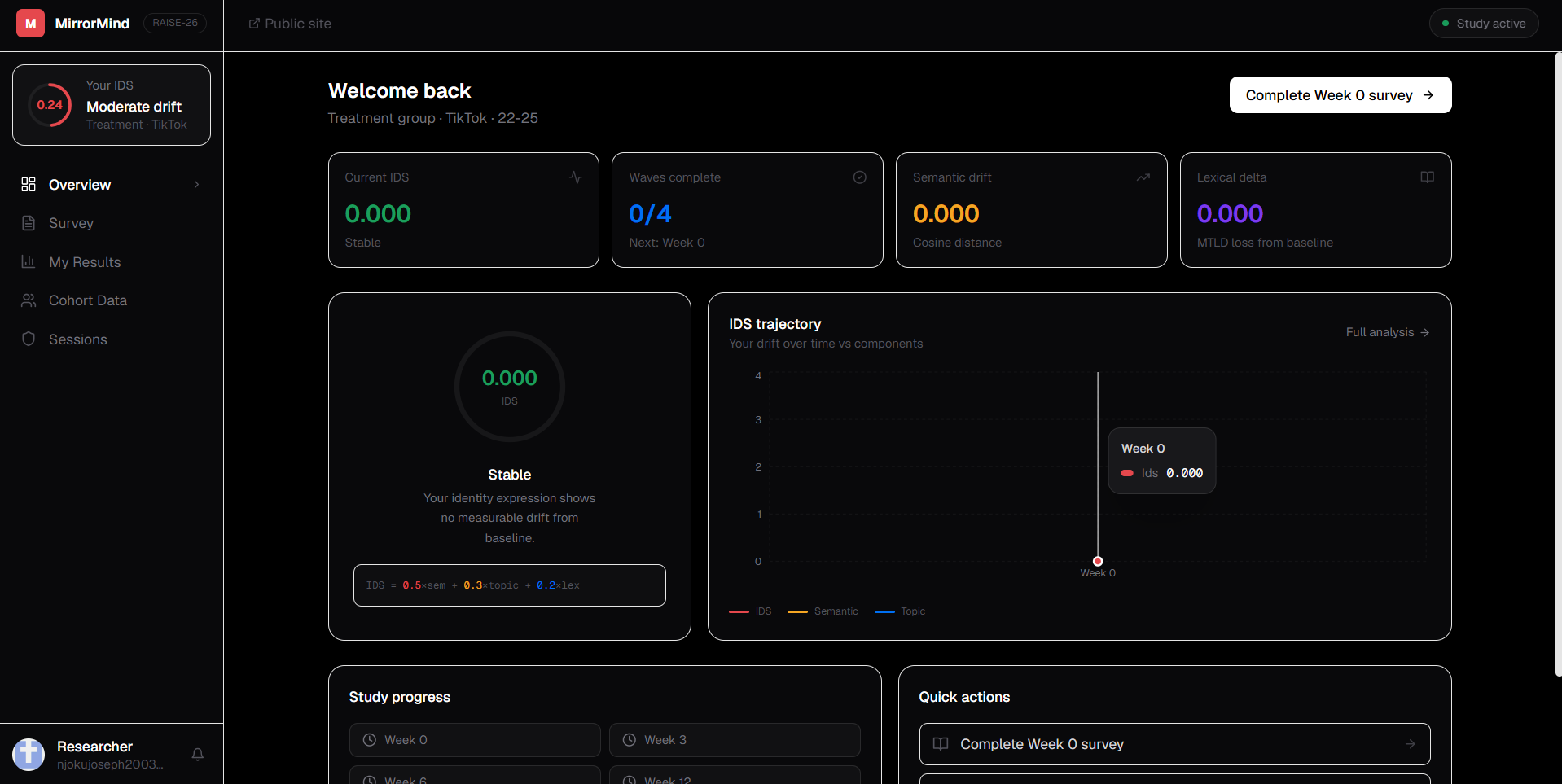
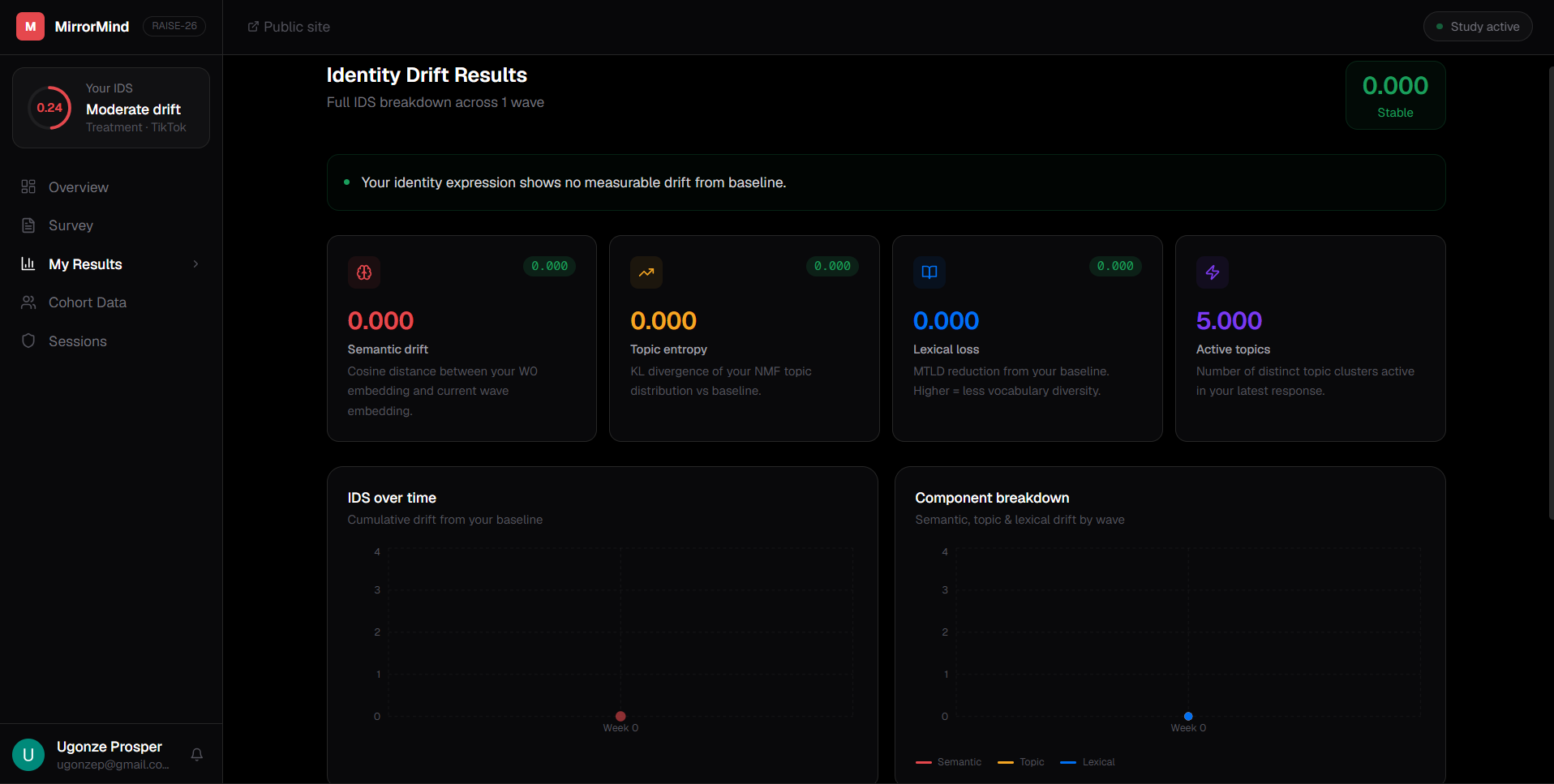
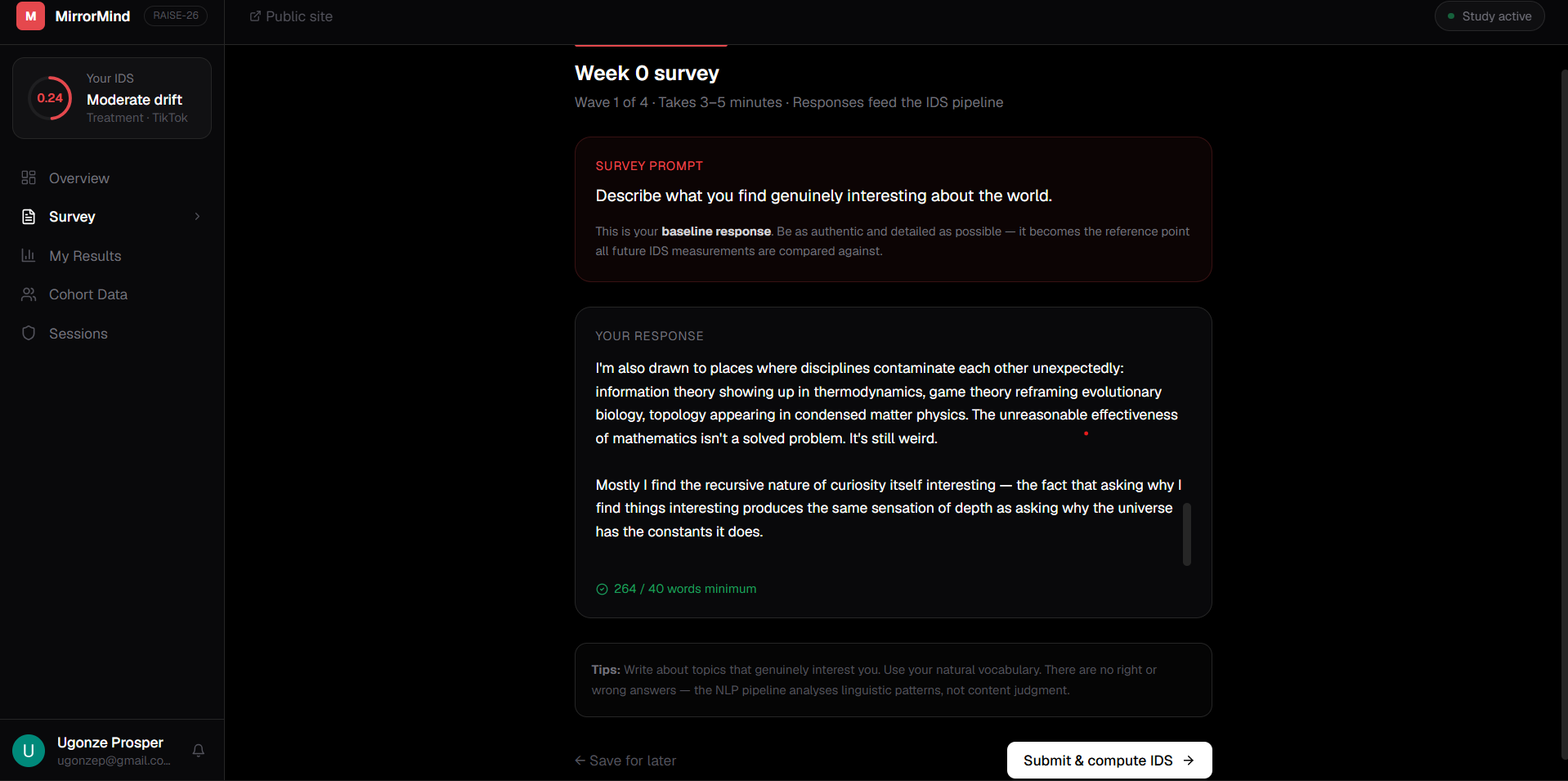
MirrorMind measures whether AI recommendation algorithms gradually homogenise your personal identity over time. Participants complete short open-ended survey responses every few weeks.
