-
-
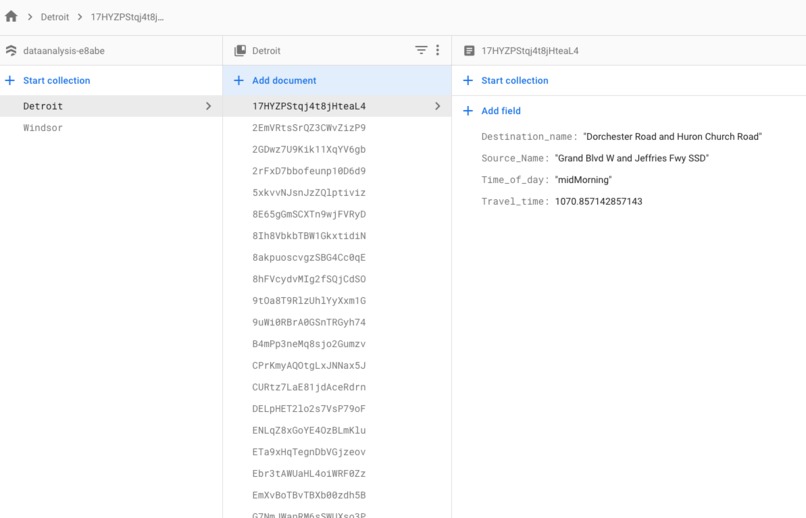
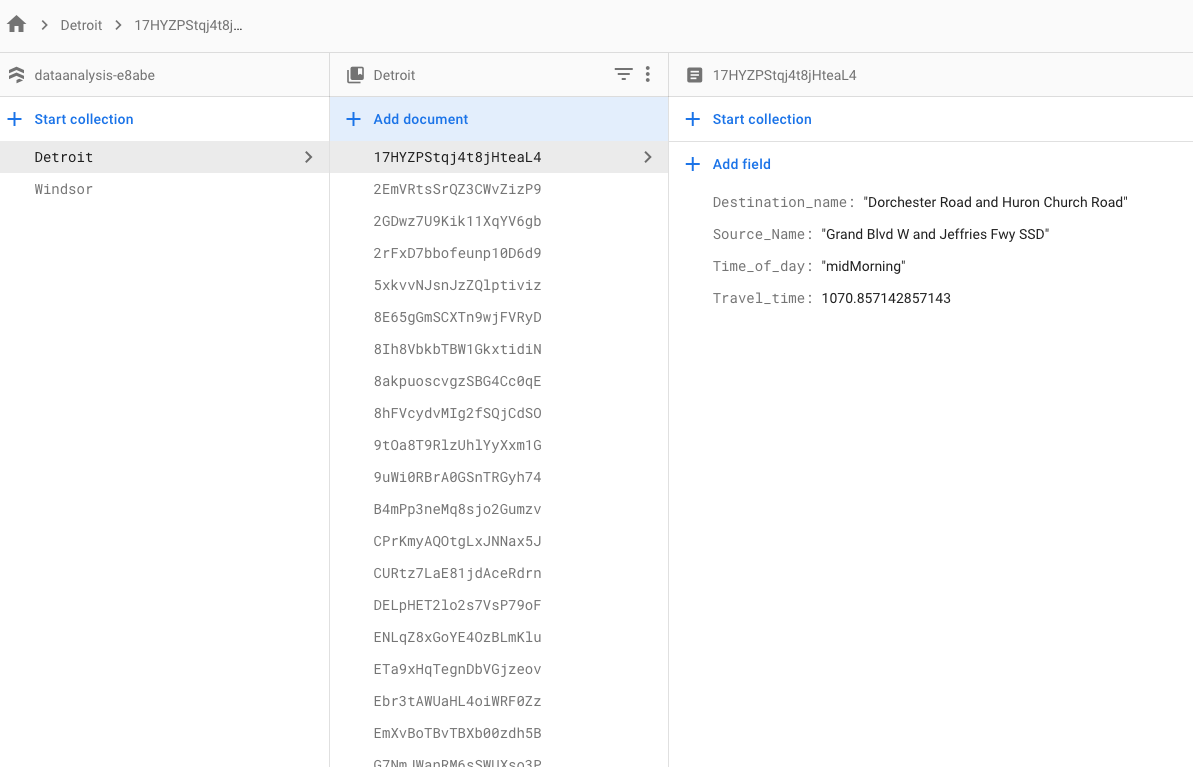
From Detroit Travel Time Averages (Firestore Collection)
-
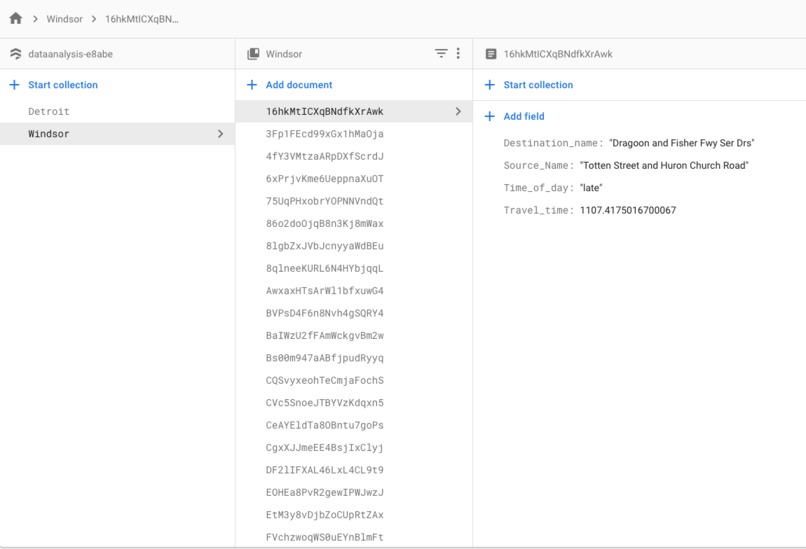
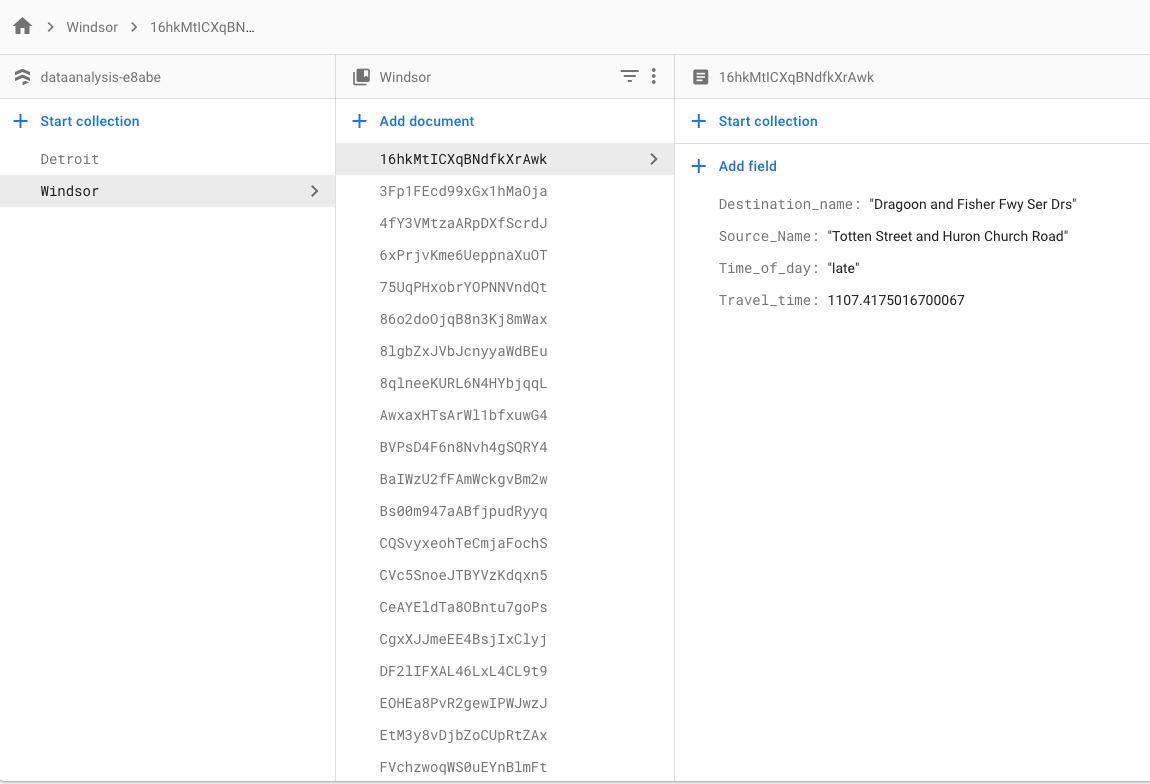
