-
-
-
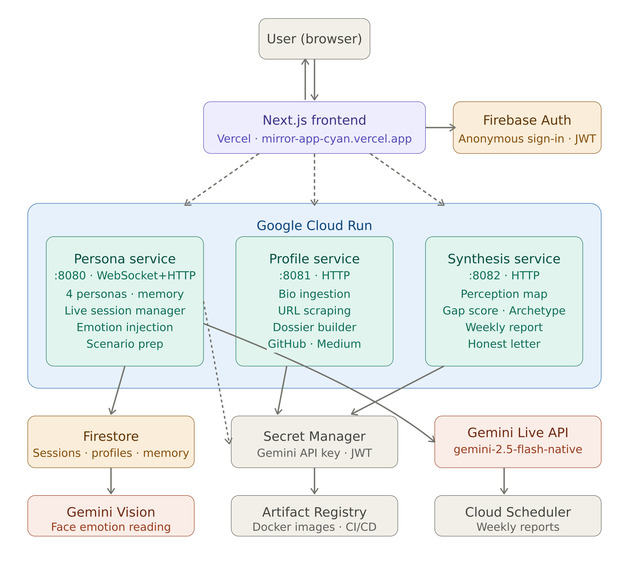
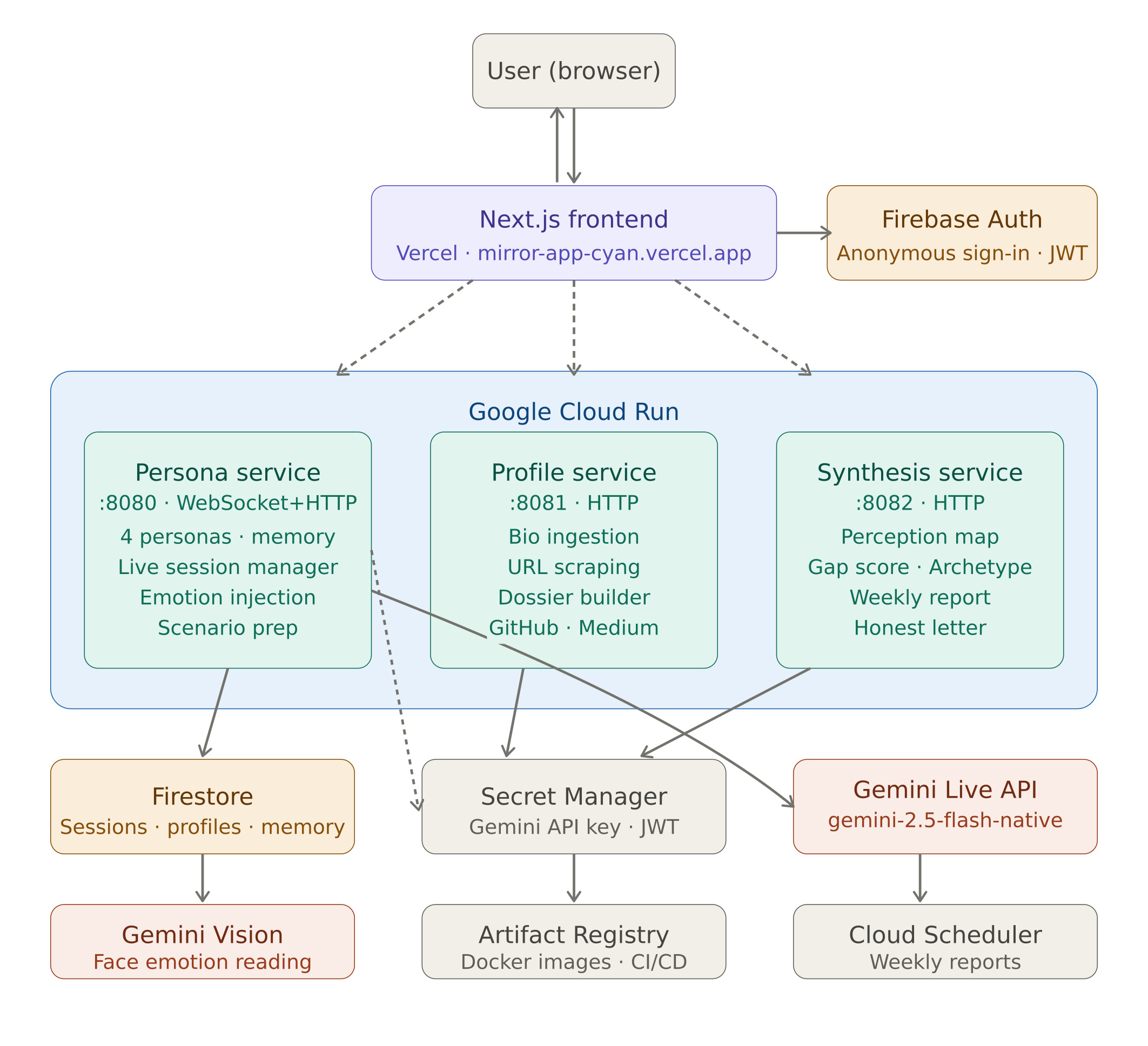
architecture_diagram
What is Mirror?
Everyone has googled you. Mirror lets you hear what they found.
Mirror is a real-time voice-based self-awareness app powered by four distinct AI personas — Rachel (career), Alex (relationships), Chris (competition), and Jordan (public image) — that conduct live, interruptible voice interviews to surface blind spots between your self-perception and how others perceive you.
Inspiration
We obsess over how we present ourselves online yet have almost no feedback mechanism for how we're actually perceived. Mirror fills that gap by simulating the perspectives of four people who would evaluate you ruthlessly: a senior recruiter, a potential romantic partner, a direct competitor, and an investigative journalist.
How I Built It
Real-time voice via Gemini Live API (gemini-2.5-flash-native-audio-preview-12-2025) with bidirectional WebSocket streaming through a Node.js proxy on Cloud Run. The proxy injects persona memory, dossier context, and facial emotion signals before each session.
Face emotion reading via Gemini Vision — the camera captures frames every 3 seconds during voice sessions. Observations like "subtle tension around the mouth" get injected as private context so personas can respond naturally to what they see.
Multimodal intelligence layer — after conversations, a synthesis service generates Perception Maps, Gap Scores, Archetypes, Weekly Reports, and an Honest Letter from all four personas.
