Inspiration
Every software project starts with optimism. A deadline is set, a team is assembled, and everyone agrees it's "totally doable." Then Week 4 hits. The senior developer is stuck unblocking three juniors, the payment API integration takes twice as long as expected, and suddenly the deadline feels like a suggestion.
We've all lived this — or watched it happen. Studies consistently show that 70% of software projects fail to meet their original deadline, and the root cause is almost never a lack of effort. It's a lack of accurate foresight. Teams estimate with gut feel, spreadsheets, and optimism bias, when what they need is probabilistic reasoning.
That's what inspired PlanSight. Not another project management tool. Not a prettier Gantt chart. A system that stress-tests your plan before you start building — that asks "what could go wrong?" and answers with data, not vibes.
What it does
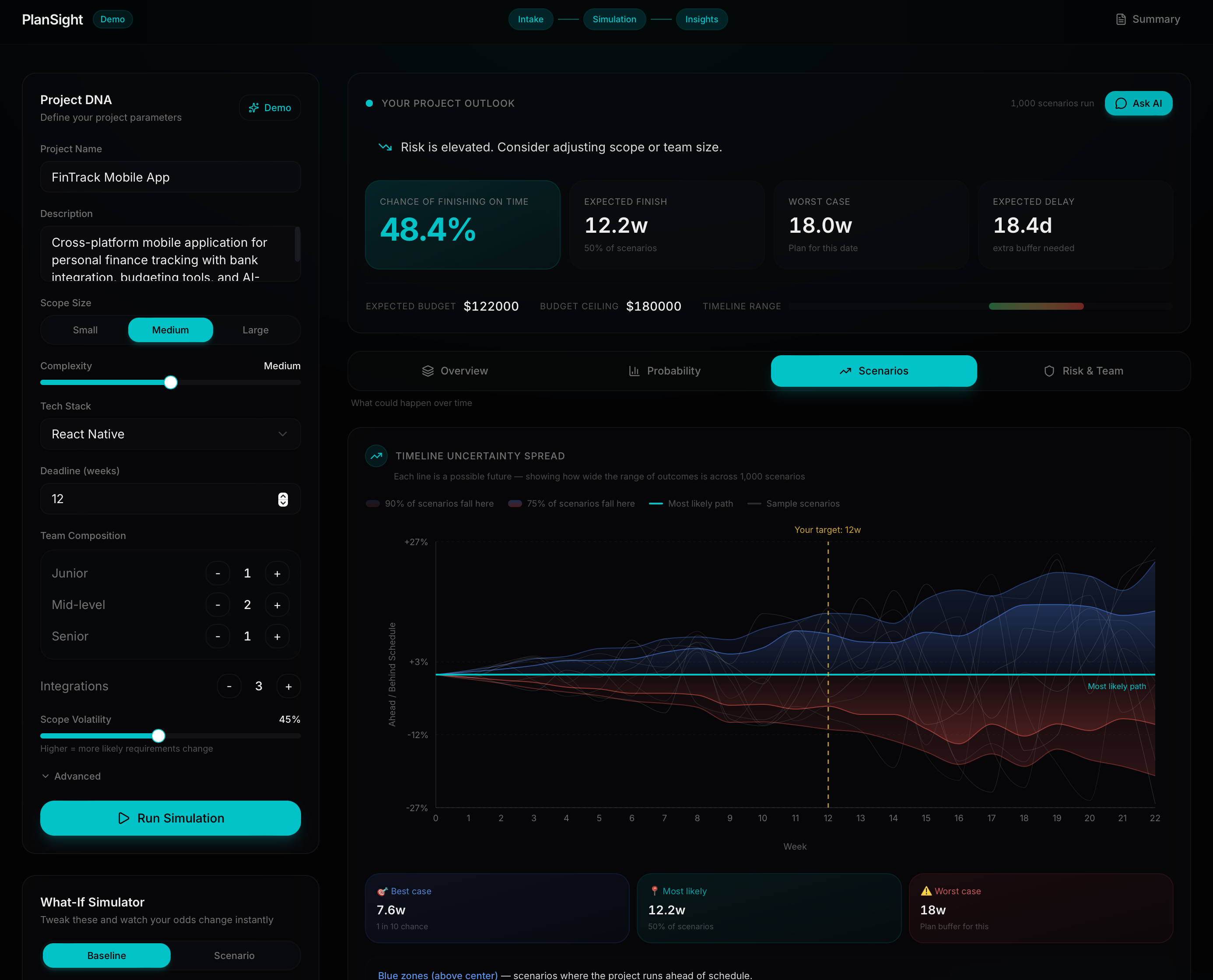
PlanSight transforms raw project requirements into a data-driven execution plan. A team fills in a simple intake form — project scope, tech stack, team composition, integrations, deadline — and the system does the rest.
