-
-
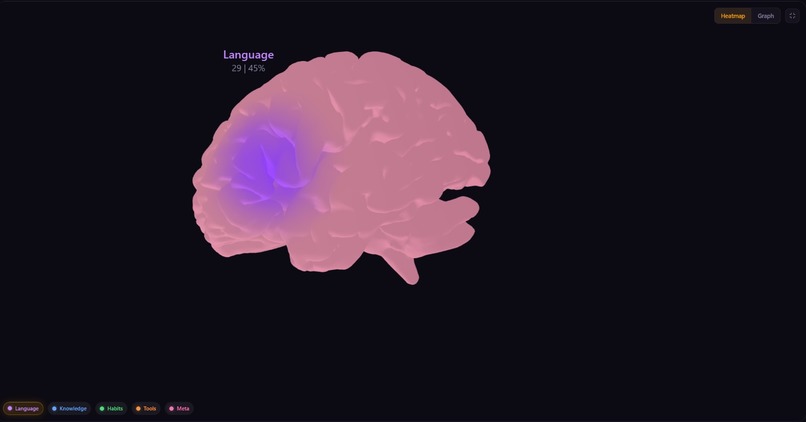
This is the the image of your second brain
-
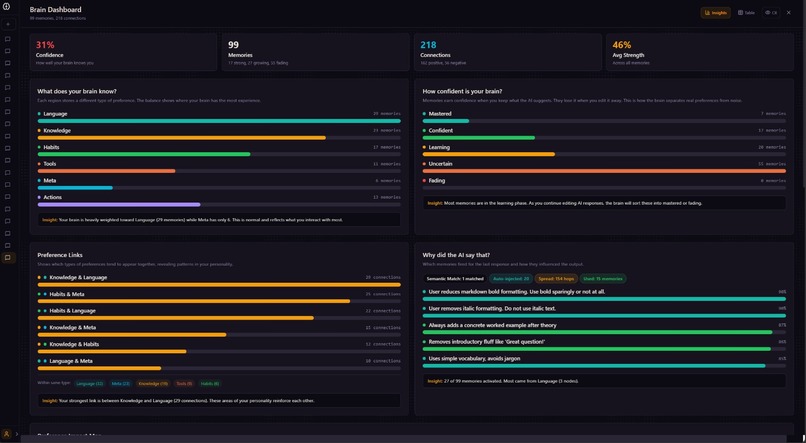
Inclusive Visualization part 1
-
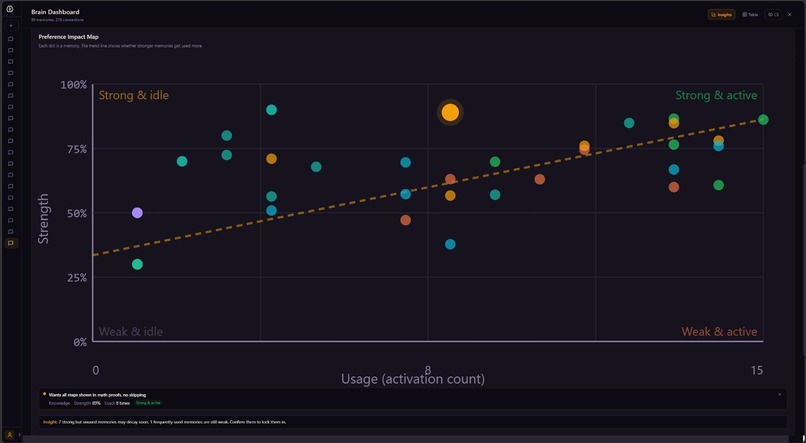
Inclusive Visualization part 2
-
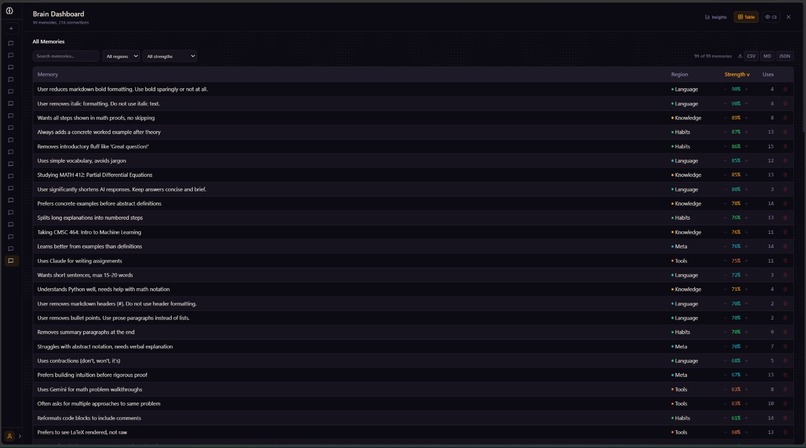
Change the nodes of your brain
Inspiration The way most people use AI today is kind of ridiculous when you think about it. You have a question, you stop what you're doing, open a new tab, type it out, read the response, then go back to work. The AI has no idea what you were looking at. It doesn't know your screen, your context, or how you think. It's a tool you interrupt yourself to go visit.
