Inspiration
Every day, millions of dollars flow through prediction markets like Polymarket and Kalshi. People treat these odds as ground truth, citing them in news articles, tweets, and investment decisions. But nobody was asking the obvious question: are these markets actually good at predicting things? And when two markets price the same event differently, who ends up being right? We wanted to find out.
What it does
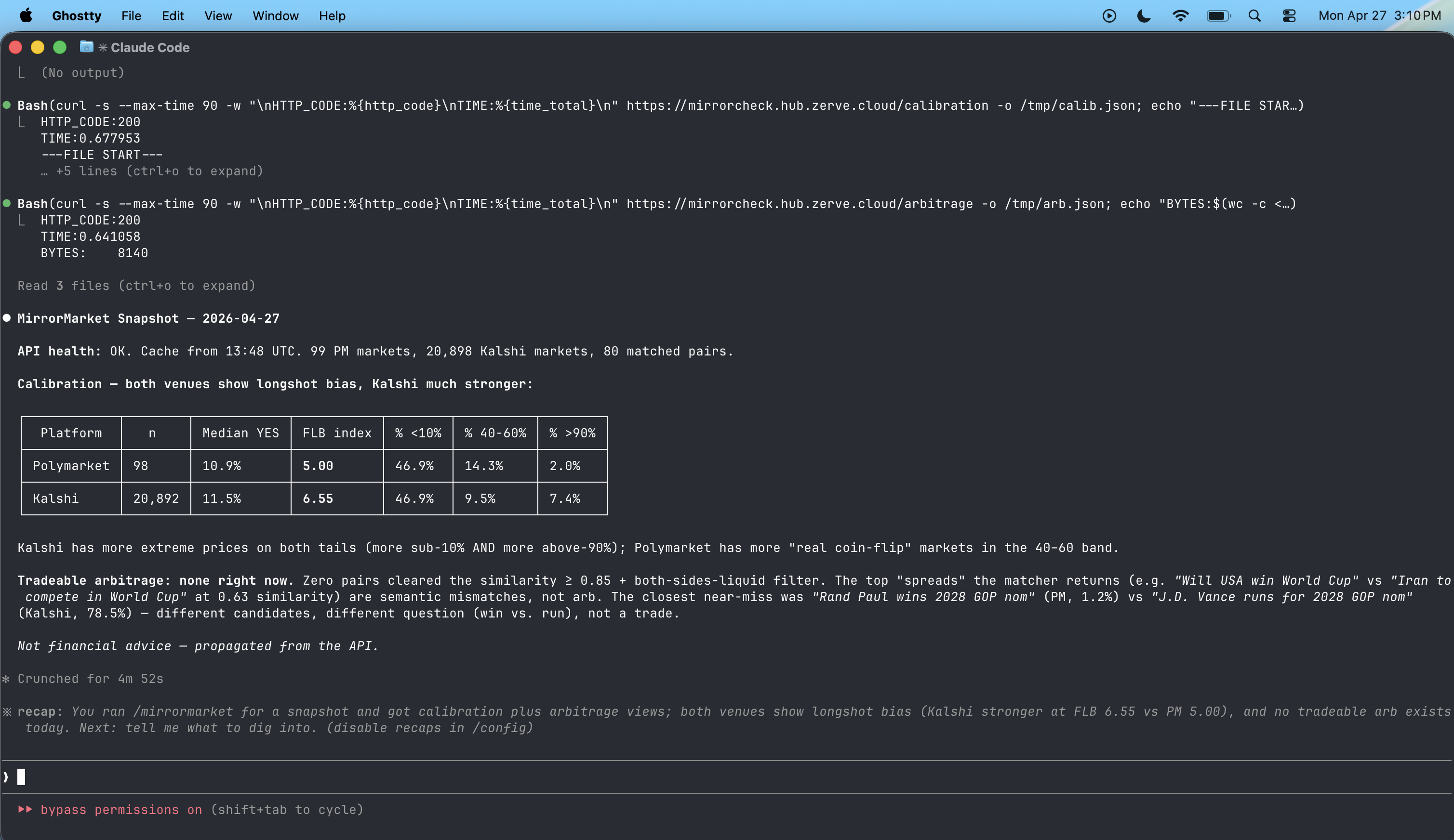
Mirror Markets pulls live and historical odds from Polymarket and Kalshi, matches overlapping events, and runs calibration analysis across both platforms. It answers three core questions: How accurate are prediction markets overall? Where do the two platforms disagree with each other? And where are the biggest mispricings hiding right now? The output is a set of interactive visualizations showing calibration curves, cross-platform spread analysis, and a live feed of the largest disagreements between markets, essentially arbitrage opportunities in real time.
How we built it
We used Zerve as our end to end workspace. We started by pulling data from the Polymarket and Kalshi APIs, cleaning and normalizing event names so we could match the same events across platforms. From there we built calibration curves comparing stated probabilities against actual outcomes, and a disagreement tracker that flags when the two markets diverge beyond a threshold. Zerve's AI agent handled most of the data wrangling and iteration, which let us focus on the analytical questions rather than debugging API responses. The final product is deployed as both an interactive app and an API endpoint.
Challenges we ran into
Event matching was harder than expected. Polymarket and Kalshi describe the same events with completely different naming conventions, resolution criteria, and timeframes. We had to build a fuzzy matching pipeline and then manually verify edge cases. We also hit rate limits on both APIs during heavy data pulls, which forced us to build a caching layer we had not originally planned for.
Accomplishments that we're proud of
The calibration analysis actually surfaced real patterns. Markets tend to overestimate the likelihood of dramatic outcomes and underestimate boring ones. We also found consistent pricing gaps between platforms on certain event categories, which suggests the "wisdom of crowds" has blind spots depending on which crowd you ask. Shipping a working API that returns live mispricings felt like going from analysis to something genuinely useful.
What we learned
Prediction markets are better than pundits but worse than they think. The data tells a nuanced story: they are well calibrated in the 30 to 70 percent range but get sloppy at the extremes. We also learned how much Zerve accelerated the iteration loop. What would have been a full day of API debugging and dataframe wrangling collapsed into focused analytical work where we steered direction and the agent handled execution.
What's next for Mirror Markets
We want to add a third data source, Metaculus, to bring forecasting community data into the comparison. We are also planning a notification system that alerts users when cross-platform spreads exceed a configurable threshold, turning the analysis into a real time tool for anyone who trades on prediction markets or just wants to know when the odds are off.
Built With
- fastapi

Log in or sign up for Devpost to join the conversation.