-
-
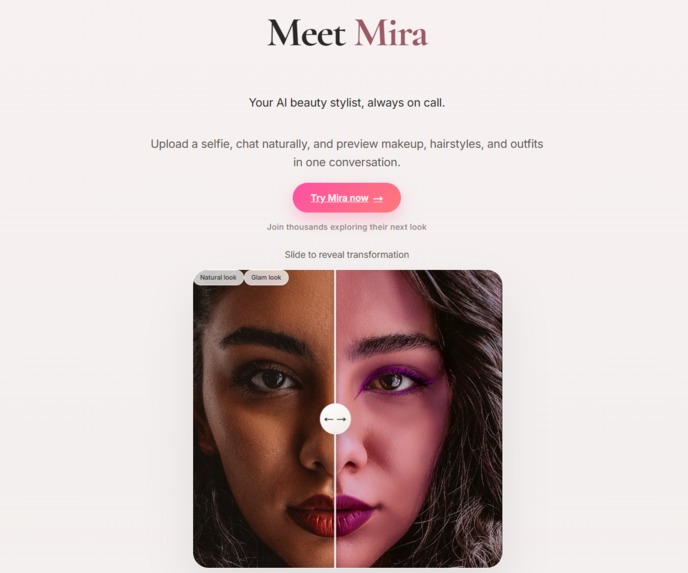
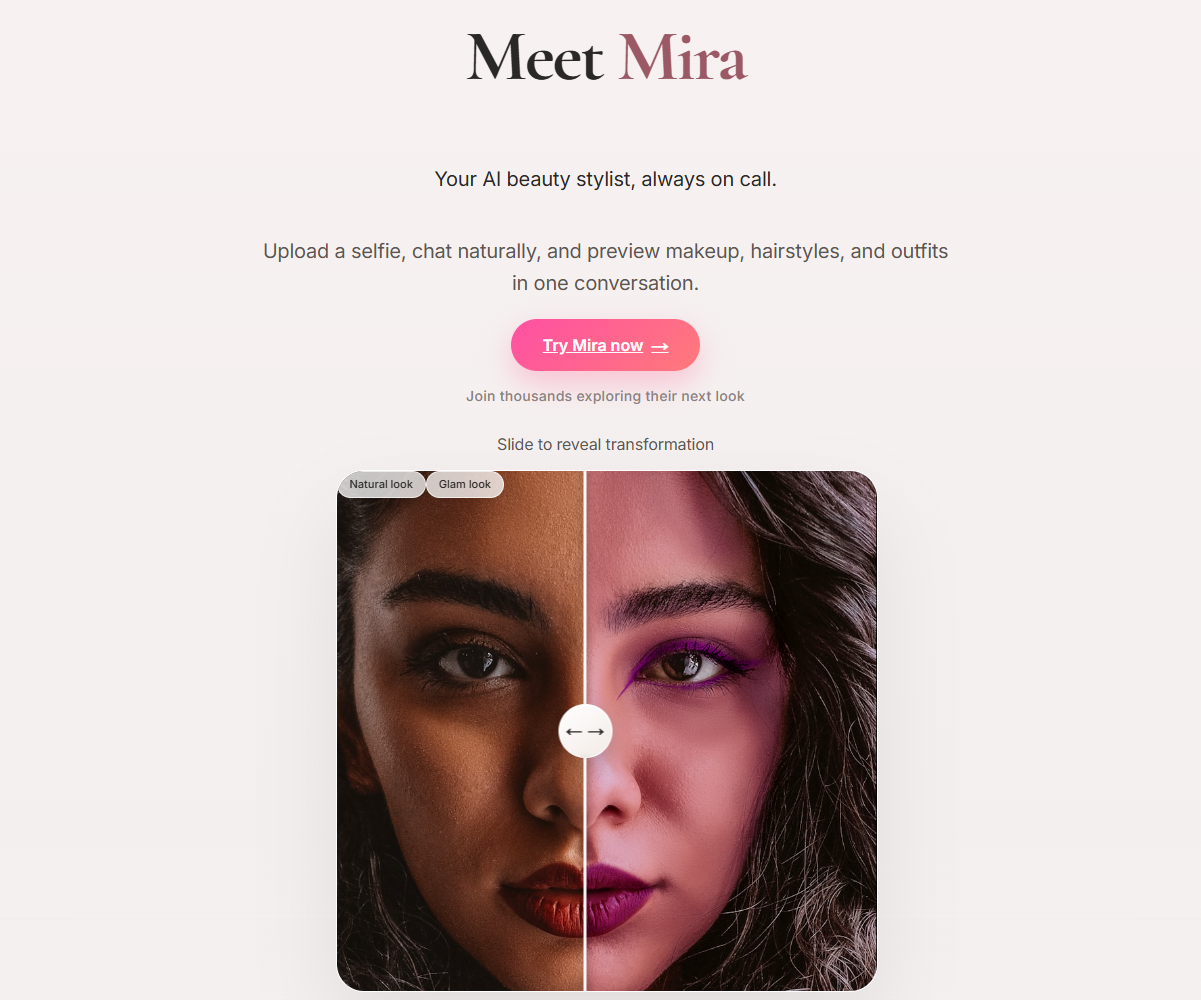
Mira Landing Page
-
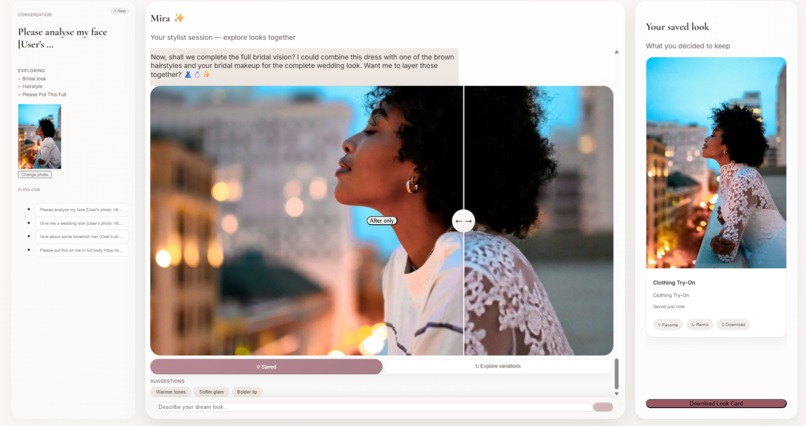
Compare looks on the go
-
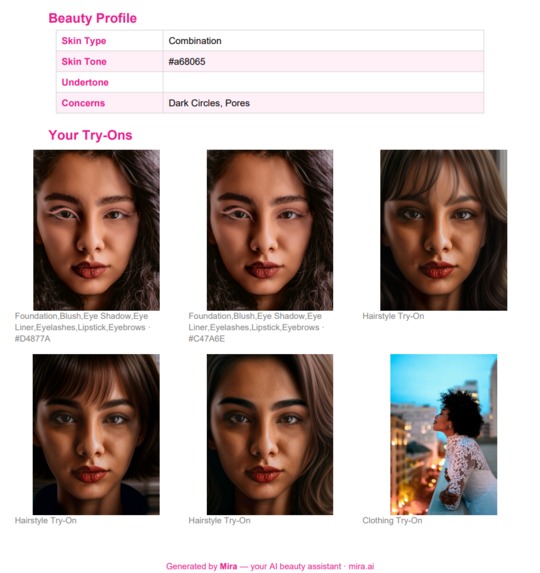
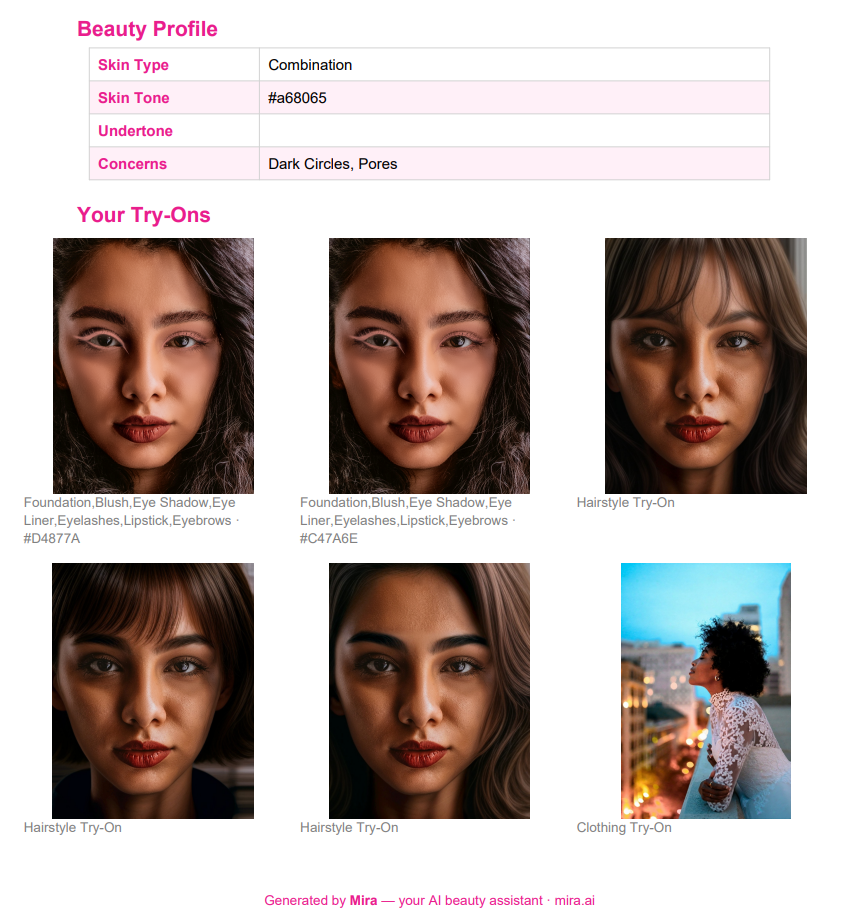
Look Card
-
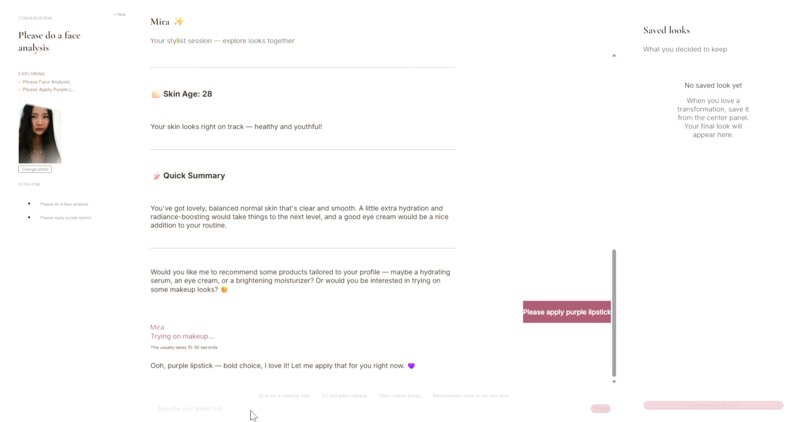
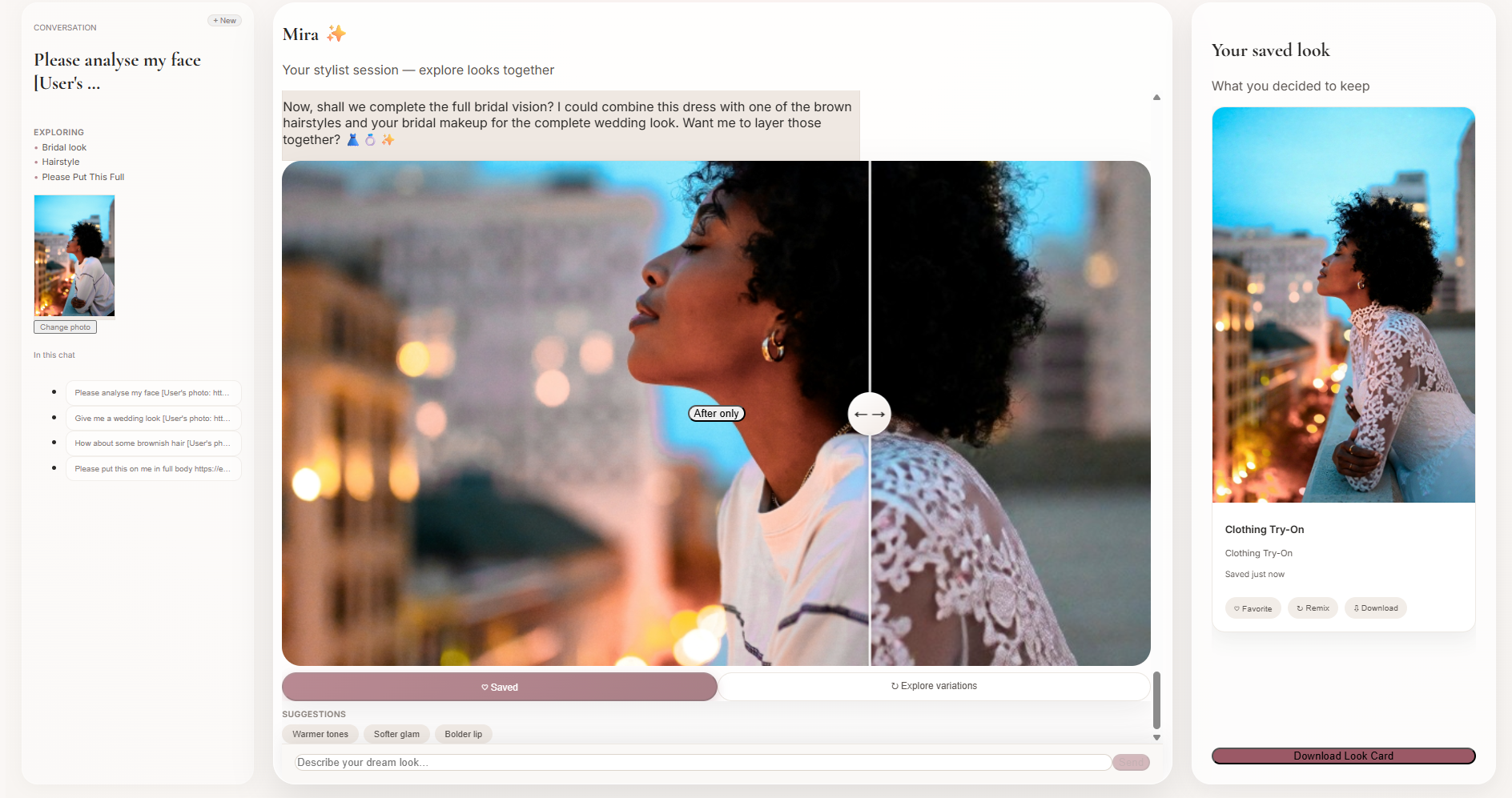
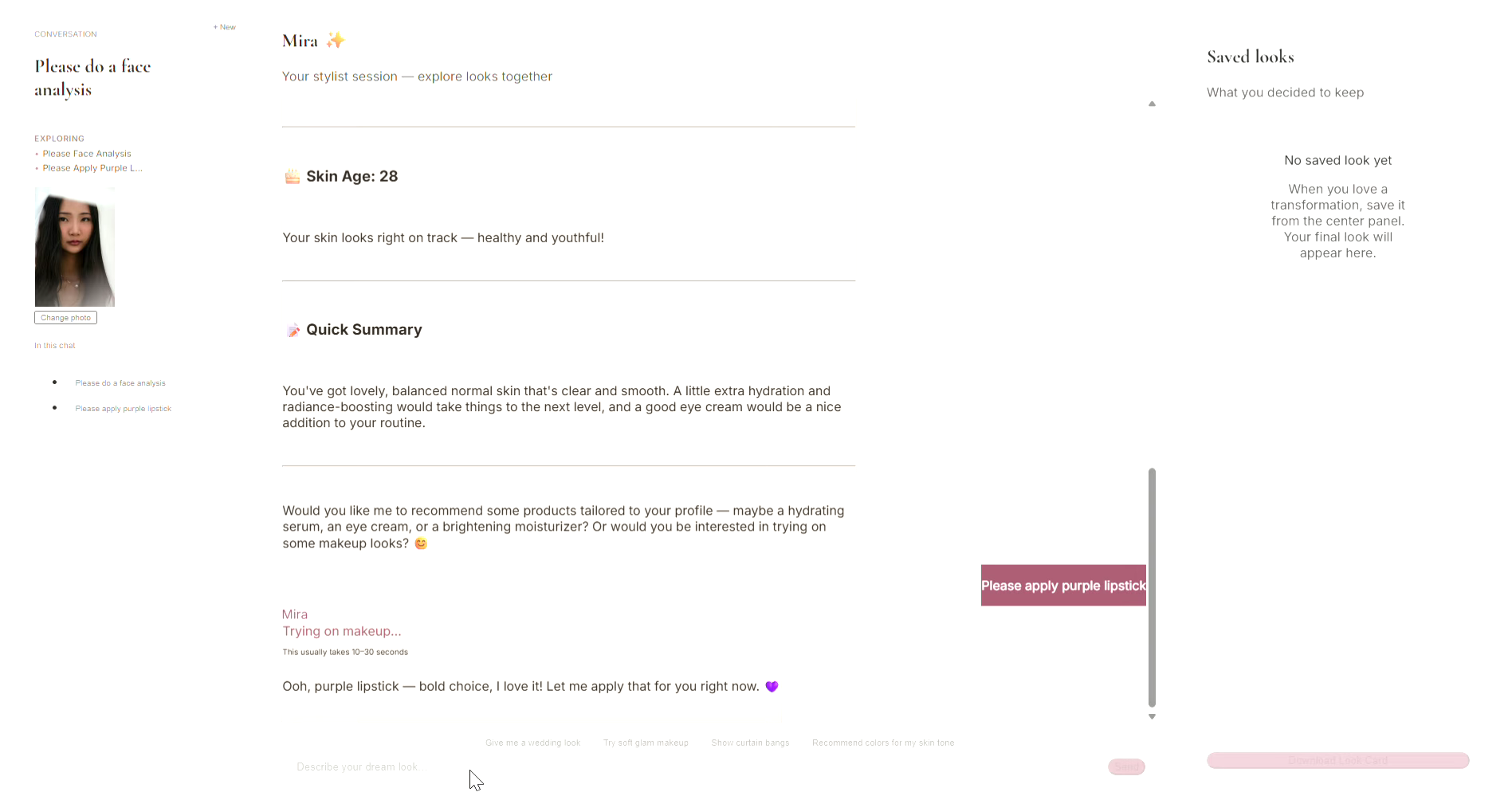
Chat in Progress
-
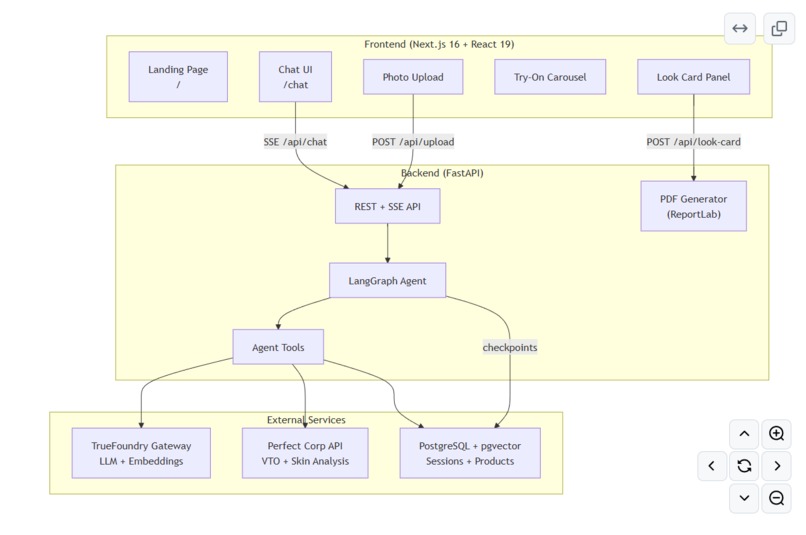
Architecture
-
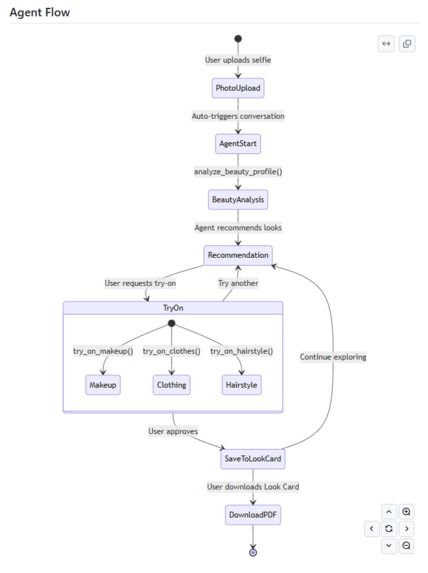
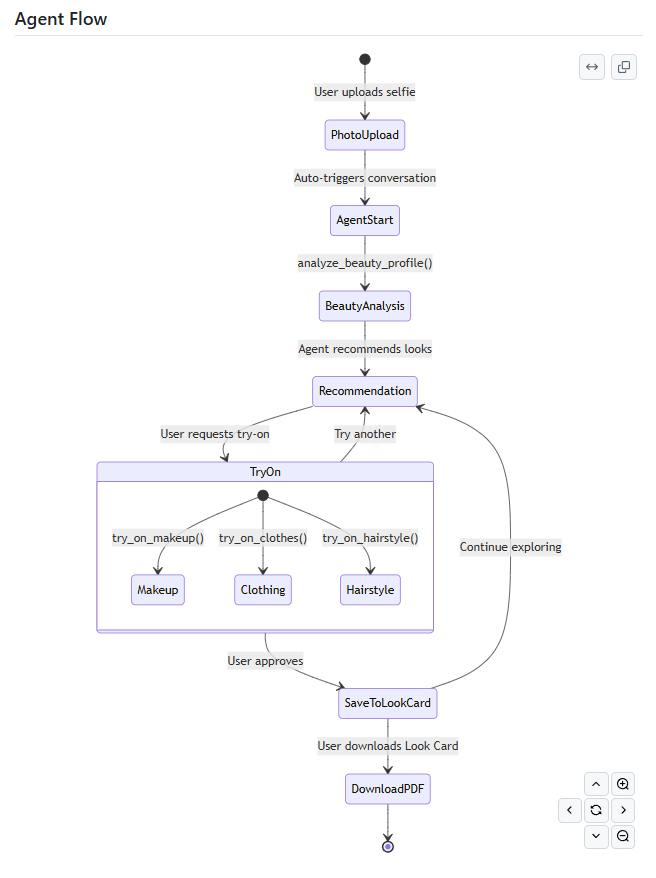
Agent Flow
-
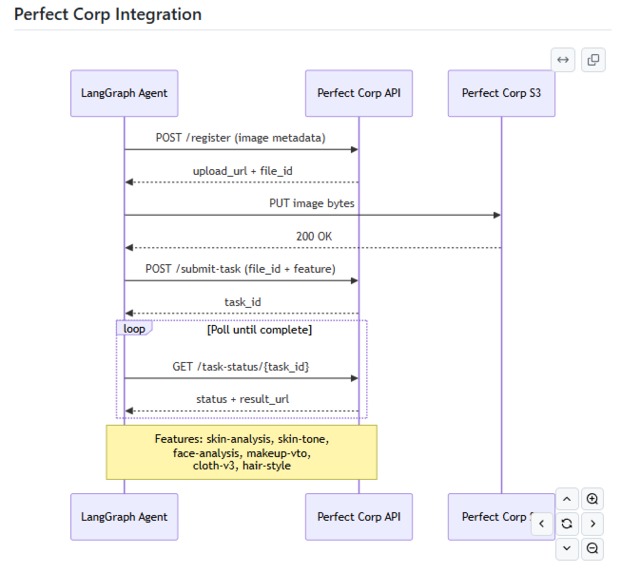
Perf Corp Integration
-
Upload Panel
Inspiration
The beauty industry is overwhelmingly visual — yet most AI assistants are text-only. We noticed a gap: people want to see how a product looks on them before committing. Existing virtual try-on tools are siloed (one app for makeup, another for hair, another for outfits) and lack conversational context.
We asked: what if a single AI stylist could understand your skin, recommend products, and show you the result — all in one natural conversation?
