MioSub — The AI Subtitle Editor That Actually Understands Context
Inspiration
Every AI subtitle tool today translates line by line — a character name in line 1 becomes a different translation in line 50. These aren't translation errors; they're context errors. We asked: what if Gemini understood the whole video first, then translated like a human would?
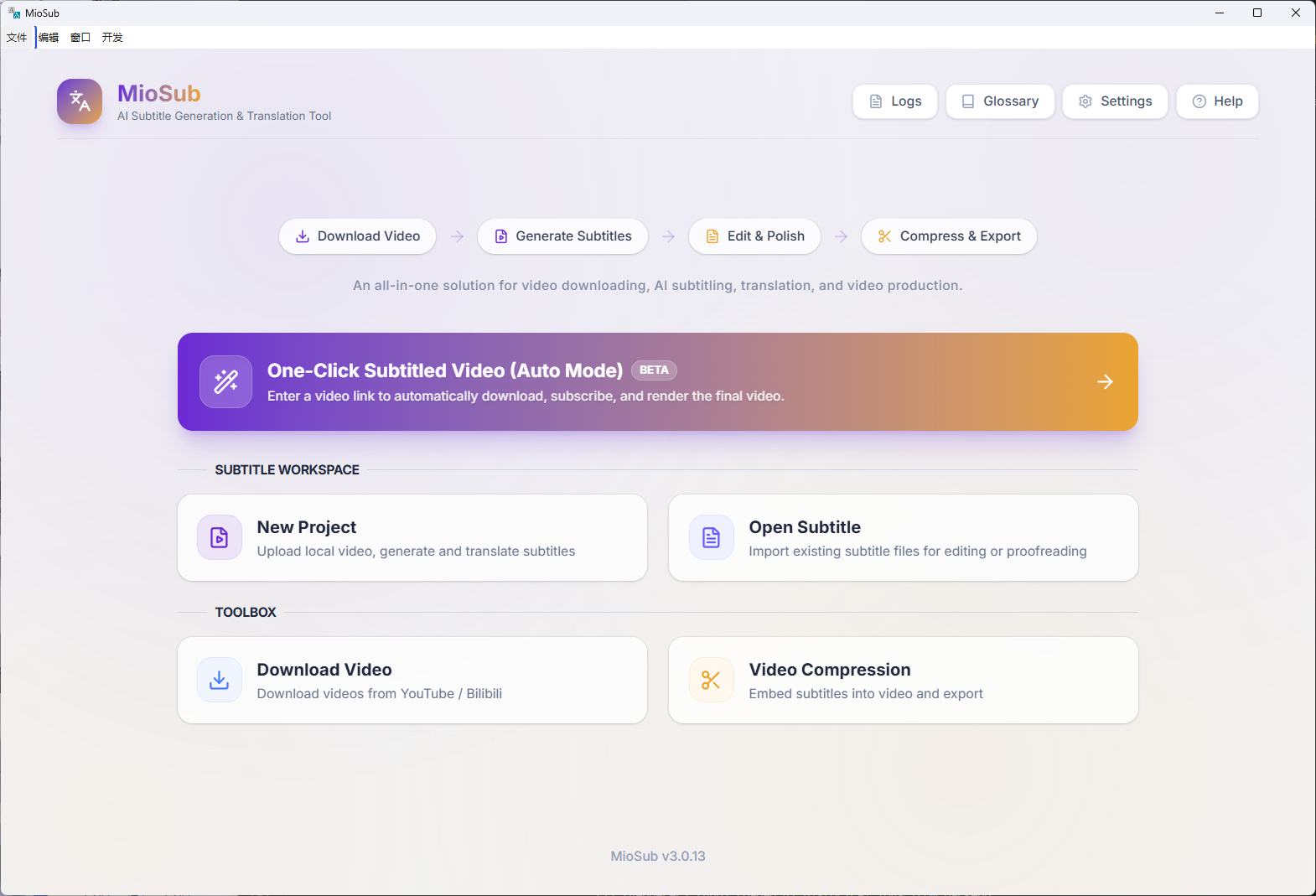
What it does
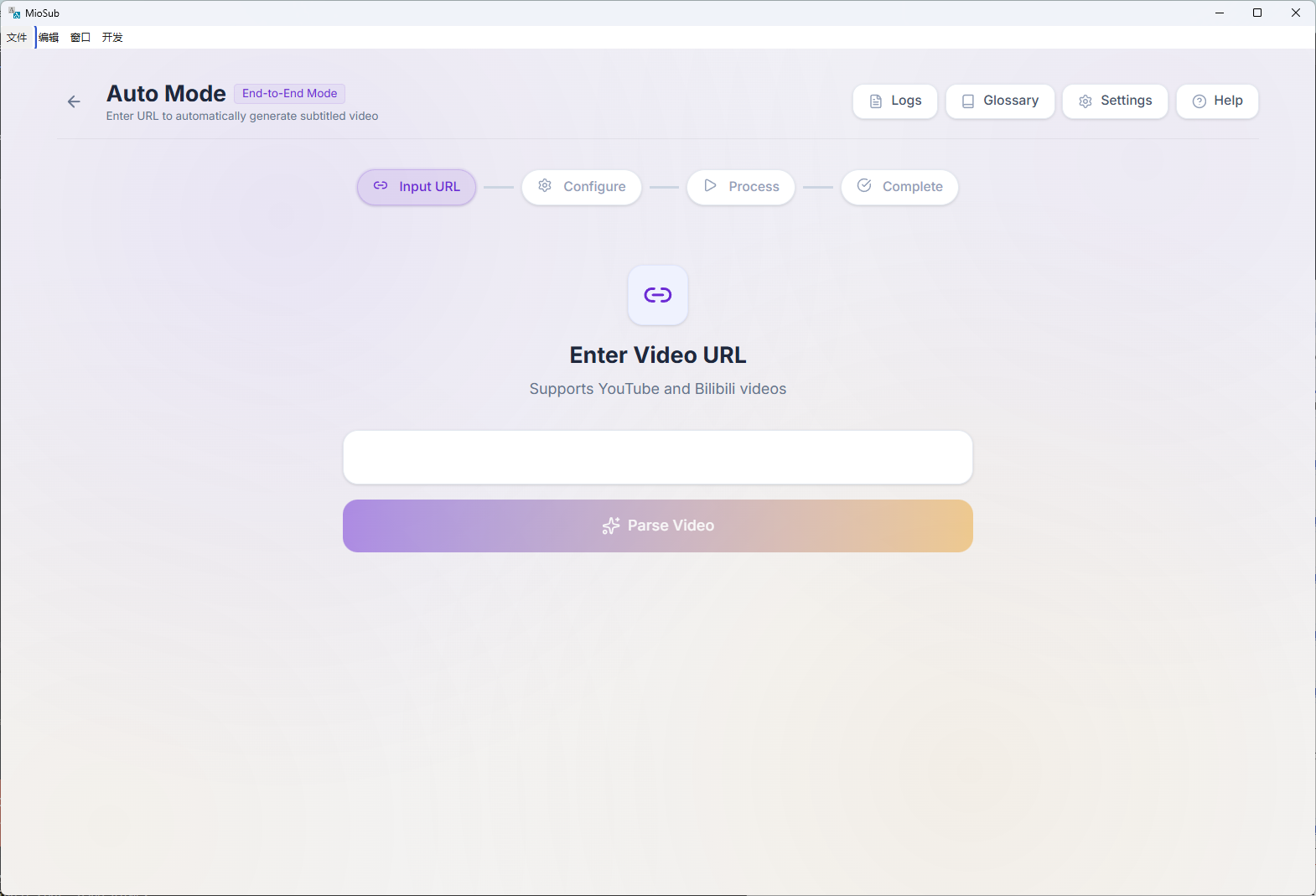
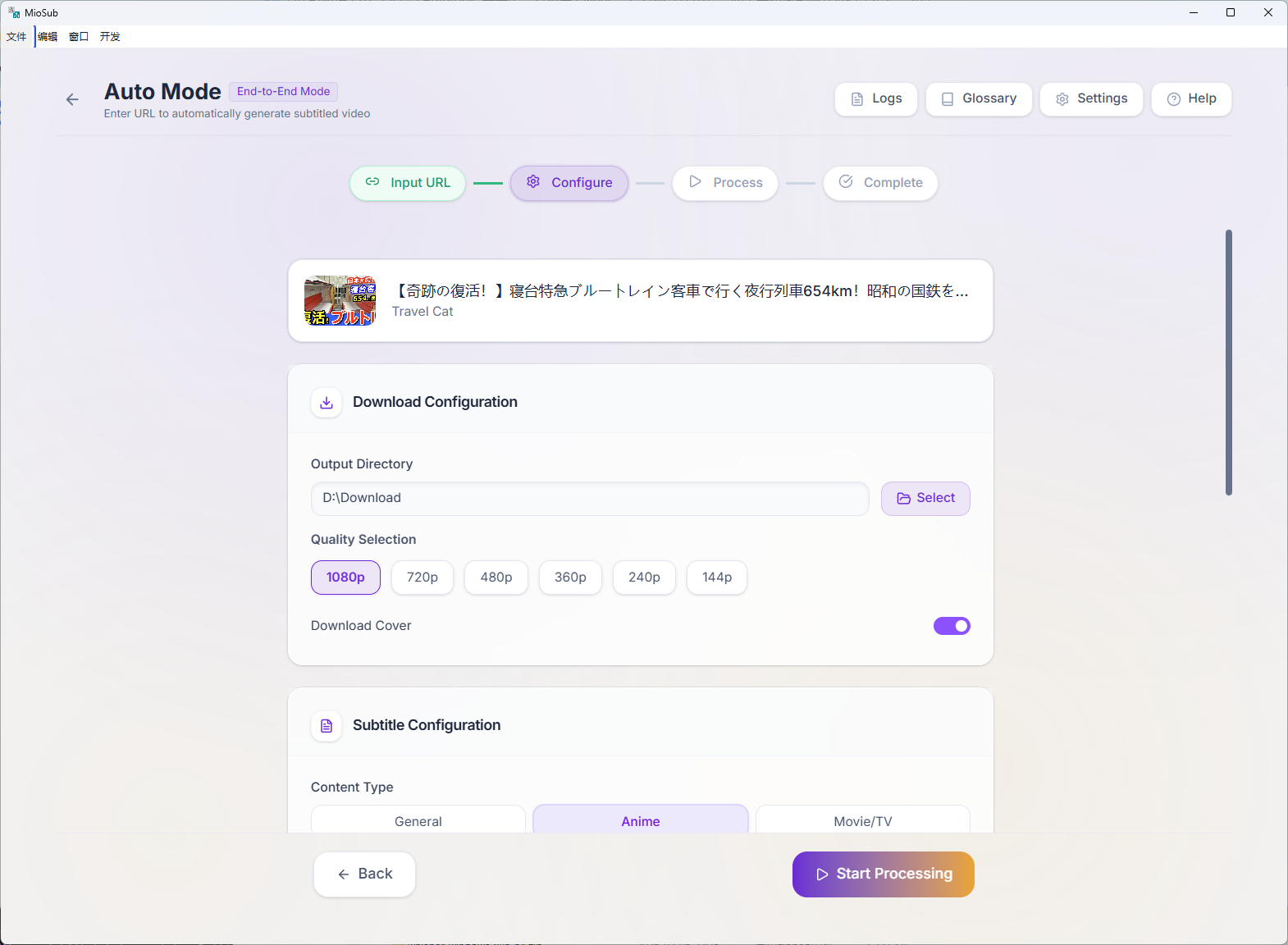
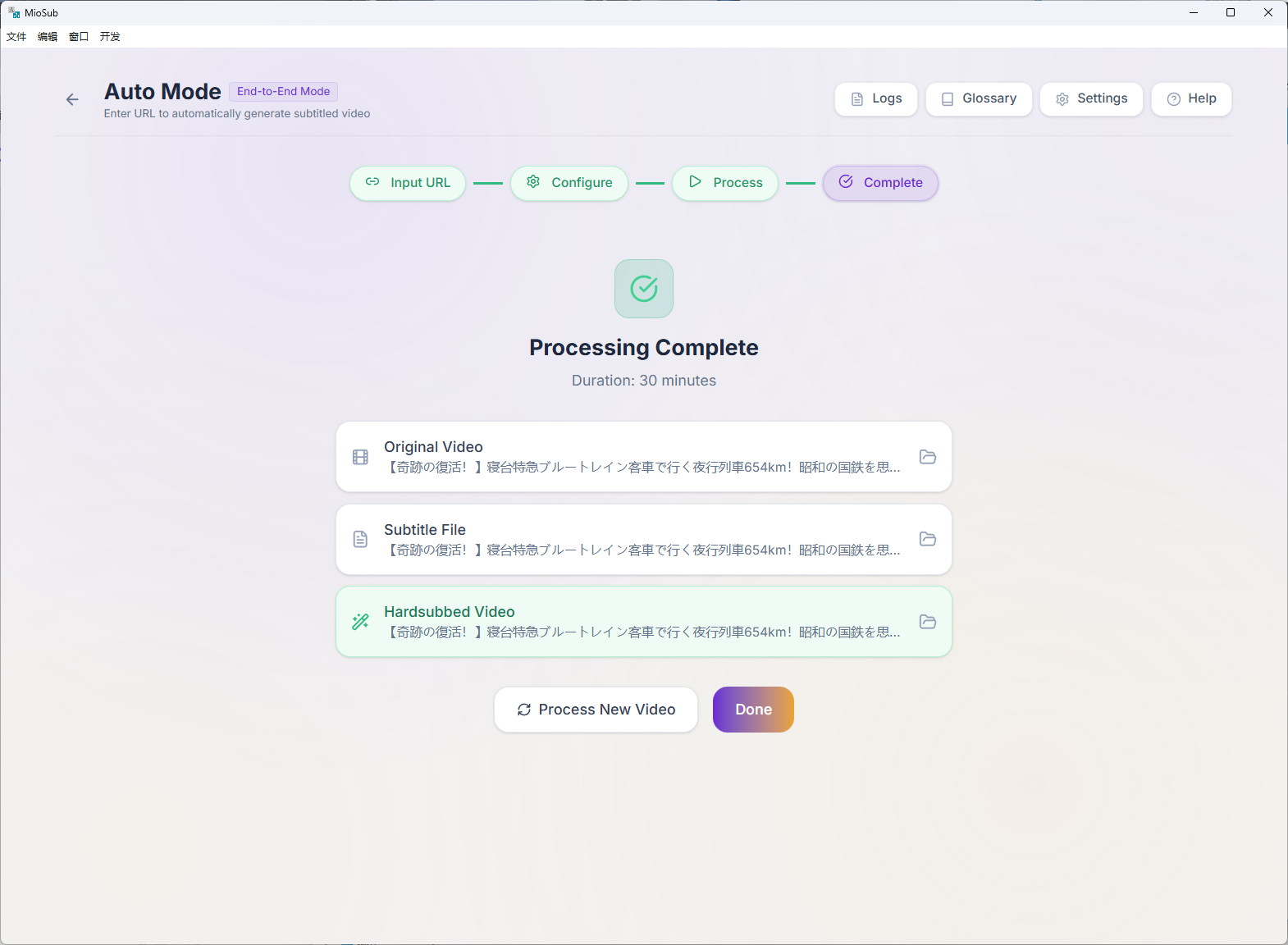
MioSub is an end-to-end AI subtitle engine. Paste a video link → get production-ready bilingual subtitles. 30-min video in under 10 minutes, fully automated.
