-
-
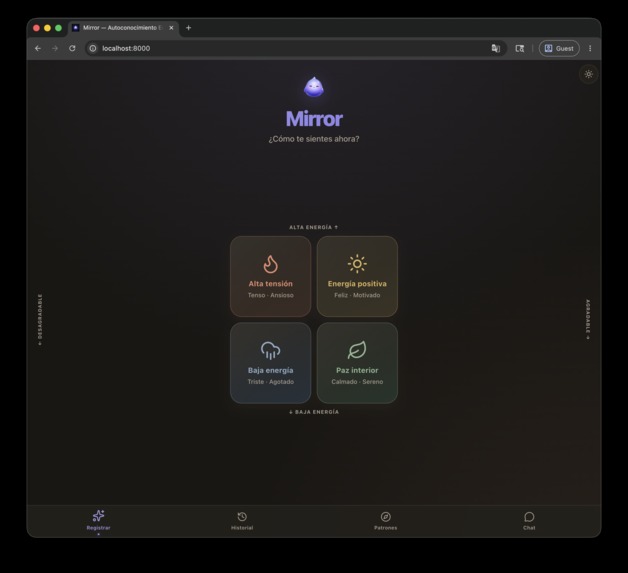
Pantalla de Inicio
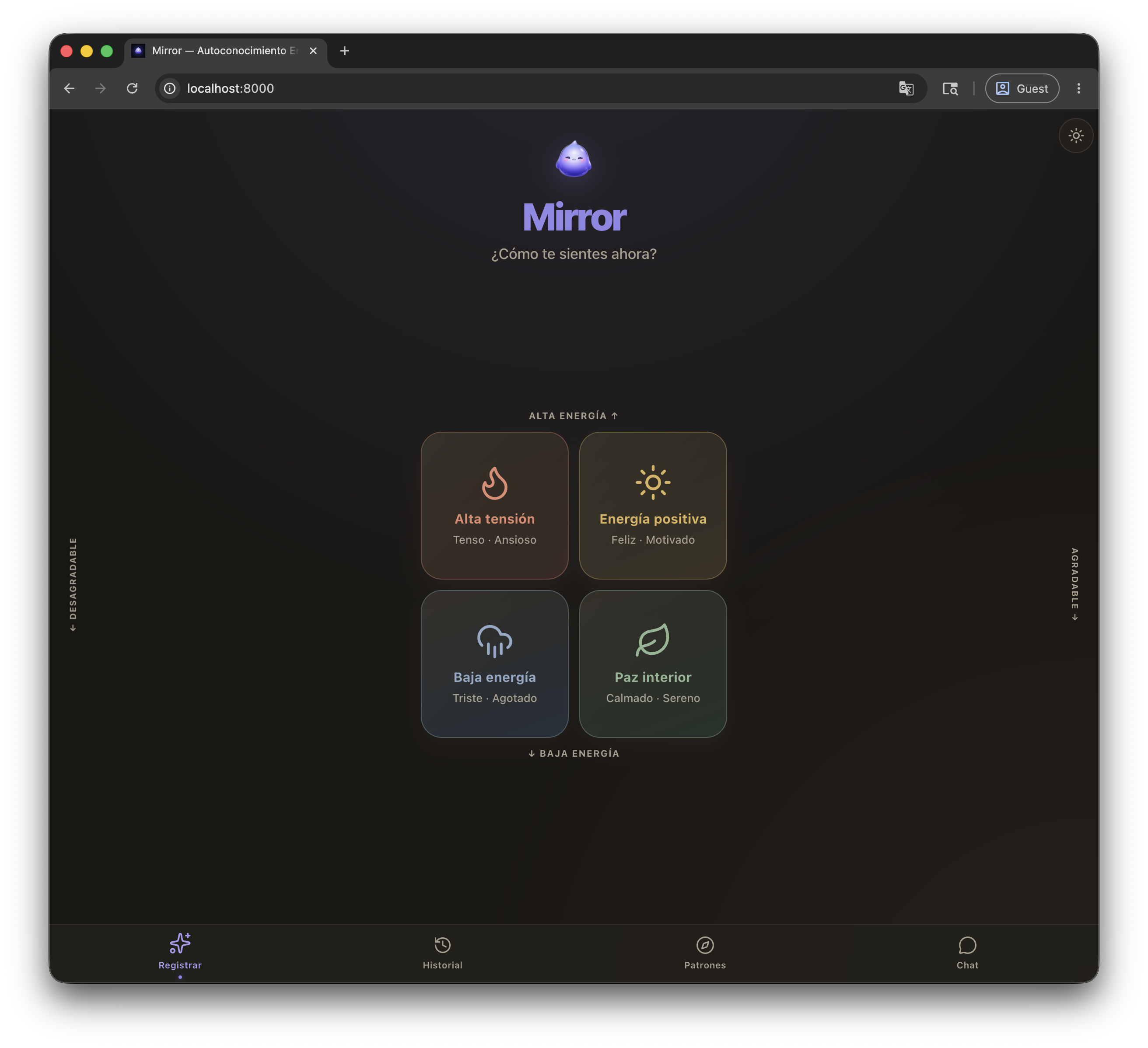
Mirror — Historia del proyecto
Inspiración
La mayoría de las apps de salud mental tratan los datos emocionales como cualquier otro dato de usuario: se suben a un servidor ajeno, se almacenan en una base de datos corporativa y los procesa un modelo de terceros. Pero las emociones son íntimas. La sola idea de que tus peores momentos vivan en un servidor de alguien más es, irónicamente, una fuente de ansiedad por sí sola.
También nos impactó un hallazgo de la investigación de Marc Brackett en el Yale Center for Emotional Intelligence: la persona promedio distingue apenas tres estados emocionales ("bien", "mal" y "más o menos"), mientras que el vocabulario emocional humano abarca miles de palabras. Esa brecha entre lo que sentimos y lo que podemos nombrar es exactamente donde vive la autoconciencia. El framework RULER — Reconocer, Understand (entender), Labelar (etiquetar), Expresar, Regular — existe para cerrarla.
Mirror nació de esas dos ideas: ¿y si un diario emocional privado, por voz, pudiera darle a cualquier persona acceso a la precisión del RULER, sin que sus datos más personales salgan jamás de su propio hardware?
What it does
Mirror es una Progressive Web App (PWA) de autoconocimiento emocional que corre completamente en tu propia máquina — sin nube, sin APIs de IA externas.