That's Mira — an AI beauty consultant that merges computer vision with conversational AI to make personalized styling accessible to everyone.
Demo Videos
What it does
Mira is an end-to-end AI beauty consultation experience:
- Upload a selfie → Mira analyzes your skin type, tone, undertone, and concerns (acne, wrinkles, dark circles, etc.)
- Chat naturally → Ask for wedding makeup, a fresh haircut, or everyday outfit ideas
- Virtual try-on → See makeup, hairstyles, and clothing rendered on your photo in real time
- Look Card → Save favorites and download a styled PDF with product links
stateDiagram-v2
[*] --> PhotoUpload: User uploads selfie
PhotoUpload --> AgentStart: Auto-triggers conversation
AgentStart --> BeautyAnalysis: analyze_beauty_profile()
BeautyAnalysis --> Recommendation: Agent recommends looks
Recommendation --> TryOn: User requests try-on
state TryOn {
[*] --> Makeup: try_on_makeup()
[*] --> Clothing: try_on_clothes()
[*] --> Hairstyle: try_on_hairstyle()
}
TryOn --> SaveToLookCard: User approves
TryOn --> Recommendation: Try another
SaveToLookCard --> Recommendation: Continue exploring
SaveToLookCard --> DownloadPDF: User downloads Look Card
DownloadPDF --> [*]
How we built it
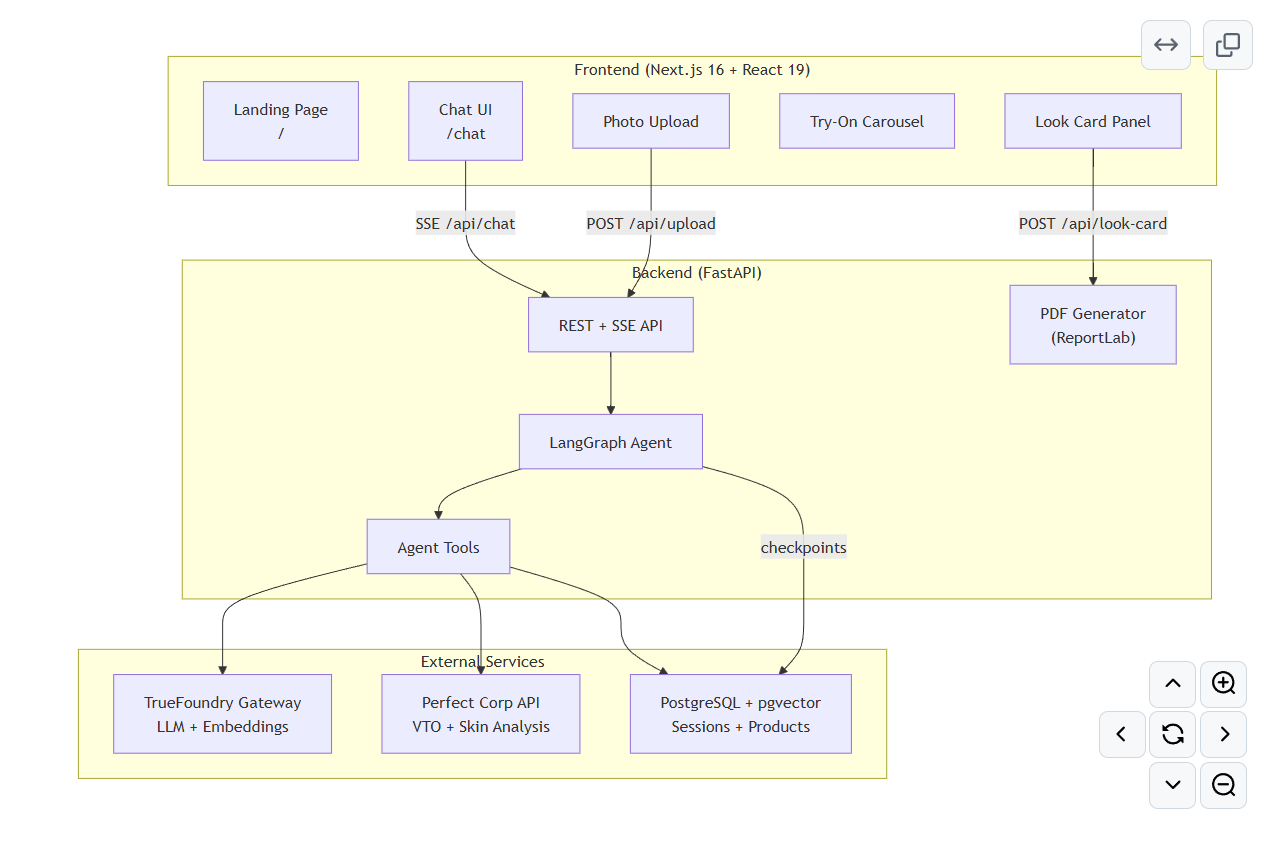
Architecture
flowchart TB
subgraph Client["Frontend (Next.js 16 + React 19)"]
Landing["Landing Page<br/>/"]
Chat["Chat UI<br/>/chat"]
Upload["Photo Upload"]
Carousel["Try-On Carousel"]
LookCard["Look Card Panel"]
end
subgraph Server["Backend (FastAPI)"]
API["REST + SSE API"]
Agent["LangGraph Agent"]
Tools["Agent Tools"]
PDFGen["PDF Generator<br/>(ReportLab)"]
end
subgraph External["External Services"]
TF["TrueFoundry Gateway<br/>LLM + Embeddings"]
PC["Perfect Corp API<br/>VTO + Skin Analysis"]
PG["PostgreSQL + pgvector<br/>Sessions + Products"]
end
Chat -->|SSE /api/chat| API
Upload -->|POST /api/upload| API
LookCard -->|POST /api/look-card| PDFGen
API --> Agent
Agent --> Tools
Tools --> TF
Tools --> PC
Tools --> PG
Agent -->|checkpoints| PG
Key technical decisions
| Layer | Choice | Why |
|---|---|---|