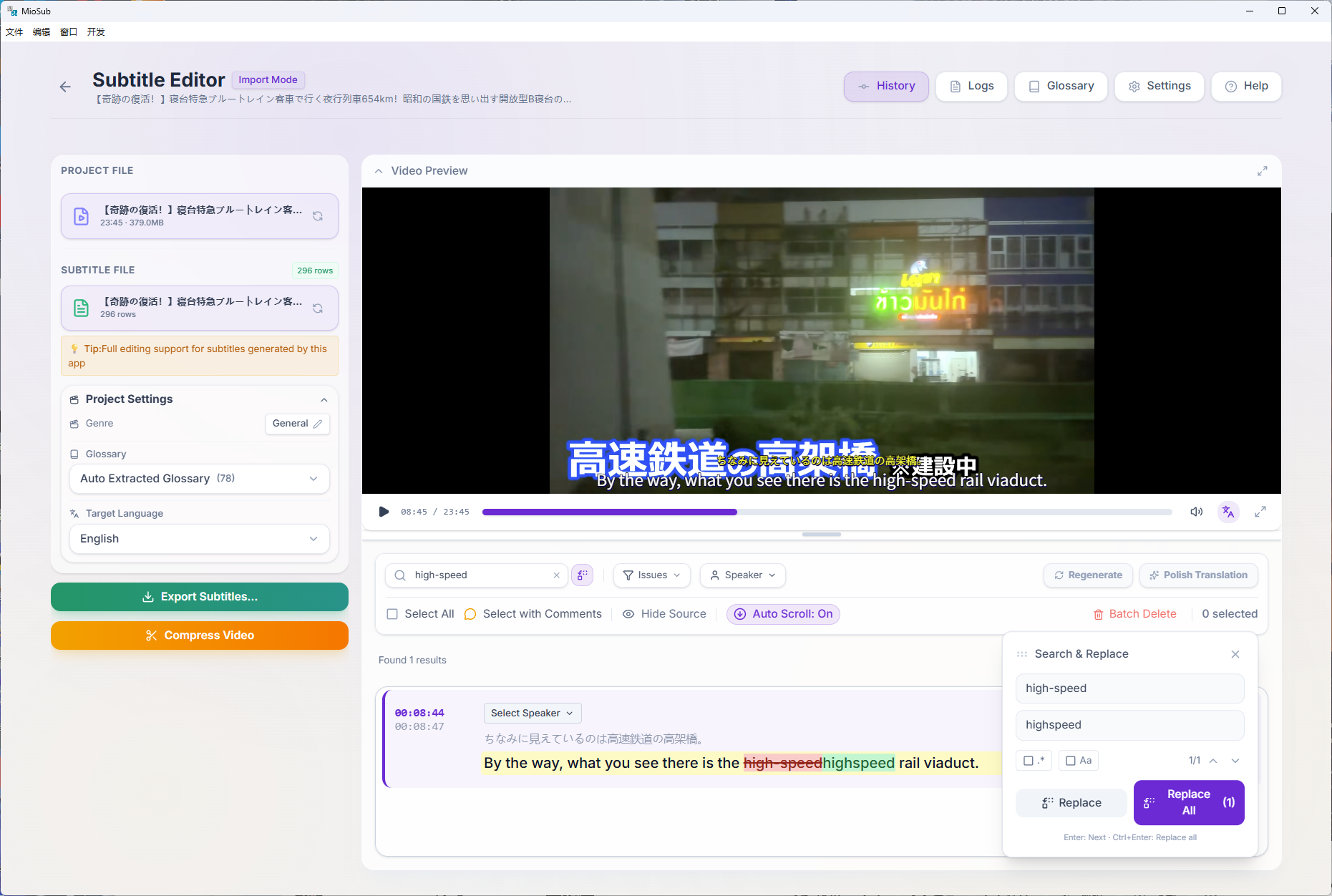
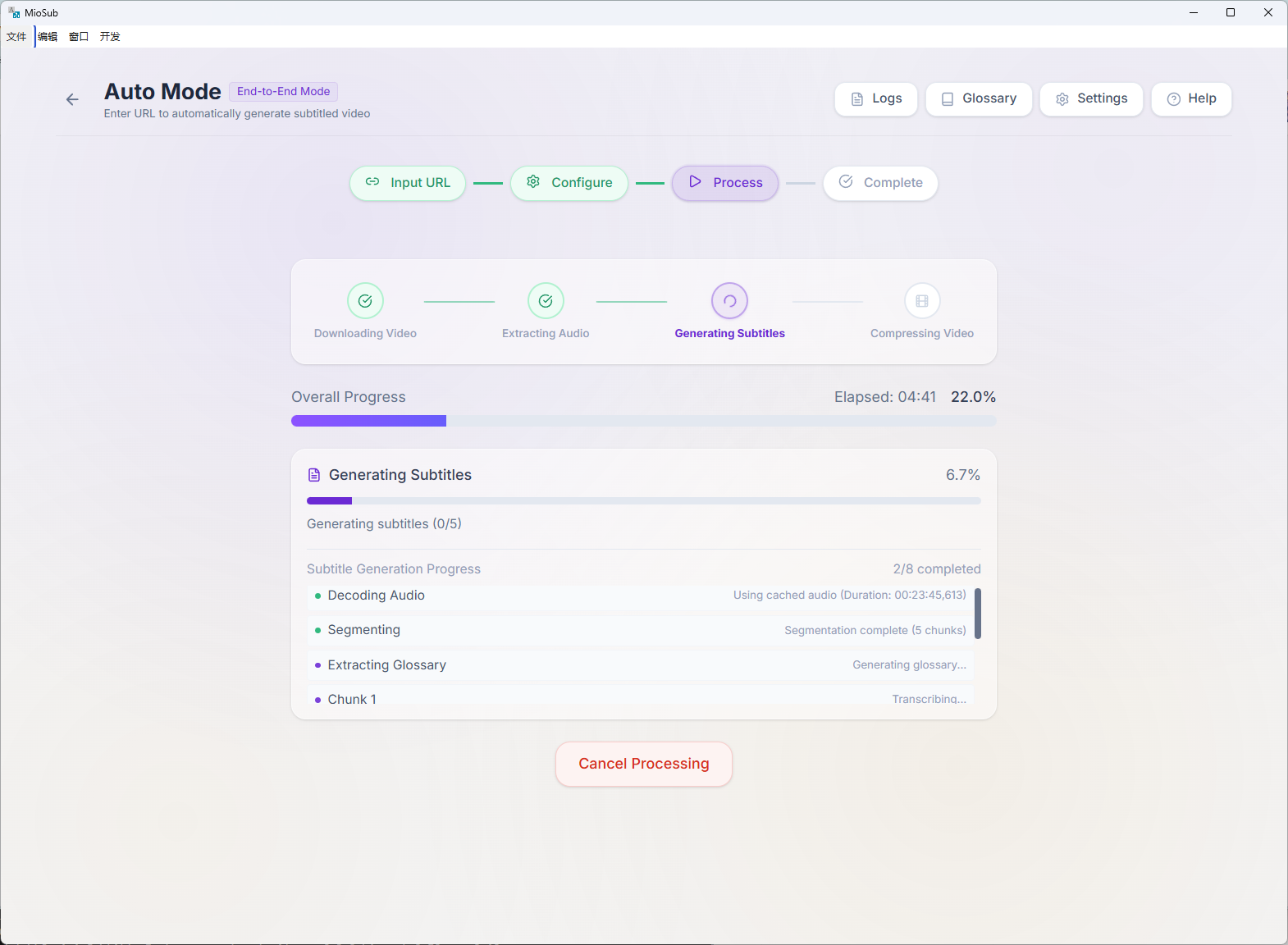
The pipeline: Gemini 3 Pro pre-scans audio to extract a glossary and speaker profiles, then each chunk flows through Whisper transcription → Gemini refinement (with raw audio) → CTC millisecond alignment → Gemini translation (with Search Grounding) → Gemini proofreading. The glossary locks in consistent terminology across the entire video.
How we built it
Dual-platform app (Web + Electron Desktop) with React 19, TypeScript, and Vite 6. The pipeline leverages five Gemini 3 capabilities working together:
