-
instant analyzation
-
homepage
-
dashboard
-
history
1. Project Title & Summary
MirrorMind
MirrorMind is a web-based linguistic analysis tool that helps college students recognize early patterns of emotional distress in their own writing — before those patterns become a crisis.
The tool is grounded in peer-reviewed research. A 2024 study by Kim & Römer-Barron, published in Corpus-Based Studies Across Humanities, demonstrated that machine learning models can detect depression markers in social media text with 96% accuracy by analyzing linguistic features including first-person pronoun overuse, hopelessness phrases, and isolation language. MirrorMind applies this methodology directly.
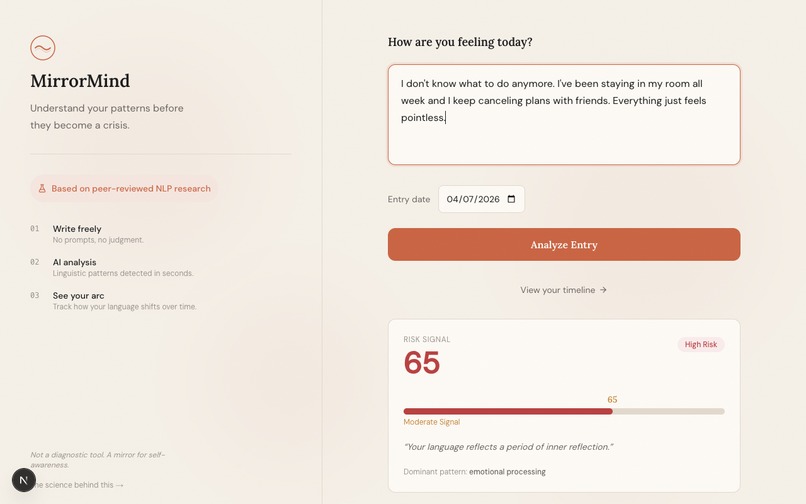
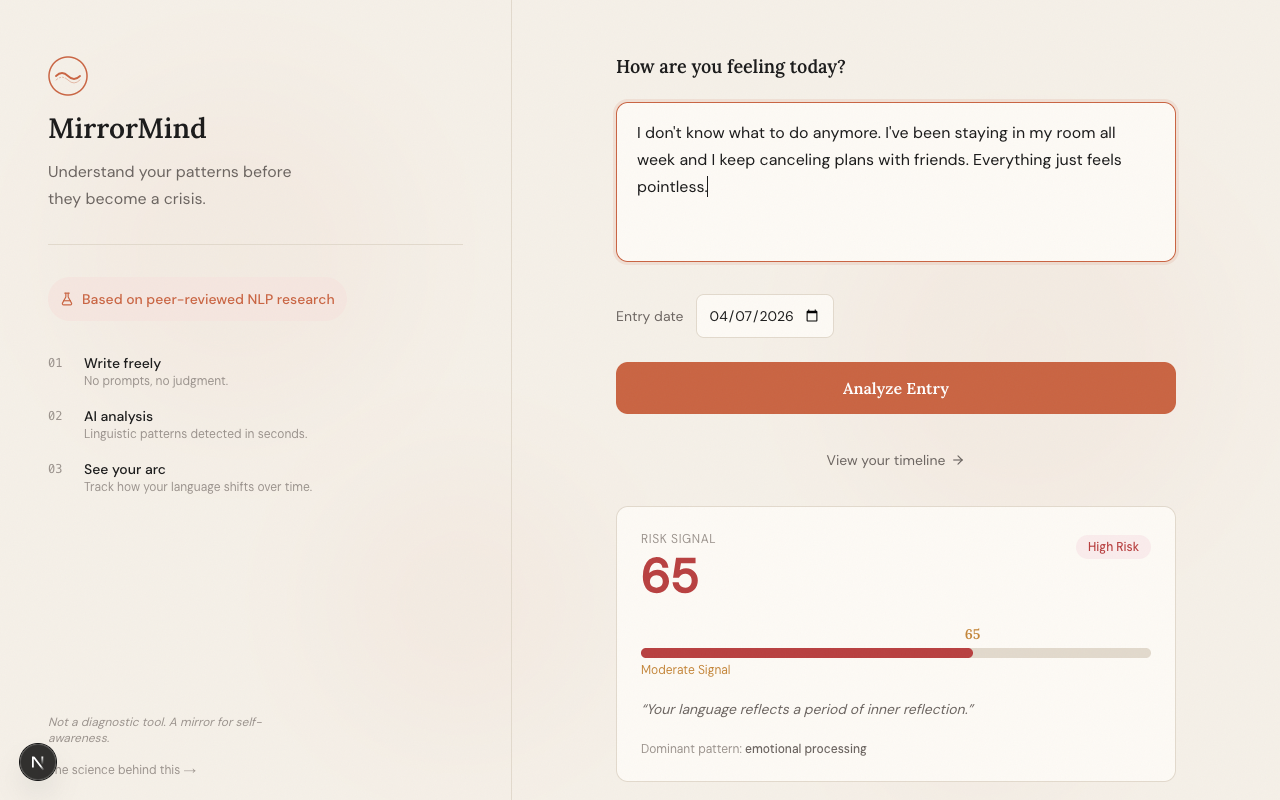
Users write a short journal entry - a few sentences about how they are feeling. Two AI systems analyze it simultaneously: a sentiment classification model trained on millions of social