From Windsor Travel Time Averages (Firestore Collection)
-
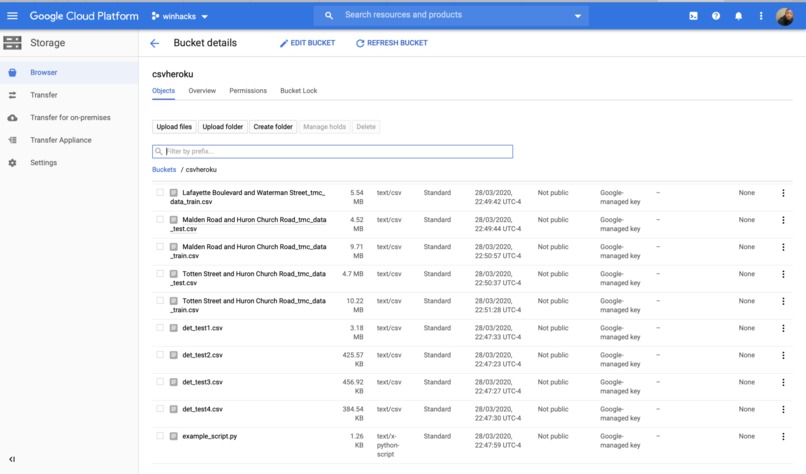
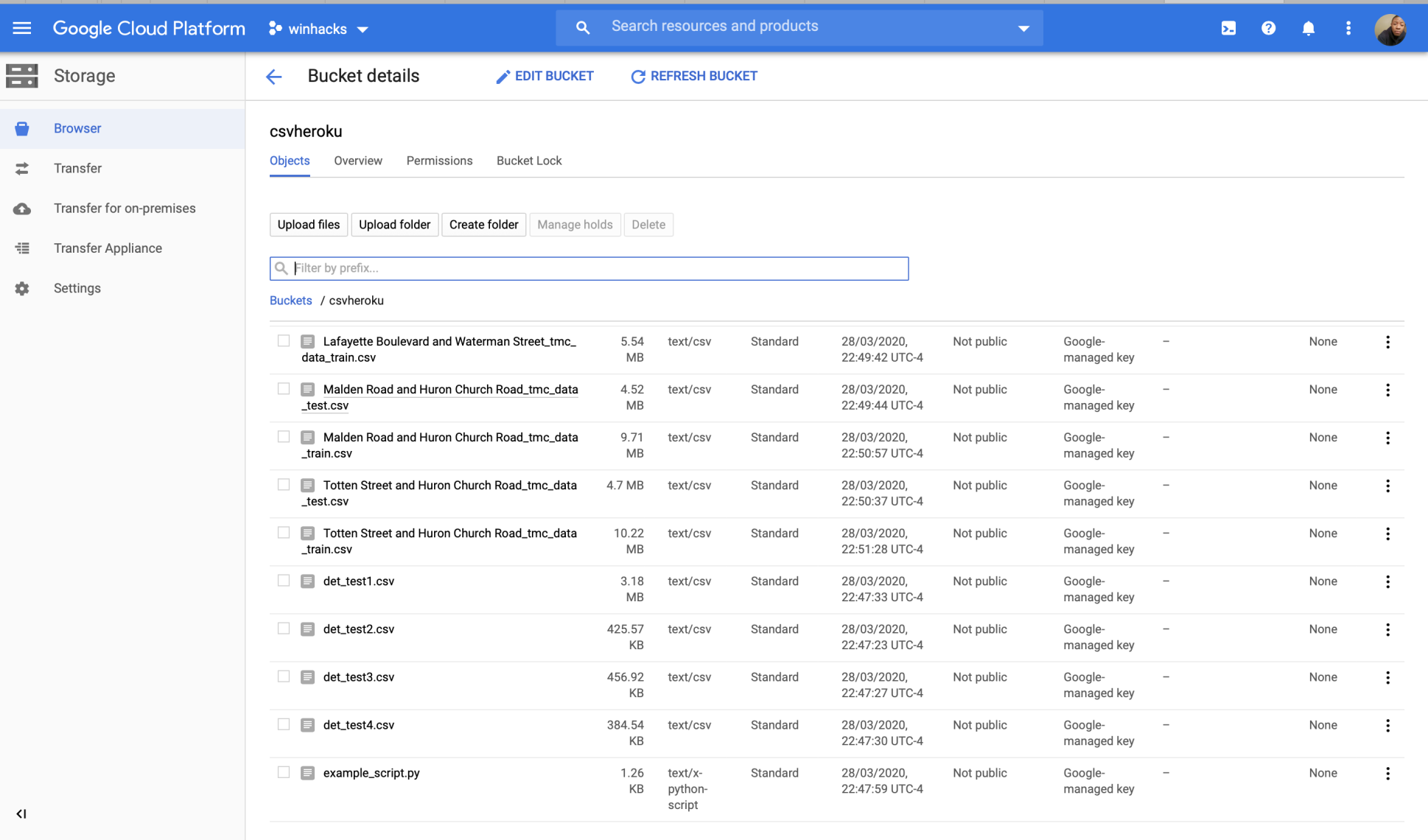
GCP Storage
-
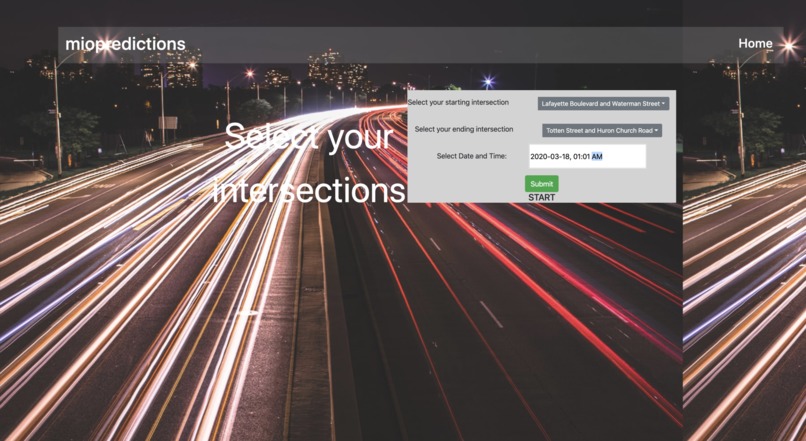