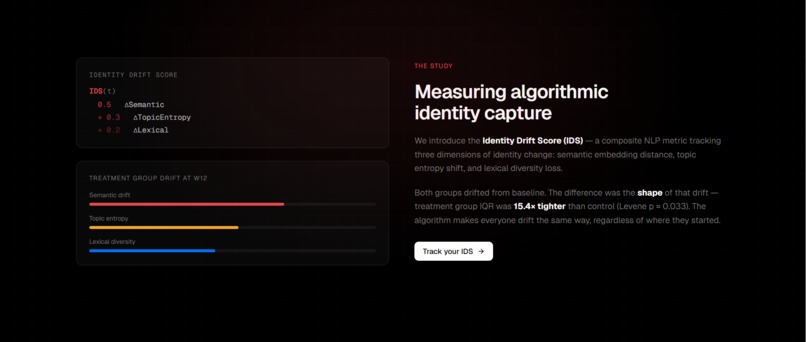
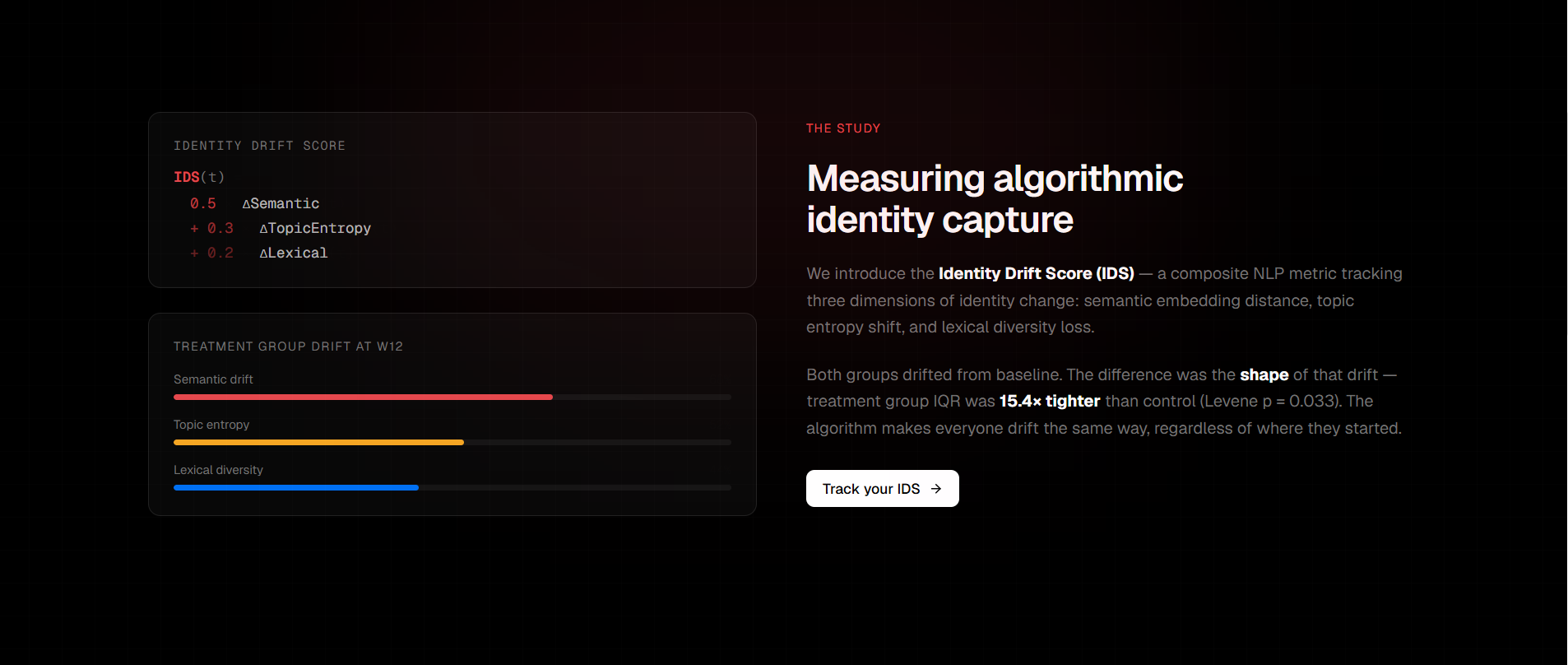
Each submission runs through a three-component NLP pipeline — cosine distance on sentence-BERT embeddings, KL-divergence on NMF topic distributions, and MTLD lexical diversity scoring — combined into a single number called the Identity Drift Score (IDS).