media posts produces a risk signal score, while Google Gemini identifies and highlights the specific phrases driving that signal, categorizing them as hopelessness language, isolation markers, self-focus patterns, or negative emotion. The result is an annotated, human-readable breakdown of the user's own linguistic patterns.
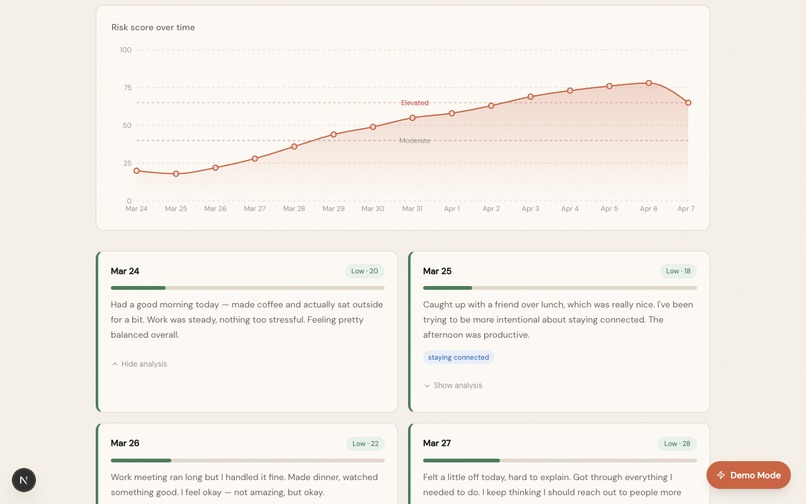
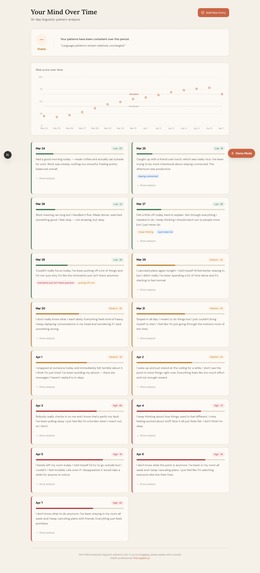
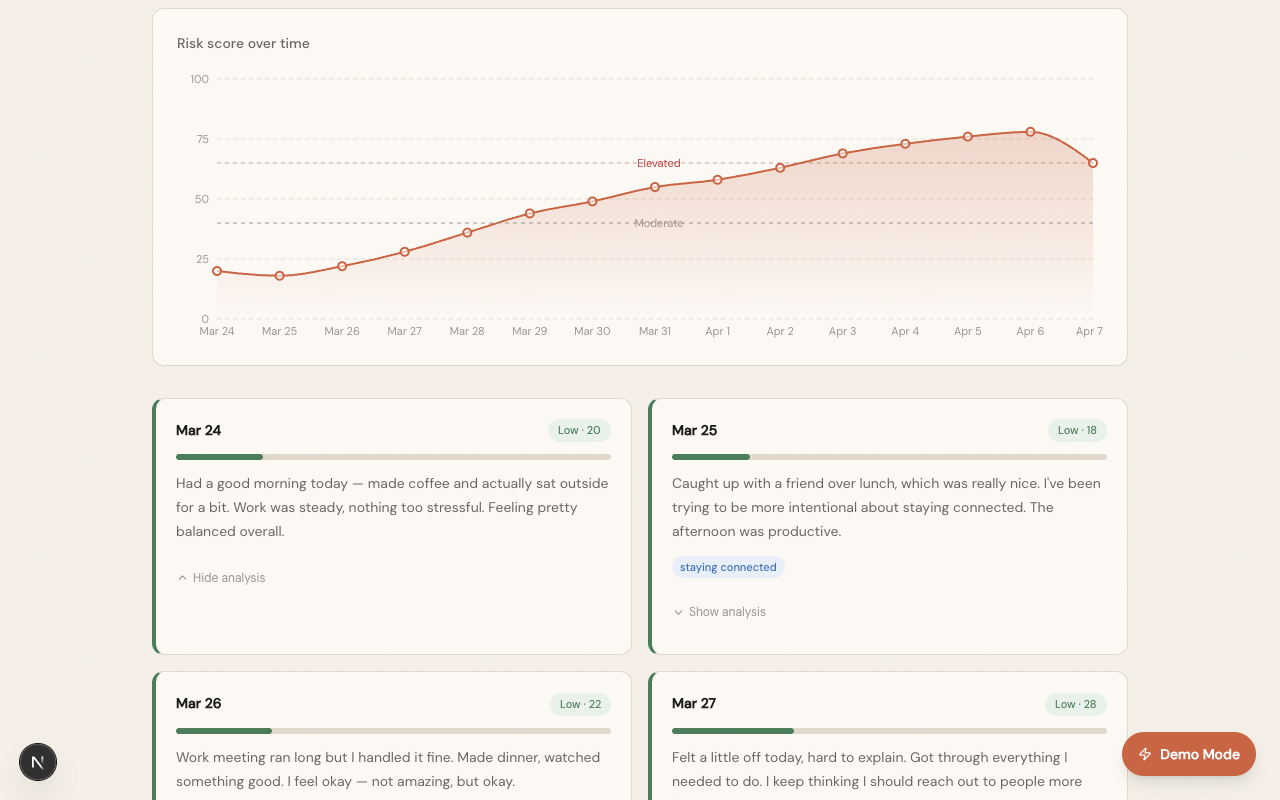
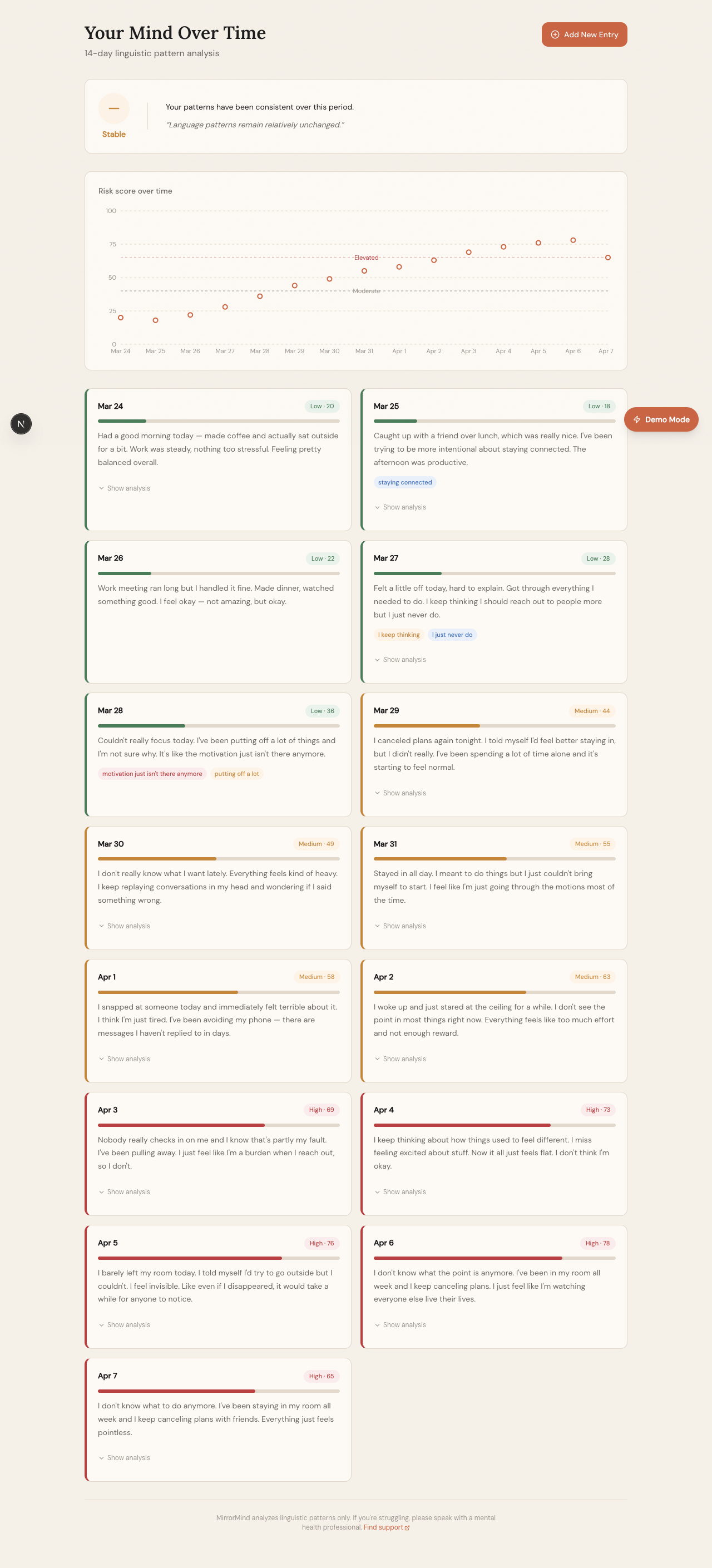
Over time, MirrorMind tracks entries and visualizes the trend: showing whether a user's language is improving, stable, or declining. This longitudinal view is the core innovation: a single score means little, but a two-week trajectory of rising linguistic risk is a meaningful signal that something may need attention.
MirrorMind is not a diagnostic tool. It does not detect depression. It is a mirror reflecting linguistic patterns back to the user to encourage self-awareness and timely help-seeking, at a moment when most students still believe they can handle it alone.