The Predictive Engine runs 1,000 Monte Carlo simulations to produce a probability distribution of completion timelines. Instead of a single estimate ("12 weeks"), you get a full picture: there's a 61% chance you finish on time, a median estimate of 11.2 weeks (P50), and a worst-case of 15.4 weeks if things go sideways (P90).
The Risk Radar scores four independent risk axes deterministically — integration complexity, team imbalance, scope creep, and learning curve — each explained in plain English rather than raw numbers.
The Team Stress Index calculates burnout risk from timeline compression, role overload, and parallel task density, flagging teams heading toward unsustainable pace before it happens.
The Execution Blueprint uses a locally-running AI model (gemini-3-flash-preview via Ollama) to generate a phased, project-specific delivery plan — with real tasks mentioning your actual stack and project name, go/no-go checkpoints, and a critical path analysis — all running in the background while you explore other tabs.
The What-If Simulator lets you ask "what happens if I remove a senior developer?" or "what if I add two more integrations?" in real time — the simulation reruns instantly and every metric updates.
The Executive Summary generates five sentences of C-level prose via Gemini API, ready to paste into a stakeholder update.
The Conversational Advisor (ElevenLabs) lets you talk to your simulation results — a voice agent pre-loaded with every metric, every risk score, every task from the execution plan, so its spoken analysis is always consistent with what's on screen.
How we built it
The system is split into two layers that work together: a deterministic engine for reproducible calculations, and a probabilistic engine for uncertainty modelling.
Backend (FastAPI + Python) The deterministic layer computes base effort in dev-days using scope size, stack complexity (WSCI — Weighted Stack Complexity Index), integration count, team seniority ratios, and a dependency clustering penalty. This feeds directly into the Monte Carlo simulation, which runs N trials where each trial applies four independent stochastic perturbations: scope growth (normal distribution), integration delays (log-normal, right-skewed for rare catastrophic delays), experience variance (normal, wider for junior-heavy teams), and unexpected events (log-normal). NumPy handles all of this in under 100ms for 1,000 runs.
Risk scores, team stress, cost projections, and role allocation are all computed deterministically from the same inputs — no simulation needed.
AI Integration (Three-Model Stack)
We used three AI systems for different jobs. Google Gemini (gemini-2.0-flash) handles the failure forecast, task blueprint, and executive summary via the cloud API. Ollama with gemini-3-flash-preview runs locally to generate the execution plan — we chose local inference here so the plan generation is fast, private, and free of API rate limits. ElevenLabs provides the conversational advisor, which receives all simulation outputs as structured dynamic variables so the voice agent's answers are grounded in the actual data.
Frontend (Next.js + TypeScript + Recharts) All AI calls are fired as background promises the moment "Run Simulation" is clicked — the execution plan and executive summary start generating while the user is reading the hero metrics, so by the time they click the Overview tab, the plan is ready. Global React context manages all state so switching tabs never re-triggers any fetch. The UI was designed for non-technical users: plain-language labels, animated metric reveals, and an execution plan that reads like a delivery roadmap rather than a statistics report.
Challenges we ran into
Getting the statistical model right was harder than expected. Our first version of the Monte Carlo engine produced counterintuitive results — adding more developers sometimes increased the expected timeline. The bug was subtle: we were computing effort in total dev-days but forgetting to divide by team size to get calendar time. Once we fixed that, every metric moved in the expected direction.
