-
-
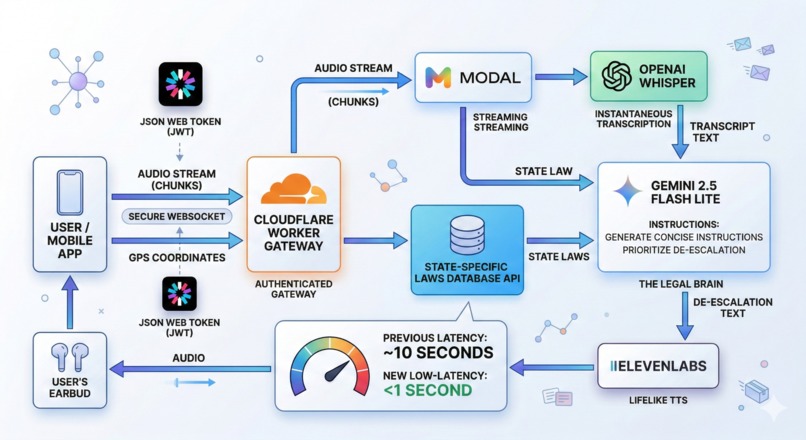
Miranda's tech stack and architecture. This photo was generated with the help of nano banana pro.
-


Inspiration
Law enforcement stops are one of the most common and unpredictable interactions between citizens and police. For many, these moments are fraught with anxiety, confusion over legal rights, and — too often — escalation, with police brutality and unlawful stops being an issue of increased contention in recent years. We built Miranda to level the playing field, providing a "digital legal guardian" that ensures every stop remains transparent, lawful, and safe for everyone involved.
It goes a step further for those with limited English proficiency, helping act as a real-time translator and bridging language barriers. Through this, we hope to help hold law enforcement accountable for their behavior and keep the public safe.
What it does
Miranda is a real-time voice-AI assistant designed to guide drivers through police encounters. When a user gets pulled over and opens the app, Miranda begins listening and dynamically providing guidance.
- Active Guidance: Using a single earbud, the user receives discreet, real-time text-to-speech instructions — what to say, which documents to hand over, how to assert rights safely, and how to avoid being taken advantage of.
- Local Expertise: Miranda uses GPS to determine the user's state and applies local traffic laws to inform its advice.
- Multi-Language Universal Translator: For non-native English speakers, traffic stops are doubly dangerous due to language barriers and discrimination. Miranda translates officer commands into the user's native tongue in real time, while coaching the user to respond in English — so both sides are understood.
- Post-Stop Legal Analysis: Once the encounter ends, the app generates a high-fidelity transcript and a Gemini-powered legal summary identifying potential rights violations and suggesting concrete next steps.
- The Accountability Forum: Users can anonymously share their transcripts and post-stop analysis to a community-monitored forum, surfacing patterns of officer behavior and holding local precincts accountable.
How we built it
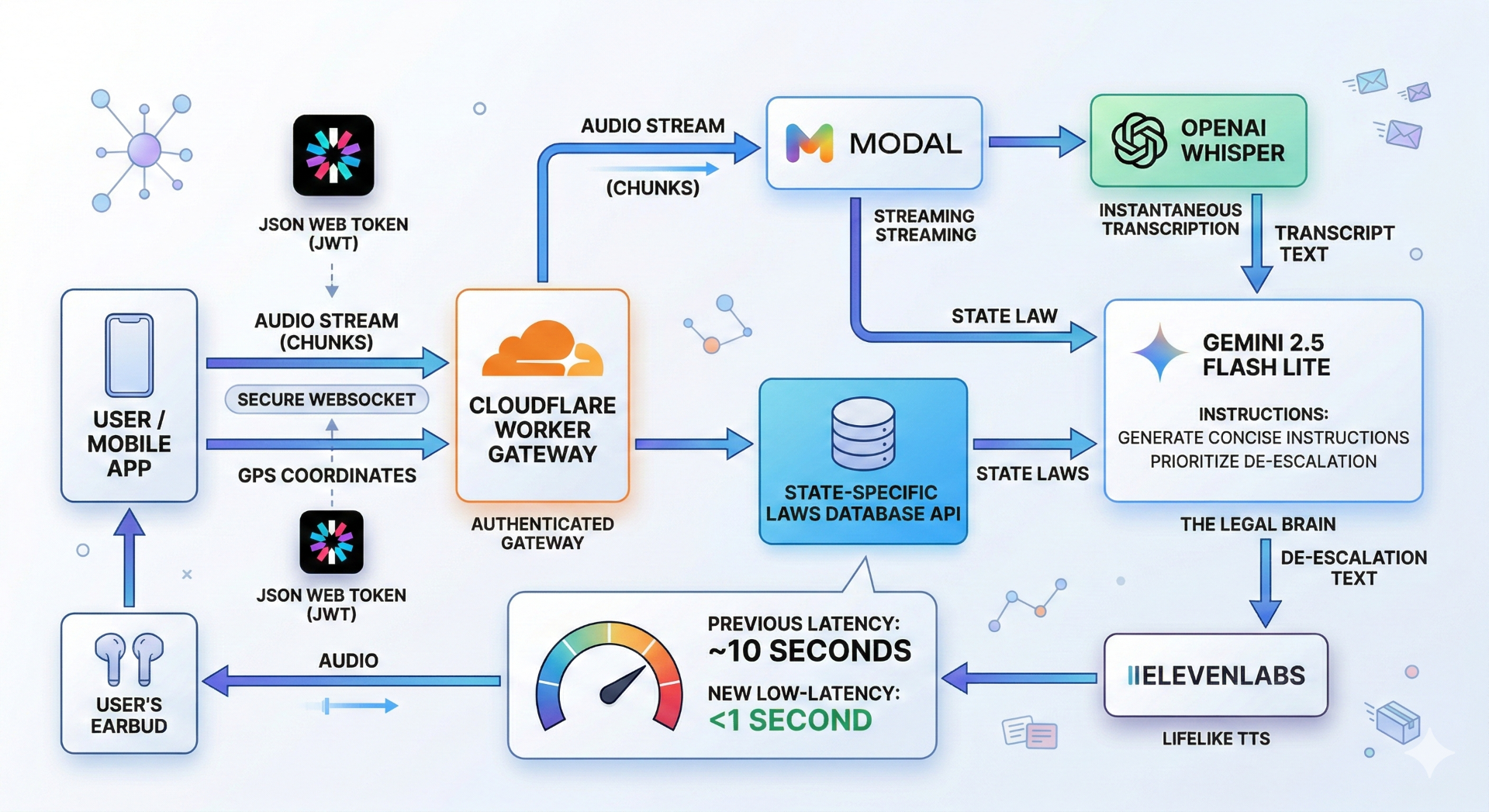
Miranda runs on a three-layer, WebSocket-driven streaming architecture built for sub-second latency at every stage.