2. Problem Statement
The Brain Health Need
Depression is one of the most prevalent and undertreated conditions among college students. According to the 2024–2025 Healthy Minds Study, which surveyed over 96,000 students across 135 U.S. institutions:
- 22% of college students report severe depressive symptoms
- 32% experience moderate-to-severe anxiety
- 53% of students who screen positive for depression receive no counseling or therapy
- 30% of depressed college students will drop out before completing their degree
Counseling center utilization has grown five times faster than enrollment, yet the majority of students who need support never access it. The primary barriers are not availability — they are self-recognition and stigma. Students do not seek help because they do not recognize what is happening to them.
Who It Affects
The primary population is college students aged 18–24, a demographic at peak vulnerability for the onset of depression and anxiety. Students of color face compounded barriers: among African American students with a diagnosable mental health condition, only 21% had received a diagnosis compared to 48% of white students. First-generation students show higher rates of anxiety with greater delays in help-seeking.
The consequence of delayed recognition is not just academic underperformance — it is a public health failure at scale, playing out on every campus in the country.
3. Proposed Solution
Approach
MirrorMind addresses the self-recognition gap through passive, stigma-free linguistic analysis. Rather than asking students to self-report symptoms through questionnaires — a format associated with stigma and avoidance — MirrorMind invites users to simply write. Natural language already carries the signal. The research proves it. MirrorMind makes that signal visible.