| Agent framework | LangGraph | Stateful graph with tool-calling loops, checkpoint persistence, conditional edges |
| LLM routing | TrueFoundry Gateway | Single API, multi-model fallback (DeepSeek V4 Pro → Kimi-K2.6 → Mistral Large 3 → Gemini Flash) |
| Virtual try-on | Perfect Corp S2S API | Production-grade makeup, clothing, and hairstyle rendering |
| Product search | pgvector + TrueFoundry embeddings | Semantic similarity over ~240 beauty products |
| Streaming | SSE (Server-Sent Events) | Token-by-token streaming for responsive chat UX |
| Frontend | Next.js 16 + React 19 | App Router, server components, fast Vercel deploys |
Multi-model fallback
We built resilience into the LLM layer — if the primary model (DeepSeek V4 Pro) times out or errors, the agent automatically falls through:
flowchart LR
subgraph TF["TrueFoundry AI Gateway"]
direction TB
Primary["DeepSeek V4 Pro<br/>(nebius-endpoint)"]
Fallback1["Kimi K2.6<br/>(nebius-endpoint)"]
Fallback2["Mistral Large 3<br/>(nvidia-endpoint)"]
Fallback3["Gemini 3.1 Flash Lite<br/>(google-gemini)"]
end
Agent["LangGraph Agent"] -->|Chat Completion| Primary
Primary -.->|timeout/error| Fallback1
Fallback1 -.->|timeout/error| Fallback2
Fallback2 -.->|timeout/error| Fallback3
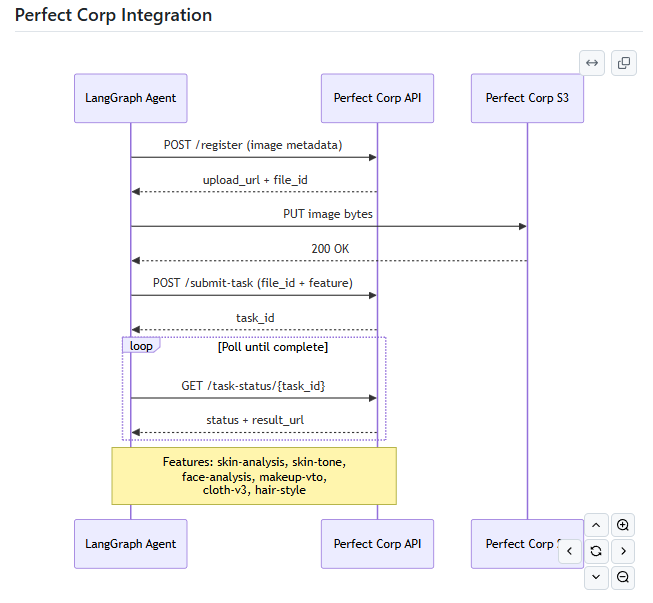
Perfect Corp integration
sequenceDiagram
participant Agent as LangGraph Agent
participant PC as Perfect Corp API
participant S3 as Perfect Corp S3
Agent->>PC: POST /register (image metadata)
PC-->>Agent: upload_url + file_id
Agent->>S3: PUT image bytes
S3-->>Agent: 200 OK
Agent->>PC: POST /submit-task (file_id + feature)
PC-->>Agent: task_id
loop Poll until complete
Agent->>PC: GET /task-status/{task_id}
PC-->>Agent: status + result_url
end
Note over Agent,PC: Features: skin-analysis, skin-tone,<br/>face-analysis, makeup-vto,<br/>cloth-v3, hair-style
Challenges we ran into
Perfect Corp's async task model — VTO jobs are asynchronous (register → upload → submit → poll). We had to implement robust polling with exponential backoff and timeout handling inside LangGraph tool nodes, while keeping the SSE stream alive for the user.