Mobile Frontend (React Native / Expo / TypeScript): The app streams 500 ms audio chunks over a persistent WebSocket connection. A custom useTTSPlayback hook accumulates binary audio frames from ElevenLabs and routes them through expo-av to a connected earbud — or falls back to on-screen text and native haptic vibration codes when no earbud is present. A Zustand store tracks the encounter phase (listening → processing → advice) and drives a pulsing animated aura that reflects pipeline state in real time. GPS location is resolved via expo-location, reverse-geocoded, and mapped to a two-letter US state code that is sent to the backend as session metadata.
Processing Backend (Python / Modal): Each audio chunk passes through Silero VAD to gate silence. On a detected speech pause, the accumulated window is fed directly to faster-whisper large-v3-turbo running on a Modal T4 GPU as a raw float32 numpy array — no temp files, no WAV encoding — yielding ~200 ms transcription latency versus 1.5–3.5 seconds for the hosted OpenAI API. The transcript feeds into Gemini 2.5 Flash Lite, which receives the rolling conversation history, the driver's state, a 50-state static traffic law lookup, and real-time emotion tags derived from acoustic features. Gemini produces a single legally grounded instruction which is streamed through ElevenLabs Turbo v2 TTS as binary audio chunks back to the app over the same WebSocket. At session end, Gemini runs a second pass to diarize the full transcript (officer vs. driver) and produce a structured legal summary report.
Edge & Storage (Cloudflare): Cloudflare D1 backs the community forum, storing anonymized post-encounter summaries. Cloudflare Workers handle WebSocket upgrade, JWT verification, and routing between the mobile client and Modal backend.
Latency engineering was a first-class concern throughout. Key optimizations included: direct numpy array inference into Whisper on Modal (eliminating 30–50 ms of per-utterance disk I/O), per-language Gemini system prompt caching (avoiding prompt reconstruction on every call), a 5-second asyncio timeout guard around every Gemini inference call to prevent event-loop stalls, and chunked JS base64 encoding for TTS audio blobs to keep the React Native thread unblocked.