Memory system — each persona builds persistent memory across sessions using Firestore, so Rachel remembers what you said last week and holds you to it.
URL scraping — users can add GitHub, Medium, and personal portfolio links. Real HTTP fetch (not hallucination) extracts repos, article titles, and bio content to give personas richer context.
Architecture
- Frontend: Next.js on Vercel
- Backend: 3 Node.js microservices on Google Cloud Run
- Database: Firestore (sessions, profiles, memory)
- AI: Gemini Live API (voice), Gemini 2.5 Flash (synthesis/memory), Gemini Vision (emotions)
- Infrastructure: Artifact Registry, Secret Manager, Cloud Scheduler, GitHub Actions CI/CD
Challenges
The biggest challenge was the Gemini Live native audio model — it does not support transcription or AUDIO+TEXT modalities simultaneously (causes 1007 errors). We solved this with browser SpeechRecognition for user captions and post-session Gemini summaries for agent speech, creating a unified chat thread from both.
Audio playback required careful PCM16 handling at exact sample rates (16kHz in, 24kHz out) with a GainNode at 0.15 during playback — enough to suppress echo without blocking interruptions.
What I Learned
Real-time bidirectional audio is unforgiving. Every millisecond of latency is felt. The 0.15 gain value for interruption handling was found entirely through trial and error.
Built for the Gemini Live Agent Challenge #GeminiLiveAgentChallenge


Log in or sign up for Devpost to join the conversation.