-
-
-
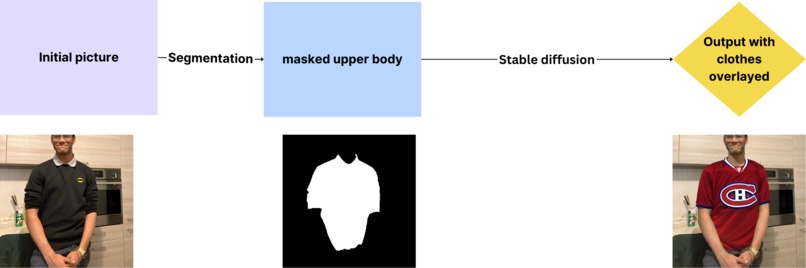
How it works under the hood
-

Works on the back too!
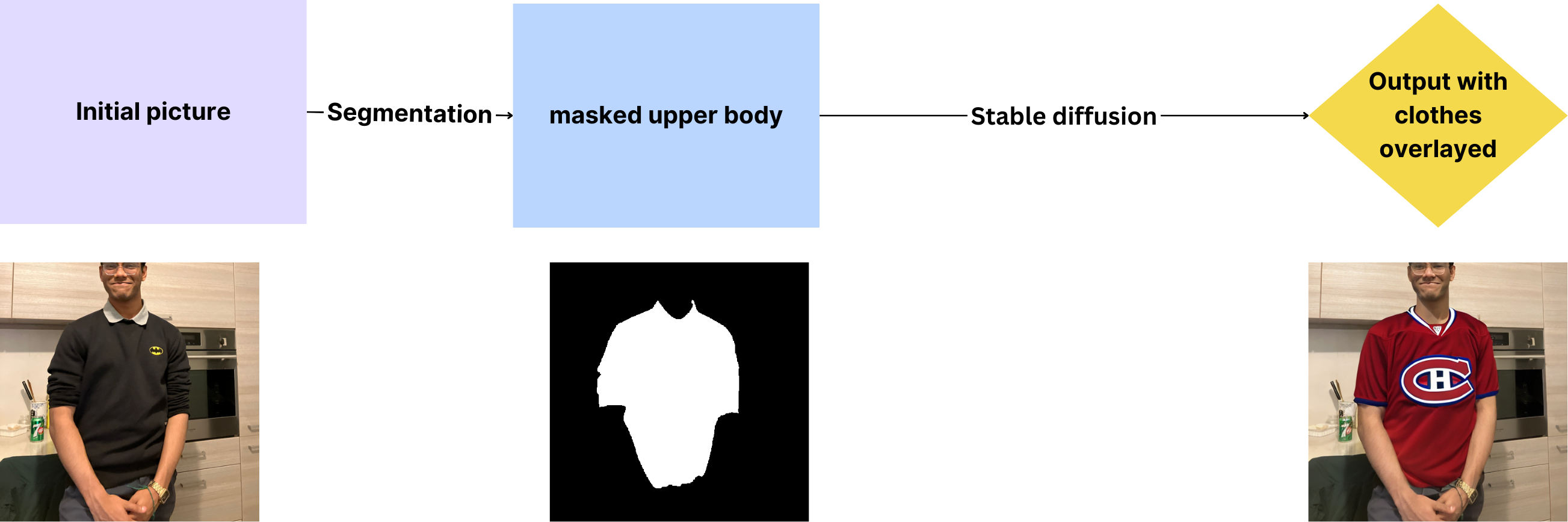

Inspiration
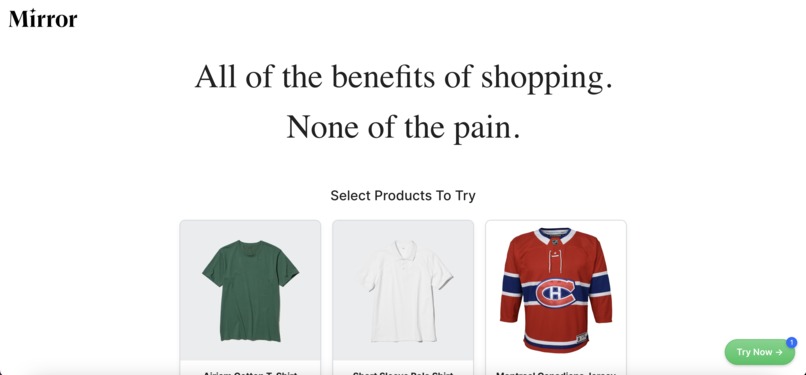
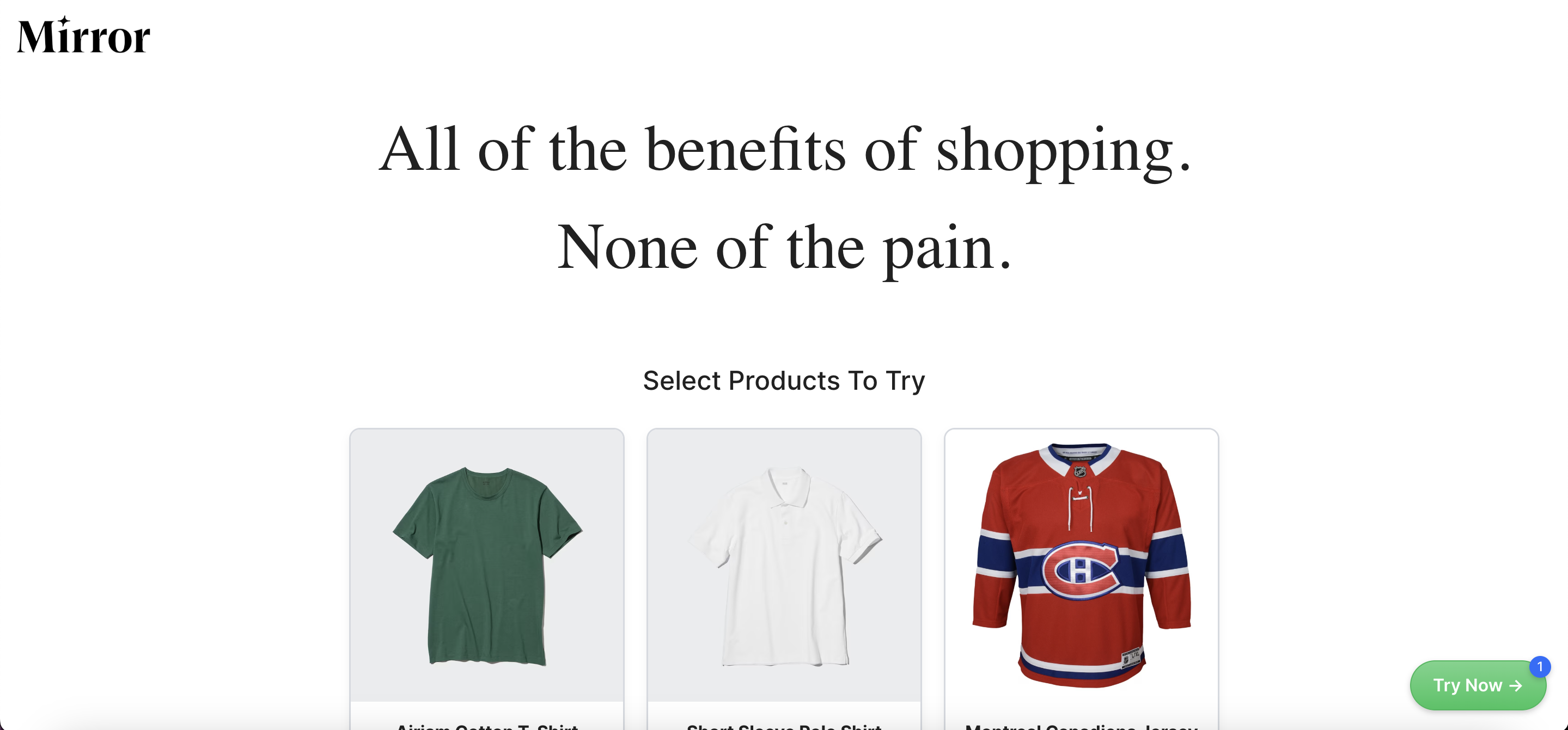
We wanted to build a platform that uses computer vision models to allow people to try on clothing virtually.
What it does
Our product allows users to take pictures of themselves using hand gestures. Then the platform will display the user in different articles of clothing taken from our catalog. The user would also be able to navigate through the pictures by simply swiping with their index finger.
How we built it
We used Stable Diffusion 2, cloth_segmentation, OpenCV, MediaPipe. MediaPipe was useful for capturing hand gestures. OpenCV and cloth_segmentation were useful for pre-processing and masking the clothing on an image. Then, given a description of a clothing article, Stable diffusion 2 would "inpaint" into that masking. To speed up the process we ran the models on a GPU hosted on our own servers.
Challenges we ran into
Virtual try-on models like VITRON exist, but require up to 5 models to pre-process the image before being able to be fed into the main model. This pre-processing is slow (up to 2 minutes), which will slow down the platform, but is also long to implement given the limited time we had to code. By using Stable Diffusion 2, we can achieve good results faster, whilst only having to segment the picture once. This achieved much faster speeds in generating images and maintained the quality of the image. However, Stable Diffusion 2 generates the clothing only using a description of the image, which cannot be perfectly accurate. So our model doesn't give perfectly accurate generated articles of clothing. So we had to make sure that our chat prompts were as accurate as possible in describing the clothes in our catalog. But this can be useful for designers who could describe clothing and see how it would look on models without having to manufacture any clothing.
Accomplishments that we're proud of
The idea of using Stable Diffusion and segmentation was a great workaround to not only speed up the process but also allow us to implement the product. Given the short time frame, we are proud of all the functionality that we were able to implement in our platform.
What we learned
We've learned a lot about Python version discrepancies 😭. But more importantly, we learned a lot about computer vision, image generation, building servers with our own API, and capturing hand gestures.
What's next for Mirror
Adding perfectly accurate image generation using VITRON, would be useful. Also, as these models get faster, we can have the virtual try-on happen in real-time.
Built With
- ai
- augmented-reality
- deep-learning
- python
- svelte











Log in or sign up for Devpost to join the conversation.