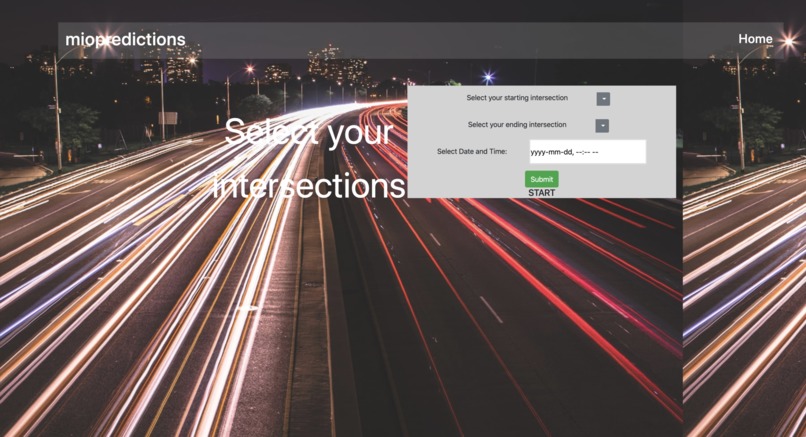
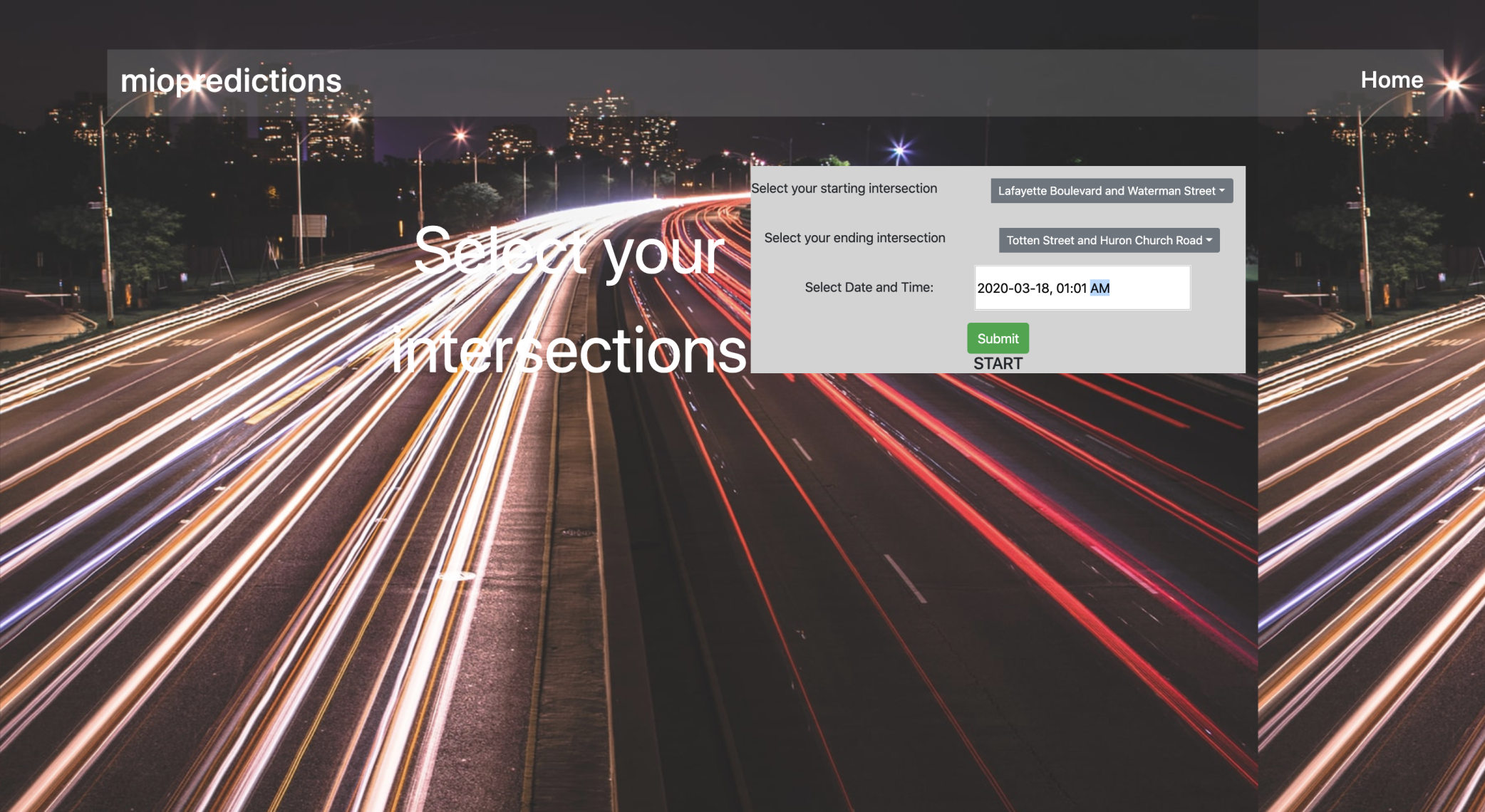
Select start + end intersection + specific date/time
-
-

Results page (from Detroit example)
-

Home page / first prompt
-