LLM reliability under hackathon conditions — No single model was 100% available. We built a 4-model priority fallback chain with per-model timeouts ($T_{total} = 120s$ per attempt). The agent gracefully degrades without the user noticing.
State management across tool calls — The agent's
state_updaternode must parse heterogeneous tool outputs (skin analysis JSON, try-on image URLs, product metadata) and merge them into typed state fields without duplicates. Getting the normalization right for nested skin analysis responses was tricky.Streaming + tool calls — SSE streaming needs to interleave assistant text tokens with structured tool-call results (images, cards). We built a custom SSE protocol that the frontend parses into text bubbles, image carousels, and look-card items.
Product catalog embedding — Seeding 240+ products with 1536-dim embeddings via TrueFoundry's embedding endpoint, then querying with pgvector cosine similarity, required careful batching to stay within rate limits.
Accomplishments that we're proud of
- End-to-end flow works: selfie → analysis → recommendation → try-on → look card PDF, all in one conversational session
- Multi-modal output: the agent naturally mixes text advice with rendered try-on images
- Zero-downtime LLM switching: the fallback chain means the app never shows a hard error to the user
- Production-quality VTO: leveraging Perfect Corp means results look realistic, not cartoonish
- Persistent sessions: PostgreSQL checkpointing means users can close the tab and resume their session later
- Beautiful UI: the landing page with before/after compare sliders immediately demonstrates value
What we learned
- LangGraph's power is in the edges: conditional routing (
should_continue) and intermediate processing nodes (state_updater) let you build complex agent loops that stay debuggable - API gateway abstraction pays off fast: TrueFoundry's unified gateway meant swapping models was a one-line env var change, not a code rewrite
- Async polling patterns in Python:
asyncio.wait_for+ structured retry logic is essential when integrating with any external task-based API - pgvector is surprisingly easy: semantic search over a product catalog took ~50 lines of code including embedding generation
- SSE > WebSockets for this use case: simpler client code, automatic reconnection, and works through CDNs without config
What's next for Mira — AI Beauty Consultant
- Real-time camera feed — skip the upload step; apply try-ons live via WebRTC
- Multi-person mode — style groups (e.g., bridal party coordination)
- Purchase integration — affiliate links in the Look Card become one-click buy buttons
- Expanded catalog — partner with brands for real-time inventory + pricing
- Fine-tuned style model — train on user preferences over time for increasingly personalized recommendations
- Mobile app — React Native wrapper with camera-first UX
Built With
- deepseek
- fastapi
- javascript
- langchain
- langgraph
- mistral
- nebius
- next.js
- perfect-corp
- pgvector
- postgresql
- python
- railway
- react
- reportlab
- sse
- tailwind-css
- truefoundry
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.