-
-

title
-

hero
-
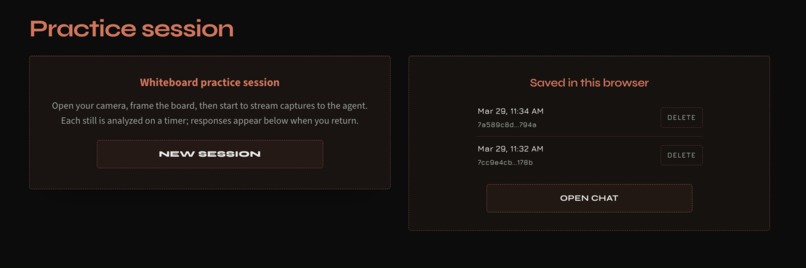
sessions page
-
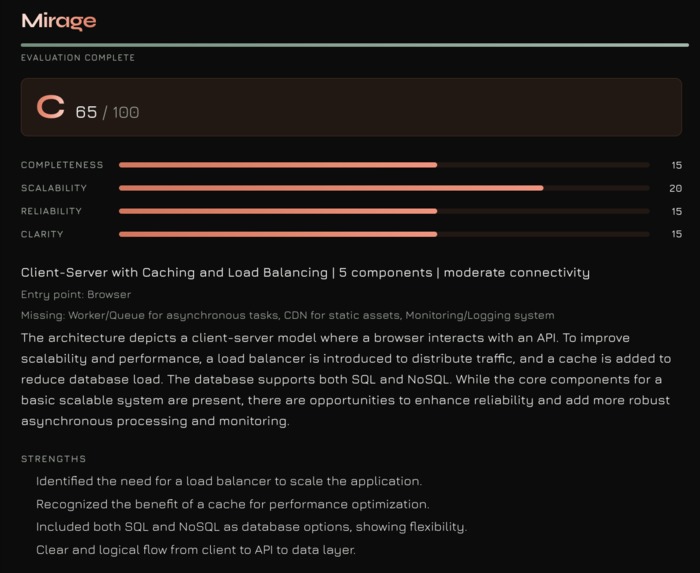
analysis section
-
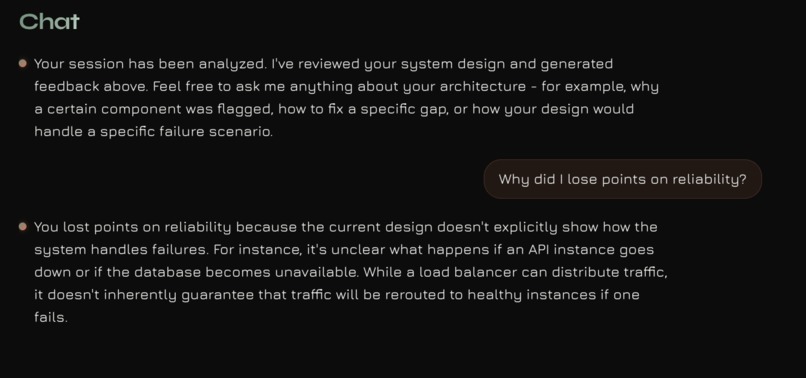
chat section


About Mirage
Inspiration
System design interviews are a gatekeeping ritual in software engineering hiring. The problem is not that the concepts are too hard. The problem is that practicing them is inaccessible. Mock interviews cost money, require scheduling, and depend on finding someone senior enough to give useful feedback. Most people walk into these interviews having never practiced out loud on a whiteboard even once.
We wanted to change that. Mirage gives anyone a patient, knowledgeable practice partner available at any time, one that watches you think, builds a model of your architecture in real time, and tells you exactly where your design breaks down.