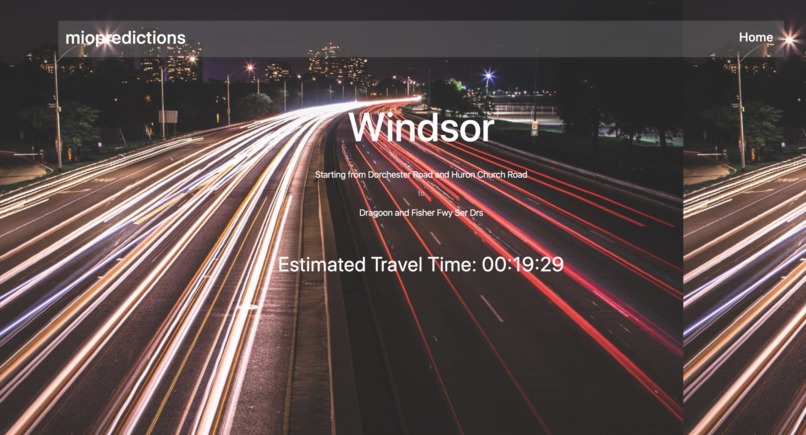
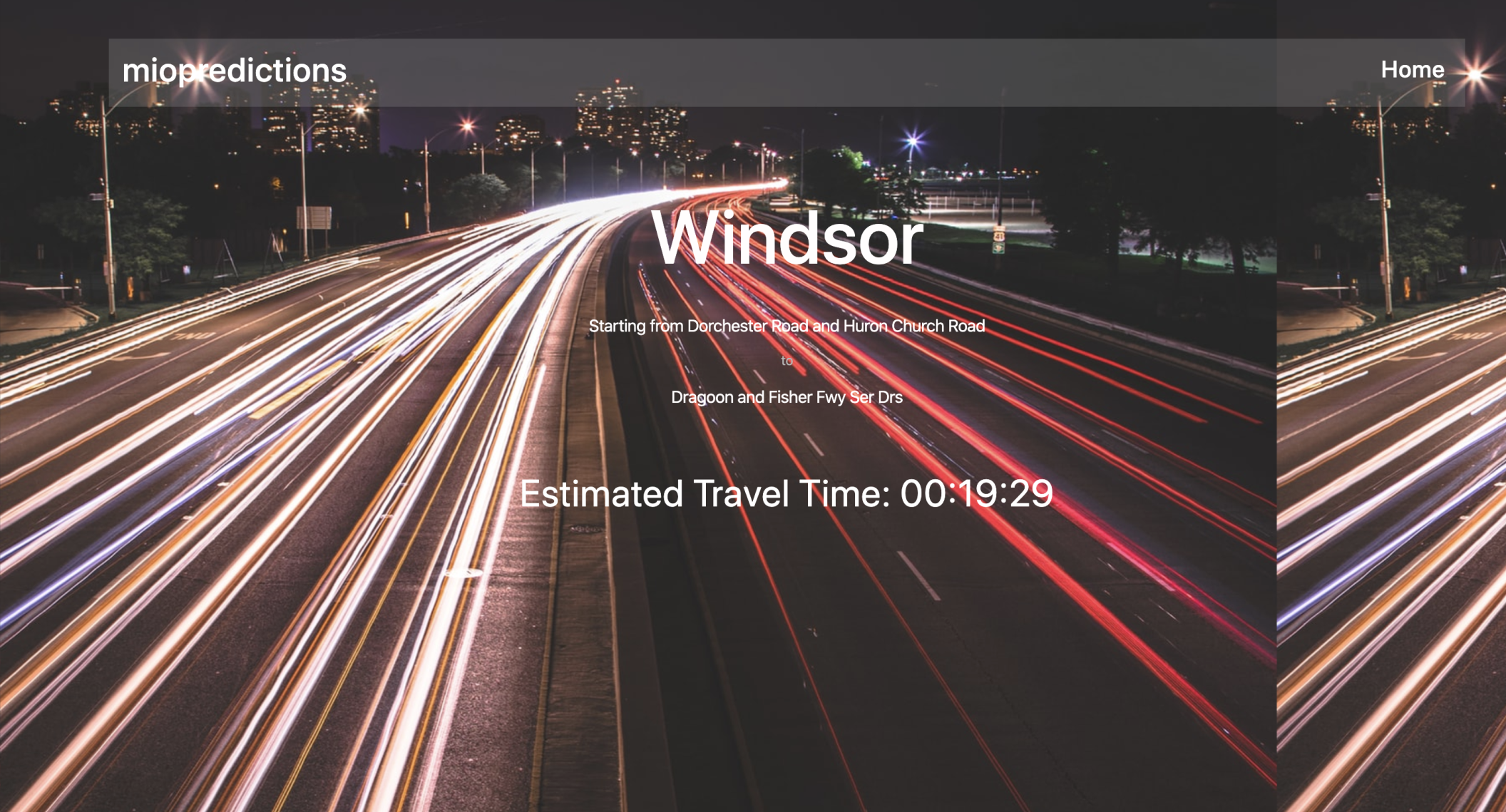
Results page (from Windsor example)


Inspiration
Data drives the world. In learning more about Miovision, we were inspired by their mantra of open innovation and how they were using data to make life better for all -- from the individual citizen, to the community business, to the local government. At the same time, we recognize that data is often messy, hard to interpret, and difficult to get meaningful insights from. We wanted to think of ways that we could use good data, draw powerful insights, and use those to make cross-border travel a bit more predictable.