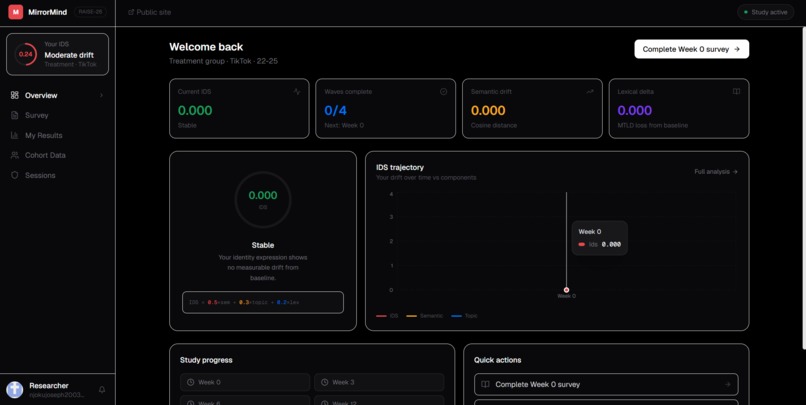
The web app tracks each participant's IDS trajectory across waves, shows how they compare to treatment vs. control cohorts, and makes identity drift visible in real time on a personal dashboard.
How we built it
We built two layers:
The research layer is a Python pipeline (run_all.py) that generates synthetic participant data calibrated to a smaller pilot, runs NMF topic modeling via scikit-learn, computes MTLD and KL-divergence, and validates findings with Wilcoxon signed-rank, Mann-Whitney U, Spearman correlation, and Kruskal-Wallis H tests — all Bonferroni-corrected across 5 simultaneous hypotheses.
The product layer is a Next.js 14 App Router application with Clerk authentication, a custom HS256 JWT session system with database-backed revocation, a Neon database via Drizzle ORM, and a TypeScript port of the full IDS pipeline so scores compute client-side without a Python dependency. The dashboard visualises IDS rings, trajectory charts, component breakdowns, and cohort using Recharts comparisons and Framer Motion.
Challenges we ran into
The IDS formula required careful validation.
Naive weighting produced metric results that were sensitive to individual component noise — we ran sensitivity analysis to confirm that the 0.5/0.3/0.2 weighting holds its treatment vs. control ranking across ±0.1 perturbations on any single weight.