- Audio Understanding — Gemini 3 Pro processes raw audio directly to extract glossary terms and speaker profiles. By hearing pronunciation and tone, it catches proper nouns that text-based approaches miss.
- Thinking / Reasoning — Glossary and speaker extraction use
thinkingLevel: 'high', letting Gemini reason through ambiguous audio and domain jargon before committing output. - Structured Output — Every Gemini call enforces strict JSON schemas, eliminating parsing failures across ~200 API calls per video.
- Search Grounding — During translation, Gemini queries Google Search to verify proper noun translations not in the glossary, preventing hallucinations.
- Multi-model orchestration — Gemini 3 Pro handles high-stakes tasks (glossary, speakers, proofreading); Gemini 3 Flash handles high-throughput tasks (refinement, translation) at 5× concurrency.
The core innovation is a glossary-first architecture: extract terminology globally, then enforce it locally — so every chunk translates with full context.
Challenges we ran into
The hardest problem was glossary bootstrapping — the glossary must come from the same audio being translated. We solved it with a two-phase async architecture: global extraction runs in parallel with transcription, and a dependency gate ensures no chunk translates without the glossary. Achieving timestamp precision required a three-system hybrid: Whisper for initial timing, Gemini for text refinement, and a CTC forced aligner for millisecond re-sync.
Accomplishments that we're proud of
Real users produce real content today — 30-min Japanese radio shows with speaker labels, railway vlogs with technical terminology, anime commentary with dozens of proper nouns — all in one pass, zero manual correction. Open source, cross-platform, with a live web demo.
What we learned
Context beats speed. The glossary-first design was our most impactful decision. Gemini's audio understanding is massively underutilized — feeding raw audio instead of text produces dramatically better extraction. And structured output + search grounding together make Gemini a reliable production component, not just a demo toy.
What's next for MioSub
Gemini native video understanding for scene-aware translation, real-time streaming subtitles, community glossary sharing, and AI-powered quality scoring for human-in-the-loop workflows.

Log in or sign up for Devpost to join the conversation.