The second problem is that none of these tools remember anything. You've had thousands of conversations with ChatGPT. It knows nothing about you. You still explain that you want simple language, no bullet points, show intermediate steps. Every single time. That's not a tool that learns from you, that's a tool you babysit.
We wanted to build something that actually watches how you work and gets better from it passively, without you having to do anything differently.
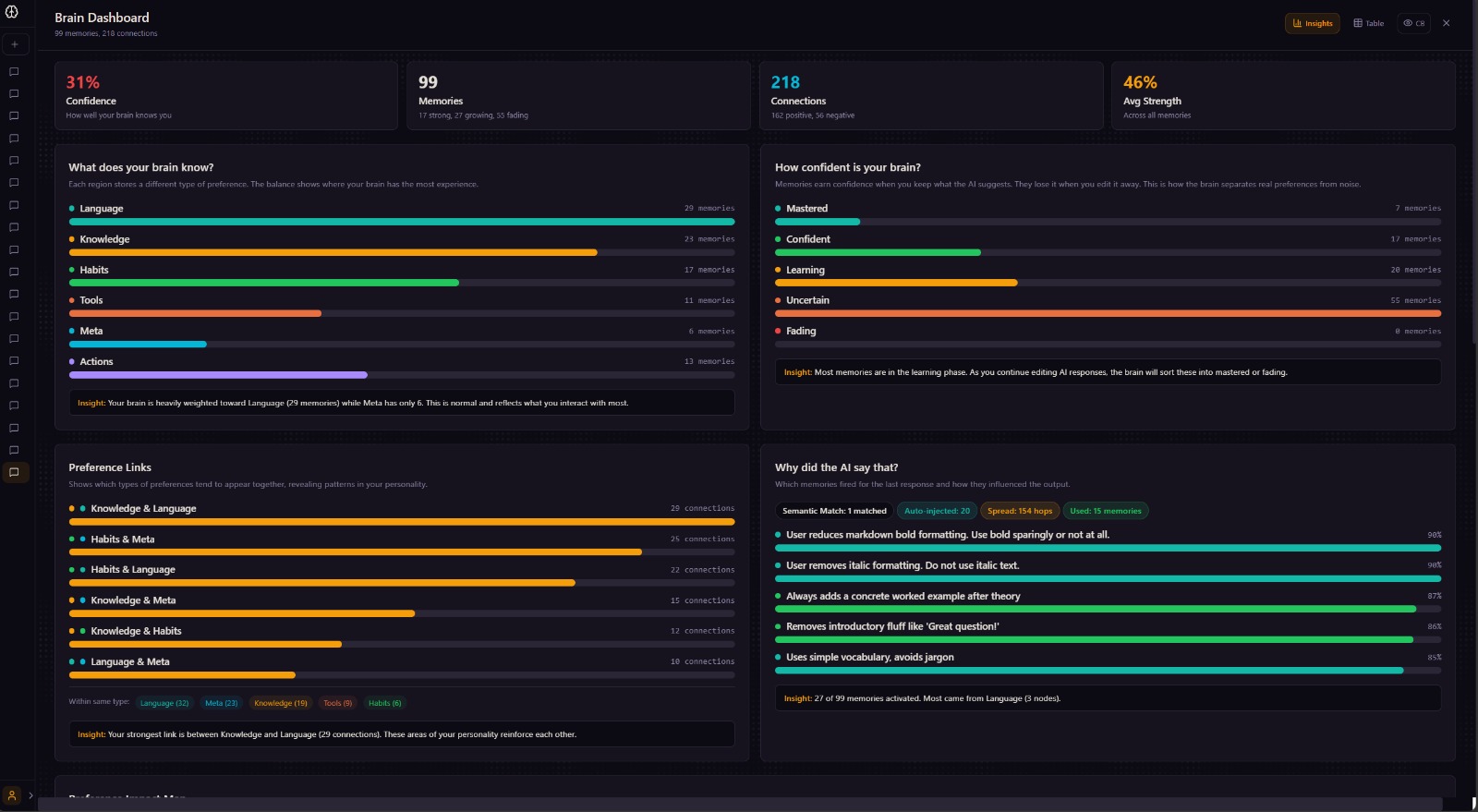
What it does MiniMe sits underneath your entire workflow and builds a persistent memory of how you think.
When Screenpipe is running, MiniMe is watching passively in the background. It reads your screen via OCR every 10 seconds -- whatever you're doing, whatever app you're in, whatever you're reading, writing, or building. You never had to open MiniMe. It saw what you were doing and learned from it anyway. The brain builds a picture of how you work across your entire computer, not just inside one chat window.
When you use the MiniMe chat, every edit you make to an AI response teaches the brain something. Remove bullet points and it learns you prefer prose. Simplify a paragraph and it learns your reading level. Delete a suggestion entirely and it creates a negative association so that pattern gets suppressed next time. The gap between what the AI gave you and what you actually wanted becomes memory.