What it does
We built a web application that utilizes historical Miovision, cross-country Travel Time data to estimate the time it takes to get from key intersections in one city, to key intersections in another. The application first asks you to select your starting city of choice (in this case, either "Detroit" or "Windsor"). From there, the application gives you the freedom to specify your starting intersection, your end destination intersection, and the time at which you plan to make the trip. It then takes all of the inputs to calculate the most likely time in (HH:MM:SS) it will take to get from where you are, to where you want to go, at that point in time.
What is special about our platform is its flexibility, scalability, and quality, given integration with Miovision data. This is not simply a Detroit-Windsor-specific prediction app. Given Miovision Travel Time data between any two cities, our current application will compute an accurate estimated travel time value, factoring in date and time, between intersections of any two cities. Moreover, its use of APIs and Firestore for data storage and access ensures data security, access efficiency, and adaptability to varying dataset sizes. Imagining this at scale, we see the integration of more Miovision Travel Time data into our prediction feature as having many use cases in B2B or B2G spaces -- from manufacturing companies considering when to ship new products to farmers thinking about when to send out new produce to other companies trying to optimize supply chain operations for the future.
How we built it
//Data processing First we parsed through the Travel Time.csv file and converted it to JSON format. We then created an API using Heroku to store the large dataset, creating multiple endpoints (see links on "Try it out!") to increase the efficiency of the program that would then process this parsed data.
Our travelTimeLoader.java file processes each endpoint. Each endpoint contains all of the travel time data for one intersection as the "source" (ex: all of the data from all possible routes with that specific intersection as the start point). For each possible route, the program calculates multiple average travel time values representing the program's "prediction", based upon specific times-of-day across the given days in the dataset. The program then loads this aggregate information into Firestore based upon the city of origin (one Collection with routes beginning in one city, one Collection with routes beginning in the other).
//App Logic We used Node.js for the application runtime and Express.js as the Node framework. JavaScript was primarily used in the backend development of application path/route handlers and other logic, as well as for the relevant Firestore database calls. On the front-end, we used EJS to handle data transfer between the client and the server, and HTML/CSS for webpage display and aesthetic design.
Challenges we ran into
One of the largest challenges was the data processing. The nature of the data itself was clear and comprehensive, but the sheer size made it difficult to manage and test. The limitations of Firestore's read/write capacity forced us to look to alternative measures of storage (the API). Then came the processes and the actual 'drawing of insights'. In this case, our insights were predictions based on sourceLocation, destination, and time of day. While a relatively simple concept, conceptualizing how to come up with an algo to handle that, given data from every single day at specific start and end times, proved a bit difficult.
Accomplishments that we're proud of
Learning and working hard! The challenges listed above were the most aggravating and time consuming, but gave us an opportunity to stretch our knowledge and work together. We were all learning from our mistakes. We were also all learning new things -- with some working with cloud tech that they had never worked with before (ex: GCP), to others using languages they weren't as familiar with.
What we learned
Be wary of Firestore read/write capacity. Be wary of merge conflicts. Delegate tasks more effectively early on.
What's next for Miopredictions
As mentioned above, we do have some ideas for scaling this feature. But, that might take some ramp up time and slight bug fixes. In the meantime, we will take all we've learned to keep coding and thinking of mobility!
Log in or sign up for Devpost to join the conversation.