- Mood Meter — Una grilla 2D que mapea energía ($y$) y valencia ($x$) en cuatro cuadrantes (rojo/amarillo/azul/verde). El usuario toca un cuadrante y elige una de ocho etiquetas emocionales.
- Grabación de voz — El usuario mantiene presionado un botón y habla libremente sobre qué causó la emoción. El audio nunca sale de la red local.
- Extracción RULER — Un LLM local (
qwen3:4b-instructvía Ollama) lee la transcripción y devuelve un JSON estructurado con emoción primaria, emociones secundarias, cuadrante, valencia $\in [-1, 1]$, energía $\in [0, 1]$, intensidad $\in {1..10}$, disparador, contexto (personas, lugar, actividad) y pensamientos asociados. - Mensaje de acompañamiento — Al guardar, si la entrada es negativa e intensa, se genera un mensaje empático breve a partir del historial de bienestar del propio usuario — sugerencias basadas en lo que realmente le ha funcionado, no consejos genéricos.
- Timeline — Historial desplazable de entradas, codificadas por color según cuadrante.
- Detección de patrones — Un motor de señales determinista (sin LLM) ejecuta seis detectores sobre el historial: emoción negativa intensa, rachas de días consecutivos, tendencia de valencia (últimos 7 días vs. los 7 anteriores), disparadores recurrentes, anomalías de intensidad y ausencias de registro.
