-

UI Sample
-
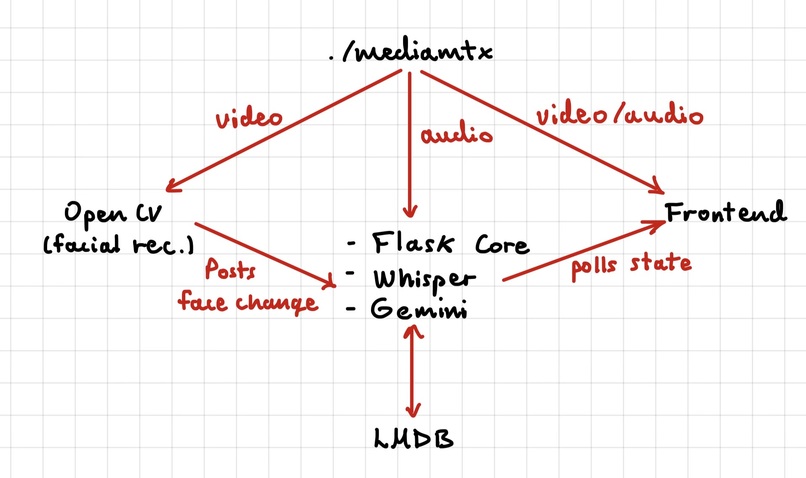
Systems interoperability flowchart

Inspiration:
While this device can be used by anyone, our core motivation comes from a real desire to support people living with severe memory loss or Alzheimer’s. For many, recognizing a familiar face can be challenging, and recalling the context of a relationship along with past conversations can be even harder. This inspired us to create a simple, approachable tool that helps bridge that gap.
By offering context about the person the wearer is speaking to, Mira makes it easier to stay connected, remember meaningful details, and maintain relationships that matter. Our focus is on helping users preserve those bonds and stay close to the people who bring comfort and familiarity to their lives.
What It Does:
Mira is an ambient, intelligent AI assistant built into an AR display, designed to support real conversations, strengthen personal connections, and reinforce the relationships that matter most.
Flow:
Face Recognition (The AR Trigger): Our face-recognition worker processes the RTSP video stream from MediaMTX, notifies Flask when it detects or recognizes someone, and the frontend uses the updated state to show the appropriate liquid-glass context in real time.
Ambient Audio Recording: The system only begins capturing the buffering audio (from the RTSP stream) when that specific person is present.
Audio Trigger: When the person leaves the frame, the system automatically ends the recording.
Transcription: The captured audio segment is sent to the Lemonfox API for high-accuracy, diarized transcription.
Stateful Analysis: The new transcript is stored in a database. Then, the entire conversation history for that person is sent to the Google Gemini API.
Intelligent Memory Generation: Gemini analyzes this complete history and generates a structured JSON object containing the person's key info, a "Current State" summary, "Last Points" discussed, and "Suggested Talking Points."
Simulated AR Display: Our liquid glass UI polls the backend. When a recognized loved one appears, the glass card animates open, simulating the AR HUD. It displays their name, relationship, a summary of their life, and gentle prompts for what to ask next.
How We Built It:
Backend: Flask serves as the central API server, managing state and coordinating all services.
Computer Vision: OpenCV and a pre-trained Caffe model (facetracker.py) simulate the AR camera's real-time face recognition.
Audio Pipeline: MediaMTX (RTSP server) provides the A/V feed. PyAV (audiotap.py) connects to this stream, buffers the live audio, and saves it as an MP3.
Database: LMDB (db.py) is used as a persistent key-value store to save transcripts and Gemini analysis results.
Transcription: The Whisper API (lemonfox.py) is used for its fast and accurate speaker-diarized transcription.
AI Analysis: The Google Gemini API (gemini.py) is used for its advanced reasoning and stateful analysis. We use JSON mode to ensure a reliable data structure.
Frontend (AR Prototype): A HTML/CSS/JS structure (index.html, styles.css, main.js) creates the beautiful glass UI that acts as a stand-in for the final AR heads-up display.
Challenges We Ran Into:
Jeremi: The biggest challenges I ran into were in the realm of real-time encoding, stream stability, and system interoperability. Because Mira relies on a continuous low-latency A/V stream, any delay or mismatch in the pipeline consisting of MediaMTX, PyAV, OpenCV, and Flask would ripple downstream. I had to tune encoder settings, buffer sizes, and even frame-skip logic just to keep the facial-recognition loop responsive enough for an AR use case. We also had a lot of issues with reliably remembering faces with OpenCV. One of the strangest and hardest to diagnose issues I ran into was when my computer crashed and shut down mid-stream, which somehow corrupted macOS’s loopback virtual interface (very rare). After that, the 127.0.0.1 (localhost) route stopped resolving entirely, and didn't come back even after shutting down and restarting my laptop a few times.
Dominic: We struggled to get the required speaker-separated (diarized) transcript from the Lemonfox API, as our initial requests only returned a single, unusable block of text. We finally solved this after extensive trial and error by discovering the correct, non-obvious combination of form-data parameters, more specifically the verbose exported json format, and enabling the speaker labels flag.
Jeremy: The biggest challenge for me was getting all of the moving pieces in our architecture to behave like one coherent system and agree on a strict JSON format. We had MediaMTX streaming audio/video, a Python face-recognition worker posting events, a separate audio tap capturing buffered sound, Flask orchestrating calls to Whisper and Gemini, LMDB storing state, and a JavaScript frontend polling for updates. If even one service wrote slightly different JSON, the whole chain would break. We were constantly running into bugs where IDs didn’t line up or Gemini would occasionally drift from the expected JSON schema. But we ended up figuring it out.
Accomplishments That We're Proud Of:
We’re proud that we were able to design and implement a complete end-to-end AI pipeline that operates entirely on its own once activated. Every stage of the system triggers the next: face recognition starts audio capture, leaving the frame ends it, Whisper generates a diarized transcript, Gemini performs stateful analysis, the results are stored, and the UI updates in real time. We also successfully integrated five different technologies (MediaMTX, OpenCV, Flask, Whisper, and Gemini) into a single coordinated architecture with consistent state, stable JSON, and synchronized event timing. And despite working under strict timing constraints, we managed to create a smooth, visually polished AR-style interface that convincingly demonstrates how the real glasses will function, look, and feel.
What We Learned:
As first-time hackathon participants, we learned how to move fast, divide responsibilities, and keep a complex system working under intense time pressure. We gained hands-on experience integrating multiple APIs, handling messy real-world data, and designing a clean JSON structure that every service could rely on. Most importantly, we learned how to collaborate, iterate, and reconcile merge conflicts quickly, allowing us to turn an ambitious idea into a working prototype.
What’s Next For Mira:
Our next step is to bring Mira is to make its modules more reliable so they work well in a real world non-ideal setting, and bring it from a simulated AR experience into a fully integrated wearable device. This includes building custom hardware for the glasses themselves, incorporating a lightweight onboard processor, and replacing the simulated liquid-glass UI with a true transparent AR display. We also plan to expand Mira’s capabilities with features such as on-glasses wake-word activation, multi-person recognition, emotion-aware cues, and real-time translation to support a wider range of communication needs. Beyond Alzheimer’s care, Mira can naturally extend into other markets, such as social cue assistance for neurodivergent users or caregiver tools that surface medical or safety information at a glance.








Log in or sign up for Devpost to join the conversation.