Technology Stack
- Next.js 14 (App Router) — full-stack web application framework
- Cardiff NLP Twitter-RoBERTa — sentiment classification model with 4.8M downloads, providing the quantitative risk signal
- Google Gemini 2.5 Flash — phrase-level linguistic analysis, highlight categorization, and human-readable insight generation
- Recharts — longitudinal trend visualization
- Framer Motion — UI animations and interaction design
How It Fits
MirrorMind is designed to operate upstream of clinical intervention — in the space between a student noticing something feels off and a student making an appointment. It is not a replacement for counseling. It is the tool that helps a student recognize they should make that appointment.
The intended deployment context is university wellness portals and student health center intake flows, where students already interact with digital tools before accessing clinical resources.
4. Impact & Feasibility
Beneficiaries
Primary beneficiaries are college students experiencing early or unrecognized depressive symptoms — particularly those who would not self-refer to counseling due to stigma, uncertainty, or lack of self-awareness. Secondary beneficiaries are university wellness administrators, who gain a scalable, low-cost touchpoint for early identification.
Outcomes
- Increased self-recognition of linguistic depression markers in at-risk students
- Earlier help-seeking behavior, reducing time between symptom onset and first clinical contact
- Reduced burden on counseling centers through prevention-layer intervention
- Anonymized aggregate data providing wellness teams with population-level trend signals
Scalability
The architecture is inherently scalable. The application runs serverlessly on Vercel with no persistent user data stored server-side. All entries are stored locally in the user's browser. The AI inference pipeline scales with demand and costs fractions of a cent per analysis. A university with 50,000 students could deploy this tool at negligible marginal cost.
Technical Readiness
MirrorMind is a fully functional prototype built and deployed within a 4-day development window. Both API integrations are live and tested. The application handles error states, fallback logic, and edge cases. A 14-entry demo dataset with a realistic longitudinal arc is pre-loaded for immediate demonstration.
5. Innovation & Differentiation
What Is New
Most mental health apps fall into one of two categories: therapy platforms (reactive, expensive, clinician-dependent) or mood trackers (self-reported, subjective, unreliable). MirrorMind occupies a third category: objective linguistic biomarker tracking, grounded in peer-reviewed NLP research.
The specific innovations are:
- Longitudinal linguistic drift detection — not a single score, but a tracked trend. The system flags when a user's language deviates meaningfully from their personal baseline over time, which is clinically more significant than any single measurement.
- Dual-model architecture — a classification model provides the quantitative signal; a generative model provides the human-readable explanation. Neither alone is sufficient. Together they produce something neither could alone: a score with a reason.
- Phrase-level explainability — users see exactly which phrases triggered the signal, categorized by type. This transforms a black-box output into a teachable moment about one's own language patterns.
- Zero-stigma entry point — no questionnaires, no clinical framing, no self-labeling. Users just write.
Responsible Use of Emerging Technology
- No diagnostic claims — the tool explicitly frames its output as linguistic pattern detection, not clinical assessment
- No server-side data storage — all journal entries remain in the user's local browser, never transmitted to external servers
- Research transparency — the Kim & Römer-Barron methodology is cited within the application
- Crisis resource integration — every high-risk result includes a direct link to the 988 Suicide & Crisis Lifeline
- Human-in-the-loop framing — every insight explicitly encourages professional consultation
6. Prototype & Supporting Materials
Live Prototype
MirrorMind is a fully functional web application. The prototype includes:
- Journal entry input with real-time AI analysis
- Risk score display with color-coded meter (low / moderate / elevated)
- Phrase highlighting with category labels (hopelessness, isolation, self-focus, negative emotion)
- 14-day longitudinal dashboard with interactive trend chart
- Trend direction analysis (improving / stable / declining) with natural language summary
- Demo mode with animated timeline playback for live presentation
- Mobile-responsive design
Research Foundation
Kim, Y., & Römer-Barron, U. (2024). Machine learning detection of depression markers in Reddit posts. Corpus-Based Studies Across Humanities. [96% accuracy on 40,000 Reddit posts using linguistic feature analysis including first-person pronoun density, hopelessness phrases, and isolation language.]
Built With
- framer
- gemini
- next.js
- recharts

Log in or sign up for Devpost to join the conversation.