Challenges we ran into
The most significant challenge was driving latency out of the officer-speech → advice pipeline. Early builds took over 30 seconds end-to-end. The gains came from many small decisions: choosing local GPU inference over the hosted Whisper API, switching to faster-whisper's numpy input path, streaming TTS chunks over the WebSocket instead of waiting for a complete audio file, and careful async task scheduling on the Modal backend to keep processing and audio streaming from blocking each other.
Multi-language support introduced a subtle prompt engineering challenge: Gemini had to produce spoken phrases always in English (so the officer understands them) while writing physical action instructions in the driver's native language. Getting this boundary reliably enforced across 20 languages — without examples for every one — required several iterations of prompt restructuring.
iOS audio session management was unexpectedly complex. Switching between microphone recording mode and speaker playback mode interrupts the mic for 300–600 ms. We resolved this by staying in PlayAndRecord mode permanently and only switching modes for non-earbud playback, accepting minimal echo as a trade-off for uninterrupted recording.
Accomplishments that we're proud of
- End-to-end latency under 1.5 seconds from the officer's last word to the driver hearing legal advice — down from over 30 seconds in our first build. That delta is the difference between useful and useless in a real encounter.
- 20-language real-time support, with spoken phrases kept in English for officer clarity and action instructions delivered in the driver's native language. A Spanish-speaking driver hears "Salga del vehículo con calma" while the officer hears "I do not consent to any searches" — bridging the language gap in both directions simultaneously.
- A functioning accountability forum backed by real Cloudflare D1 infrastructure, giving users a genuine outlet to surface patterns of officer behavior beyond their individual encounter.
- A complete, production-grade inference pipeline: GPS state detection → 50-state law lookup → real-time Whisper transcription → Gemini legal counsel → ElevenLabs TTS delivery, all wired together end-to-end and reliably handling an entire traffic stop scenario.
- Legally grounded advice quality: the system correctly distinguishes legally required responses (handing over documents) from optional ones (consenting to a search), and adapts its advice to the specific laws of the driver's state.
What we learned
- Real-Time Audio Pipelines are Brutally Unforgiving. There is a massive difference between a pipeline that "works" and one that is "fast enough to be useful." In a chat interface, a user doesn't mind waiting three seconds for a response. In a traffic stop, a three-second delay after an officer asks a question makes the driver look suspicious, evasive, or impaired. When you string together a 5-stage pipeline—audio chunking, Voice Activity Detection (VAD) to find pauses, Whisper for transcription, Gemini for legal reasoning, and ElevenLabs for Text-to-Speech (TTS), latencies stack exponentially.
- The Modal Advantage. By deploying our Whisper pipeline directly on serverless GPUs using Modal, we bypassed the public API bottlenecks. We pulled inference times down to around 200ms. That speed reduction is exactly what made the transition from a "cool proof of concept" to a "viable, real-time survival tool" possible. It allowed us to keep the compute heavy-lifting off the mobile device while maintaining edge-like speeds.
- Building with Legal Stakes Forces Rigid Rule Adherence. When building Miranda, an edge case is bad legal advice that can escalate a traffic stop or result in an arrest. This completely shifted our engineering mindset from standard "prompt engineering" to strict legal compliance. You have the absolute right not to answer questions, but you are legally required to provide your driver's license and registration. If the AI hears an officer ask for ID and simply advises the driver to "remain silent and refuse," the app is actively instructing the user to break the law. That isn’t a software bug—it’s a failure of legal protocol.
What's next for Miranda
- Emergency Contact Integration: Automatically pinging a trusted contact or legal representative with a live transcript link if the app detects the user is being detained or arrested. Dashcam Sync: Linking the audio transcript with the phone's camera feed for a complete, synchronized record of the encounter.
- Attorney Marketplace: Connecting post-encounter legal summaries directly to licensed local attorneys who can review the transcript and provide professional follow-up counsel.
- Proactive Know-Your-Rights Education: A pre-encounter mode that walks users through their state-specific rights before a stop, so they are prepared before the situation is stressful.
Built With
- api
- claude
- cloudflare
- elevenlabs
- expo.io
- gemini
- modal
- native
- node.js
- openai
- python
- react
- silero
- typescript
- vad
- whisper
- workers





Log in or sign up for Devpost to join the conversation.