- Chat (RAG) — Interfaz conversacional respaldada por búsqueda semántica en ChromaDB. El usuario pregunta cosas como "¿cómo me he sentido esta semana?" y el modelo responde usando las 5 entradas más relevantes recuperadas más el perfil emocional consolidado del usuario.
- Detección de crisis — Coincidencia de palabras clave activa un modal a pantalla completa con SAPTEL (55 5259-8121) y Línea de la Vida (800-911-2000).
How we built it
El backend es un servidor FastAPI (Python) que orquesta cuatro servicios independientes:
- STT — En macOS,
whisperkit-cli(WhisperKit, acelerado con CoreML) transcribe el audio. En otras plataformas,faster-whisperfunciona como fallback directo. El audio se normaliza a WAV 16 kHz mono víaffmpegantes de la transcripción. - LLM —
qwen3:4b-instructcorriendo localmente a través de Ollama. Un prompt de sistema con restricciones estrictas fuerza salida JSON puro. Un paso_strip_reasoning()elimina bloques<think>...</think>de variantes con razonamiento. - Memoria (dos capas):
- ChromaDB almacena las entradas RULER crudas con embeddings (
qwen3-embedding:0.6b). La recuperación usa un score compuesto: $\text{score} = 0.6 \cdot \text{sim} + 0.3 \cdot \text{recencia} + 0.1 \cdot \text{intensidad}$, donde la recencia decae con vida media $\lambda = 14$ días: $r = 0.5^{d/\lambda}$. - SQLite guarda el perfil consolidado del usuario (baseline por media móvil, fuentes de bienestar, seguimiento de rachas) y el historial de sesiones de chat. El perfil se actualiza incrementalmente en $O(1)$ por entrada usando media acumulada: $\mu_n = \mu_{n-1} + \frac{x_n - \mu_{n-1}}{n}$.
- ChromaDB almacena las entradas RULER crudas con embeddings (
- Motor de señales — Estadística pura, sin LLM. La anomalía de intensidad usa detección de 1.5 sigmas sobre las últimas 20 entradas; la tendencia de valencia compara $\bar{v}{[0,7\text{d}]}$ vs $\bar{v}{[7,14\text{d}]}$ con umbral $|\Delta| \geq 0.25$.
El frontend es HTML + JavaScript vanilla con Tailwind CSS (compilado localmente, no desde CDN). Sin framework, sin build step para JS. Los íconos de Lucide se cargan como librería. El Service Worker cachea todos los assets estáticos (mirror-v7) para operación offline completa una vez instalada. El Mood Meter y las pantallas de sub-emociones usan transiciones morfológicas CSS entre vistas.
Challenges we ran into
Confiabilidad del JSON en un modelo de 4B parámetros. Los modelos pequeños alucinan estructura. Lo resolvimos con el modo format: "json" de Ollama (restringe el sampler de tokens a JSON válido), un prompt de sistema con few-shot ajustado y definiciones explícitas de cuadrantes, y un parser que extrae el primer bloque {...} como fallback.
Latencia de cold-start en CoreML. La primera inferencia de WhisperKit carga el modelo en el Neural Engine de Apple, lo que puede tomar 30–60 segundos. Lo resolvimos con un warmup al arranque: el servidor transcribe un segundo de silencio generado al iniciar, pagando el costo del cold-start antes de la primera grabación real del usuario.
Diversidad de formatos de audio. Los navegadores móviles emiten WebM/Opus u OGG dependiendo del dispositivo. Whisper solo acepta WAV a 16 kHz mono. Construimos una etapa de conversión con ffmpeg como subproceso, normalizando cada archivo entrante antes de que llegue al transcriptor.
Relevancia del RAG con pocos datos. Al inicio del historial del usuario, la similitud semántica sola sub-recupera porque el corpus es pequeño y los embeddings son dispersos. La función de scoring compuesto se ajustó para ponderar fuertemente la recencia ($w = 0.3$) de modo que las entradas más recientes siempre aparezcan incluso con baja similitud semántica.