The gemini-3-flash-preview model is a thinking model. It prefixes its JSON output with a thought\n block before the actual structured response. Our JSON parser would fail silently, falling back to the static plan every time. The fix was simple — scan forward to the first { character — but it took careful debugging to identify.
Token budget. The execution plan prompt asks for a multi-phase JSON object with tasks, risks, milestones, and checkpoints. At num_predict: 2048, the response was being truncated mid-string, producing invalid JSON. Raising it to 8192 resolved it, but it meant we had to be careful about prompt length to keep latency reasonable.
Keeping the ElevenLabs advisor consistent with the UI. If the voice agent generated its own task list independently, it would contradict the execution plan already displayed on screen. The solution was to serialise the entire Ollama-generated plan into dynamic variables passed to the ElevenLabs widget — the system prompt then instructs the agent to treat that as the authoritative source of truth and never regenerate tasks independently.
API quota exhaustion. During development, we burned through Gemini free-tier limits faster than expected due to long prompts. We shortened all prompts significantly, added aggressive fallback logic at every layer, and ensured the static fallbacks are project-aware (using the actual project name, stack, and risk scores) rather than generic boilerplate.
Accomplishments that we're proud of
Getting a genuinely useful three-model AI stack working end-to-end — local Ollama, cloud Gemini, and ElevenLabs — each doing a distinct job it's actually suited for, with a graceful fallback chain so the product works even when individual AI services are unavailable.
The statistical model produces intuitive, defensible results: increasing team size reduces timeline, increasing complexity or integrations increases risk, junior-heavy teams show higher variance. Every number is traceable to a formula.
The ElevenLabs advisor being contextually aware of the specific project on screen — including the AI-generated task list — felt like a real breakthrough moment. You can ask it "which phase has the most risk?" and it answers from the actual Ollama plan, not a generic response.
The execution plan generating in the background while the user reads other results — with no visible loading state on the Overview tab when they arrive — was a small UX detail that made the product feel significantly more polished.
What we learned
Probabilistic thinking is hard to communicate. The biggest UX challenge wasn't building the simulation — it was presenting a probability distribution to users who just want to know "will this ship on time?" We learned to lead with plain-language headlines and bury the math in accordions. "Decent odds, but a bit of buffer time would help" lands better than "P50: 11.2w, P90: 15.4w."
Local AI inference is genuinely viable for structured tasks. Running gemini-3-flash-preview locally via Ollama for the execution plan was fast enough (10–20s) that users perceived it as a background task rather than a blocker. For structured JSON generation with a well-constrained prompt, local models are a serious alternative to cloud APIs.
Fallback design is a feature, not an afterthought. Every AI call in PlanSight has three layers: primary (Ollama or Gemini), secondary (the other one), and a deterministic fallback that uses the actual project inputs to generate a contextual response. This meant the demo worked even when APIs were rate-limited or unavailable.
The gap between a working prototype and a demo-ready product is almost entirely UX. The math worked on day one. Getting the animations, plain-language labels, accessible layouts, and tab-switching behaviour to feel smooth took as long as the entire backend.
What's next for MirageAI
Historical calibration. Allow teams to upload a CSV of past projects (scope, team, stack, actual duration) and use regression to recalibrate the WSCI and experience factor multipliers for their specific organisation. This makes every future estimate more accurate.
Scenario saving and comparison. Let users save multiple What-If scenarios side by side — "Option A: hire one senior" vs "Option B: cut two integrations" — with a comparison table of all key metrics.
Team velocity integration. Connect to Jira, Linear, or GitHub to pull real sprint velocity data and use it to replace the static seniority-based experience factor with actual team-specific performance history.
Persistent project tracking. Right now PlanSight is stateless — every simulation starts fresh. Adding a lightweight database would let teams re-simulate as the project progresses and track how the probability of on-time delivery evolves week by week.
Expanded stack coverage. The WSCI table currently covers ~15 stacks. A larger lookup table — or a small trained model — would give more accurate complexity estimates for emerging stacks.

Log in or sign up for Devpost to join the conversation.