What We Built
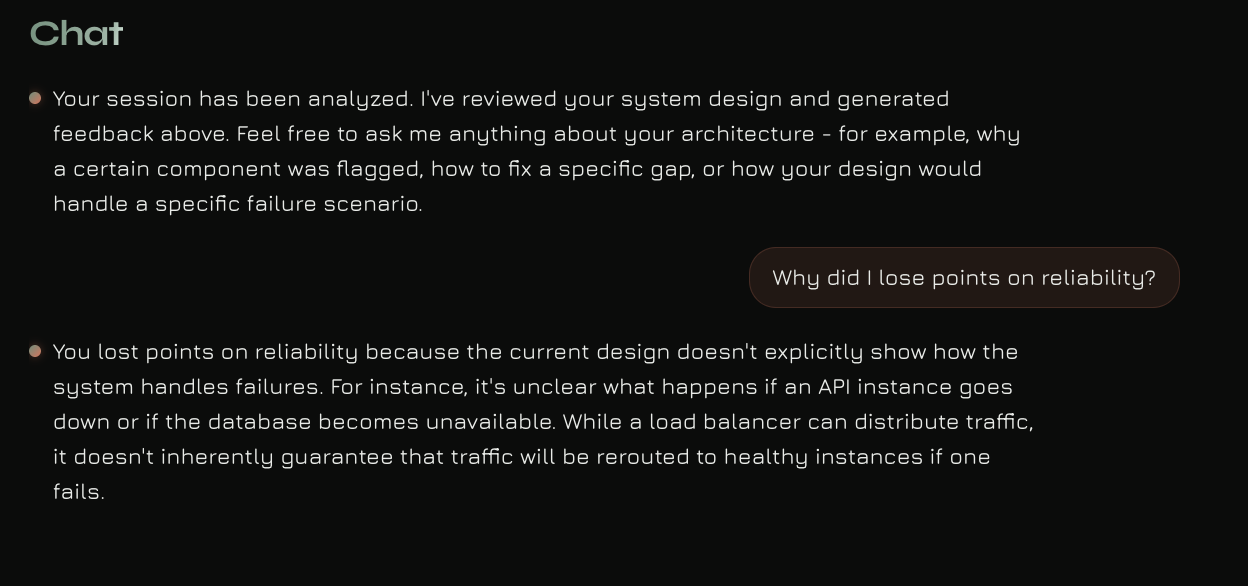
Mirage is an AI-powered system design coach. You open your camera, point it at a whiteboard, and start designing. While you work, Mirage watches the board and listens to your reasoning. When you finish, it delivers a structured analysis of your architecture with scores, specific feedback, and a chat interface so you can dig into the results.
The core of the system is a live node-based architecture graph. Every component you draw (services, databases, caches, load balancers) becomes a node. Every arrow becomes an edge. The AI agent updates this graph in real time as changes appear on the whiteboard, building a structured representation of your design rather than just looking at raw images. When the session ends, we run a breadth-first traversal starting from the entry point to serialize the full architecture in connection order, giving the analysis agents a structured, traversal-aware representation of your design rather than a flat list of components.
After the session, a three-stage pipeline runs automatically:
- Transcription - your verbal reasoning is transcribed from the recorded audio
- Validation - a second agent cross-references the transcript against the visual graph to catch OCR errors and fill in missed components
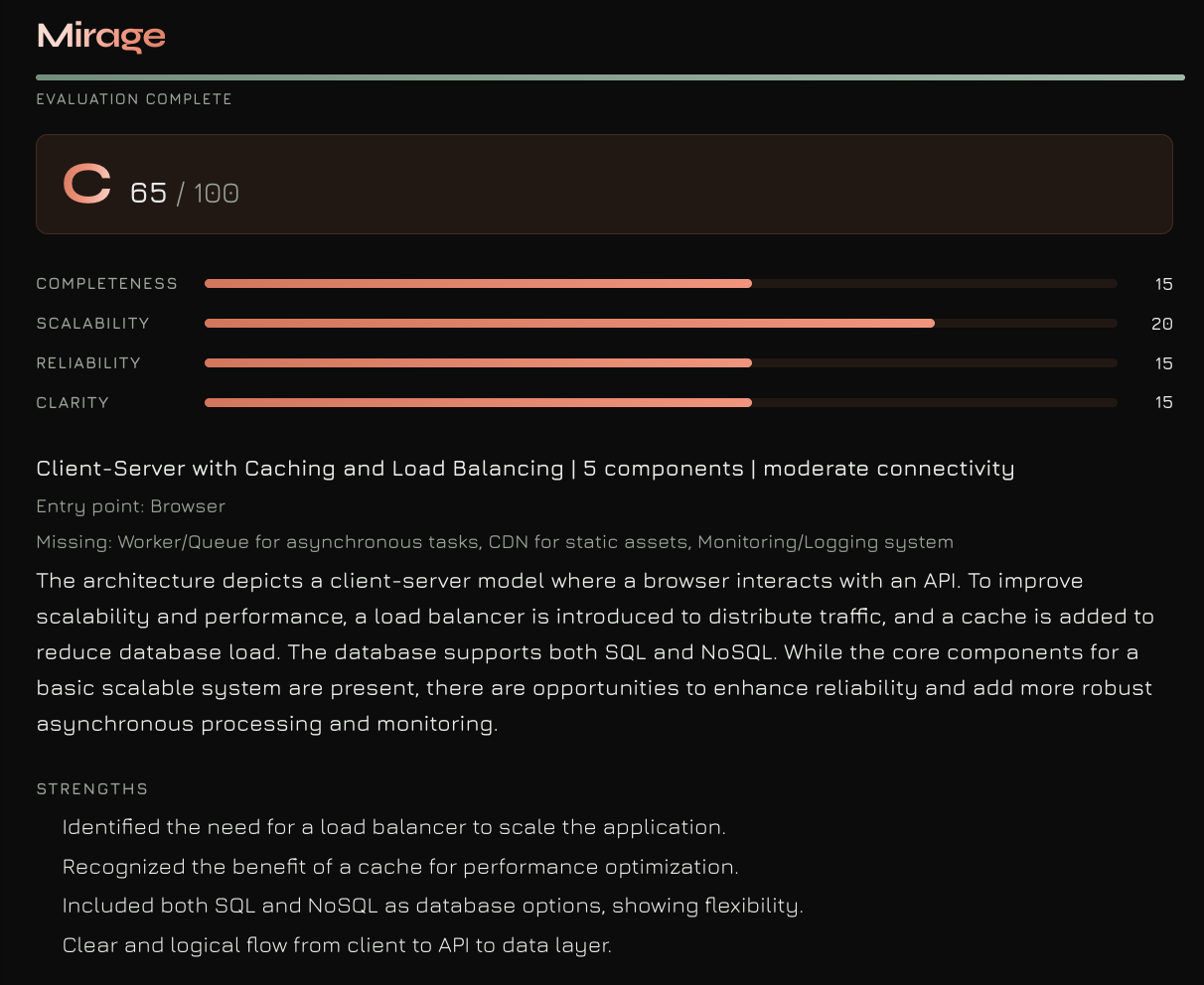
- Analysis - a scoring agent grades your design across four rubric dimensions
The final score is computed as:
$$S = S_{\text{completeness}} + S_{\text{scalability}} + S_{\text{reliability}} + S_{\text{clarity}}$$
where each dimension is worth up to 25 points, giving a total out of 100 with a corresponding letter grade.
How We Built It
Frontend: Vue 3 with TypeScript and TailwindCSS. The session view manages camera access, frame capture, and audio recording entirely in the browser. A polling composable handles waiting for post-session analysis to complete and populates the results view once ready.
Backend: A Python async server built with Starlette and Uvicorn, structured around three specialized LangChain agents powered by Google Gemini 2.5.