Mantener al LLM como espejo, no como terapeuta. La ingeniería de prompts requirió múltiples iteraciones para evitar que el modelo diera consejos, diagnosticara o minimizara emociones. El prompt de acompañamiento está explícitamente restringido: solo puede reflejar lo que el usuario dijo y sugerir actividades extraídas de las propias fuentes de bienestar registradas por el usuario.
Accomplishments that we're proud of
- Privacidad total de extremo a extremo. Cero bytes de datos emocionales salen del hardware del usuario. La arquitectura LAN (laptop como servidor, celular como cliente) garantiza esto incluso sin un dispositivo edge dedicado.
- Arquitectura de memoria de dos capas. ChromaDB para memoria episódica semántica y SQLite para un perfil emocional mantenido incrementalmente en $O(1)$ por entrada — sin recomputación por lotes.
- Motor de señales determinista. Seis detectores de patrones corren en milisegundos sin intervención del LLM, haciendo la pantalla de Patrones instantánea y completamente auditable.
- Mensajes de acompañamiento fundamentados. Las recomendaciones referencian únicamente actividades, lugares y personas extraídos de las propias entradas positivas del usuario — el sistema literalmente no puede recomendar algo que no haya visto funcionarle a ese usuario.
- PWA en un solo proceso FastAPI. El backend sirve el frontend como archivos estáticos, así que hay un solo servidor que iniciar, un solo puerto que exponer y cero complejidad de despliegue.
What we learned
- El tamaño del modelo es una restricción real, no una bandera de configuración.
qwen3:4b-instructes suficientemente rápido para una demo de hackathon, pero necesita ingeniería de prompts más intensa para mantenerse en formato que un modelo más grande. Los modos de salida estructurada (format: "json") no son opcionales con 4B parámetros. - El framework RULER fuerza decisiones de diseño. Mapear cada entrada emocional al plano valencia-energía hace que la detección de patrones sea tratable — obtienes una señal numérica gratis con cada guardado. Esa coordenada de cuadrante es lo que hace posible el motor de señales sin LLM.
- Dos bases de datos es la decisión correcta. ChromaDB es excelente para búsqueda semántica pero terrible para consultas estructuradas ("dame las últimas 20 entradas ordenadas por fecha"). SQLite maneja todo lo que ChromaDB no puede. Intentar usar un solo almacén para ambos casos habría costado más tiempo de ingeniería que correr los dos.
- El STT es la capa más frágil. El rendimiento de Whisper se degrada significativamente con audio corto, ruido de fondo y micrófonos no estándar. Construir el warmup, los guardas de duración y el pipeline de conversión de audio antes de tocar la capa del LLM nos ahorró horas de debugging.
What's next for Mirror
- Despliegue verdaderamente en el dispositivo. Portar el backend de Python a un binario Swift/Kotlin para que Mirror corra completamente en el celular, sin necesidad de laptop.
- Detección de patrones longitudinales. El motor de señales actualmente mira ventanas de 7–14 días. Patrones a más largo plazo (ciclos de ánimo mensuales, variaciones estacionales de valencia) requieren agregación temporal más rica — probablemente una capa de series de tiempo sobre el SQLite existente.
- Exportación e interoperabilidad. Un export JSON local-first para que los usuarios posean una copia portable de su historial emocional, y una sincronización opt-in hacia una instancia auto-alojada para uso multi-dispositivo.
- Sugerencias de regulación fundamentadas en investigación. La "R" de Regulación en RULER está actualmente poco desarrollada. Una base de estrategias de regulación basada en evidencia (técnicas de respiración, prompts de reencuadre, activaciones conductuales) podría emparejarse con los estados emocionales detectados sin requerir inferencia del LLM.
- Dashboard para clínicos. Mirror produce exactamente los datos estructurados que un terapeuta querría ver entre sesiones. Un enlace de solo lectura, controlado por el paciente, podría convertir el diario personal en un puente entre consultas.
Built With
- chromadb
- css3
- fastapi
- html5
- javascript
- ollama
- python
- qwen
- sqlite
- tailwindcss


Log in or sign up for Devpost to join the conversation.