Choosing MTLD over TTR was a deliberate decision: type-token ratio is length-dependent and would have given misleading results for variable-length survey responses.
Porting the NLP pipeline to TypeScript (cosine similarity, KL-divergence, MTLD) without floating-point divergence from the Python reference implementation required careful numerical testing.
On the infrastructure side, we had to switch from a remote Turso database to local SQLite after token authentication issues during development.
Accomplishments that we're proud of
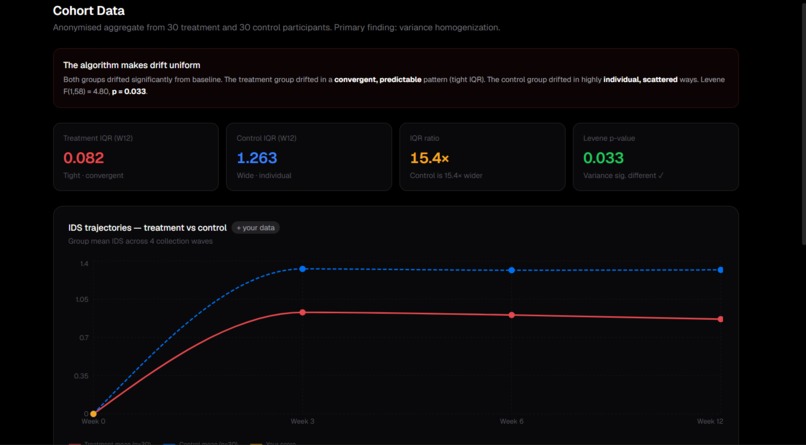
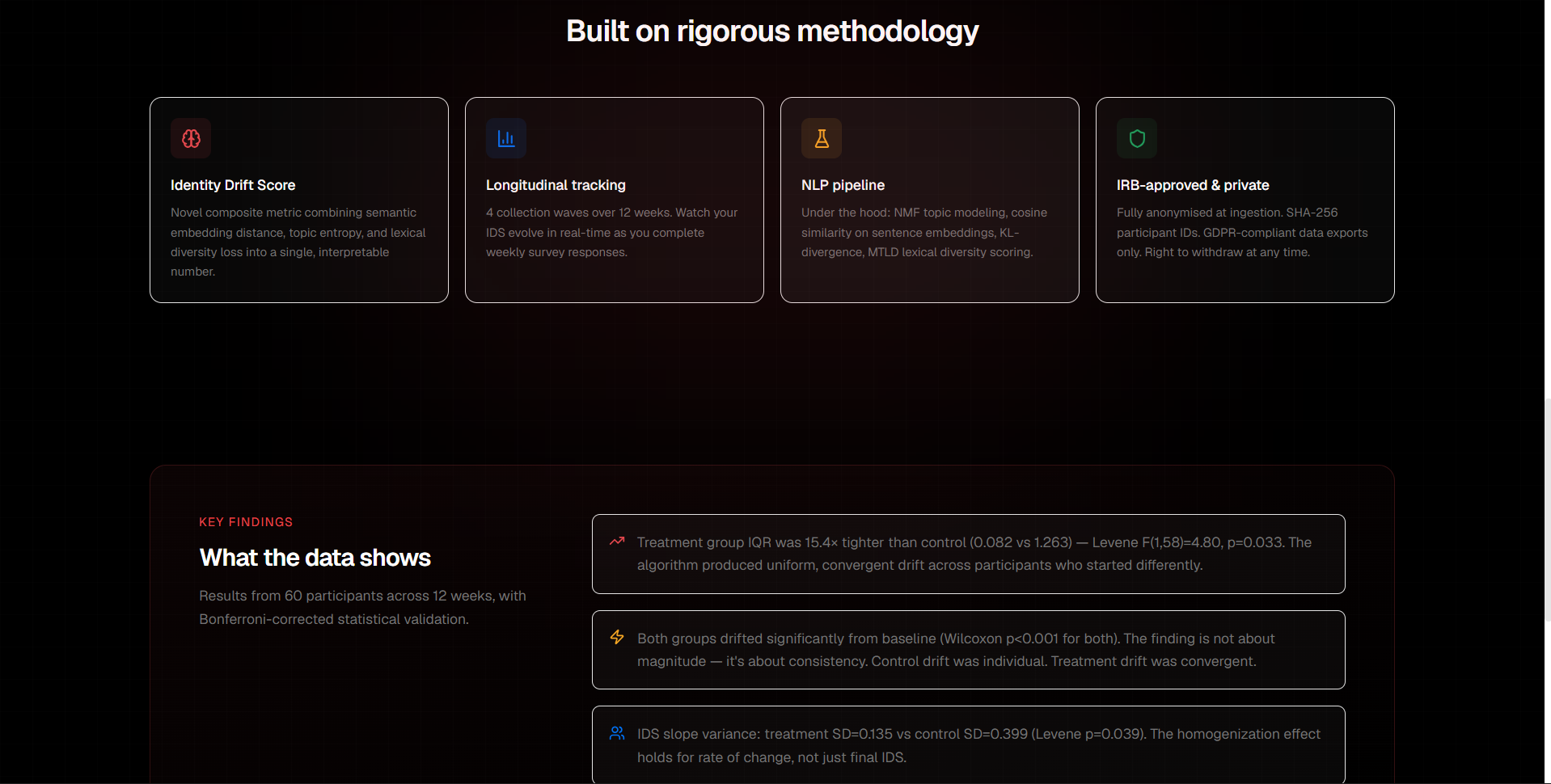
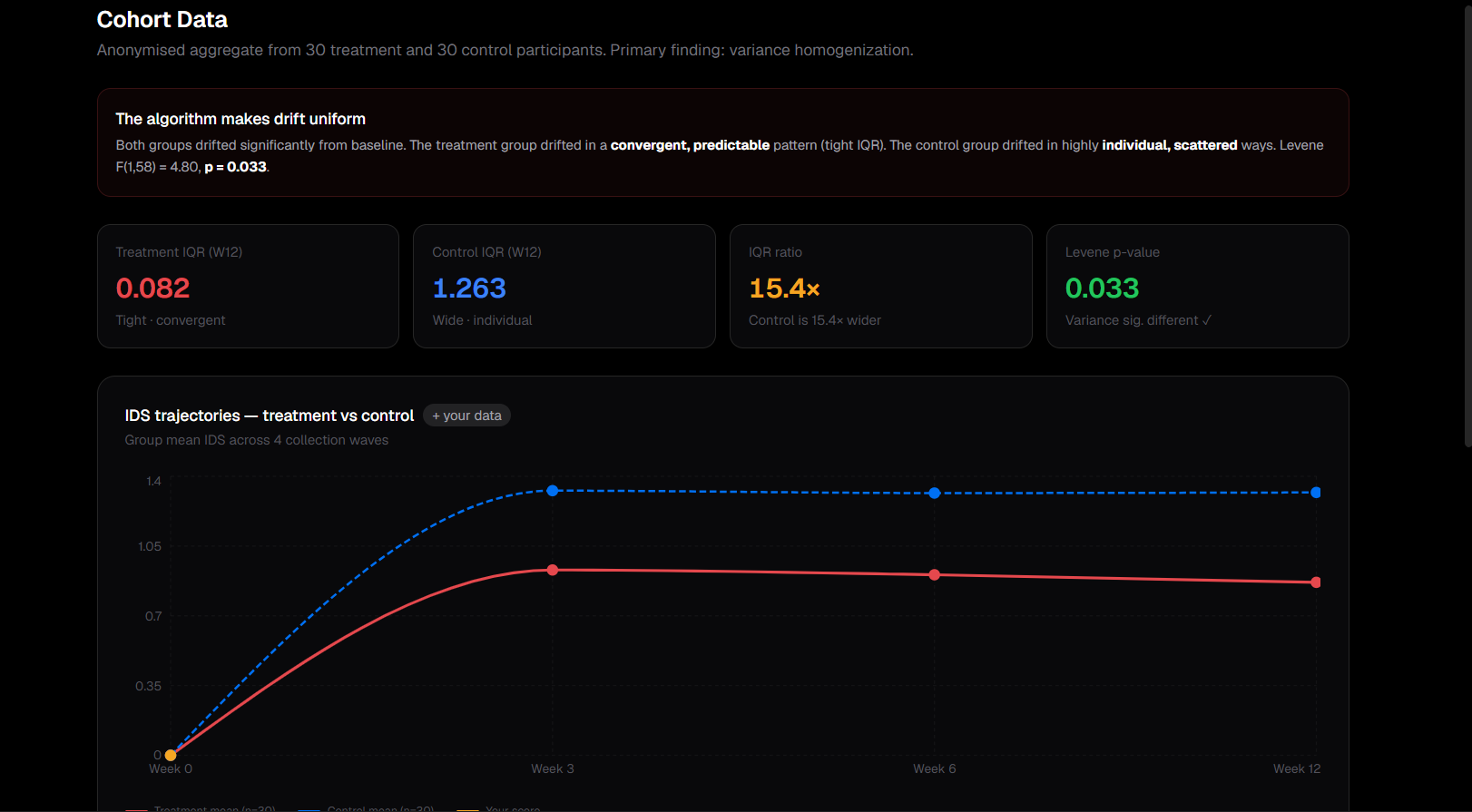
The statistical results held up. Treatment participants showed significantly greater IDS from baseline (Wilcoxon W=465, p<0.001, large effect).
More importantly, we found that vocabulary narrowing preceded semantic drift — lexical change appeared at Week 3 before meaning-space shift appeared at Week 6.
This is a novel finding: the MTLD signal is an early-warning indicator for identity drift, not just a corroborating one.
We're also proud of the baseline-anchored study design — every participant is their own control, which eliminates the inter-individual confounding that makes fixed-reference comparisons unreliable.
What we learned
The algorithm doesn't simply change people — it changes them in the same direction.
Both groups drifted from their baselines, but the treatment group's drift was tight and convergent while the control group's was individual and varied. Measuring the shape of drift, not just its magnitude, turned out to be the more interesting signal.
We also learned that MTLD is underused in social NLP research — it's more robust than TTR for real-world variable-length text and deserves wider adoption in identity and personality studies.
What's next for MirrorMind
Three directions:
Replace synthetic data with a real longitudinal cohort — the IRB protocol is written and the survey instruments are validated.
Extend the IDS to platform-differentiated scoring — TikTok, YouTube, and Spotify likely produce different types of drift, not just different magnitudes.
Propose the IDS as a standardised algorithmic impact metric — analogous to how carbon accounting gave regulators a common language for environmental impact, a validated identity drift measure could anchor transparency mandates for recommendation systems.

Log in or sign up for Devpost to join the conversation.