Visual Delta Pipeline: Instead of feeding raw images into the LLM on every frame, we built a pre-processing pipeline that runs person detection (YOLOv8), frame similarity checks, and Gemini Vision description to produce plain-text change summaries. The agent only ever sees descriptions like "a box labeled Redis Cache was drawn with an arrow from API Service." This makes the system faster, cheaper, and privacy-preserving.
Persistence: MongoDB stores completed sessions with the full architecture graph, transcript, validation output, and analysis results, scoped to authenticated users via Clerk.
Challenges
Making vision reliable on messy whiteboards. Real whiteboard handwriting is noisy. OCR alone was not enough. We solved this by layering Gemini Vision on top of traditional image processing and adding a dedicated validation agent that reconciles what was seen with what was said. The two sources of truth together produce a much more accurate graph than either alone.
Designing a scoring rubric that is fair and useful. A score is only helpful if the user understands why they got it. We iterated on the rubric structure so that every deduction maps to a specific, actionable piece of feedback rather than a vague penalty.
Keeping real-time feedback from feeling like noise. The agent processes frames every 15 seconds and could produce constant commentary. We tuned the agent's decision rules so it only speaks when it has something meaningful to say, preserving the feel of a focused practice session rather than a running commentary.
What We Learned
Building Mirage taught us that the hardest part of an AI product is not the model. It is the data pipeline around the model. Getting clean, structured input from a messy real-world source (a hand-drawn whiteboard) required more engineering than the AI integration itself. The visual delta pipeline, the frame filtering, and the validation reconciliation step were all solutions to the fundamental problem of garbage in, garbage out.
We also learned that multi-agent architectures shine when each agent has a narrow, well-defined job. Separating real-time graph mutation, post-session validation, and scoring into three distinct agents made each one easier to reason about, test, and improve independently.
Built With
- clerk
- fastapi
- langchain
- python
- tailwind
- typescript
- vue



Log in or sign up for Devpost to join the conversation.