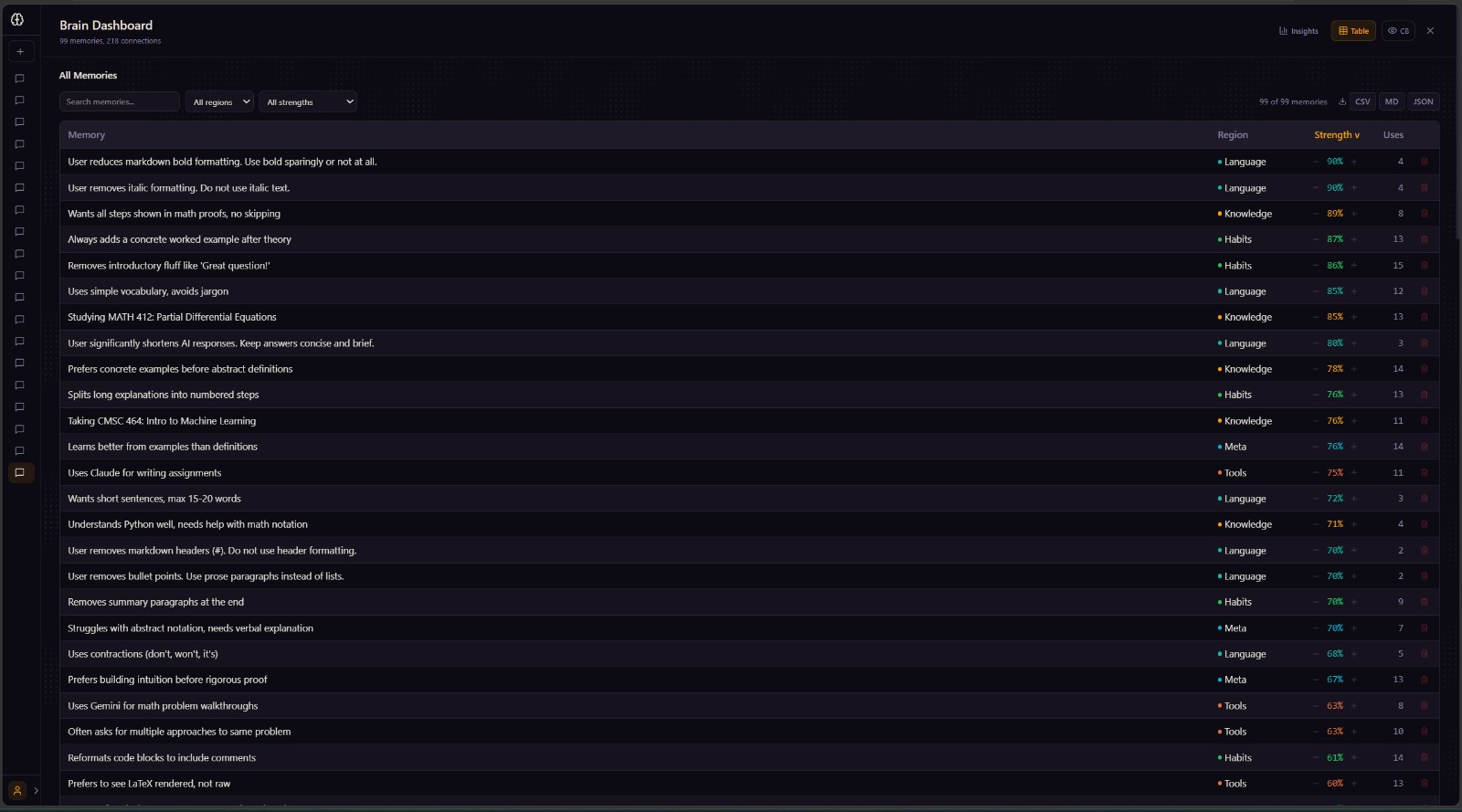
That memory is stored as a weighted graph -- not a database, not a flat list. Nodes for preferences, edges for relationships, spreading activation on retrieval. Every new prompt pulls the most relevant memories in automatically, and the AI starts responding the way you'd respond.
Hold Ctrl+Space anywhere on your computer and speak. Ask a question and a cyan orb appears, moves to the exact element on screen that the AI is talking about, and speaks the answer aloud. Gemini Vision looks at your screen, figures out the most relevant UI element, returns a normalized coordinate, and the overlay animates to that pixel. Ask where a button is, it points at it. Ask what something means, it points at that thing while explaining. Say a command and it executes it instead -- opens apps, clicks, types, scrolls. Your computer usage feeds back into the same brain as everything else.
How we built it Memory engine
The memory engine is NetworkX for in-memory graph traversal with SQLite underneath for persistence. Retrieval uses Gemini Embedding 2 (3072-dimensional vectors) -- cosine similarity against every node, then spreading activation [1] along edges to surface related preferences the query didn't directly match. Temperature is locked to zero with response caching so the same question against the same brain state always gives the same answer.
Why the brain actually works like a brain
We didn't just put memories in a graph and call it a brain. Each mechanism maps to a real cognitive process.
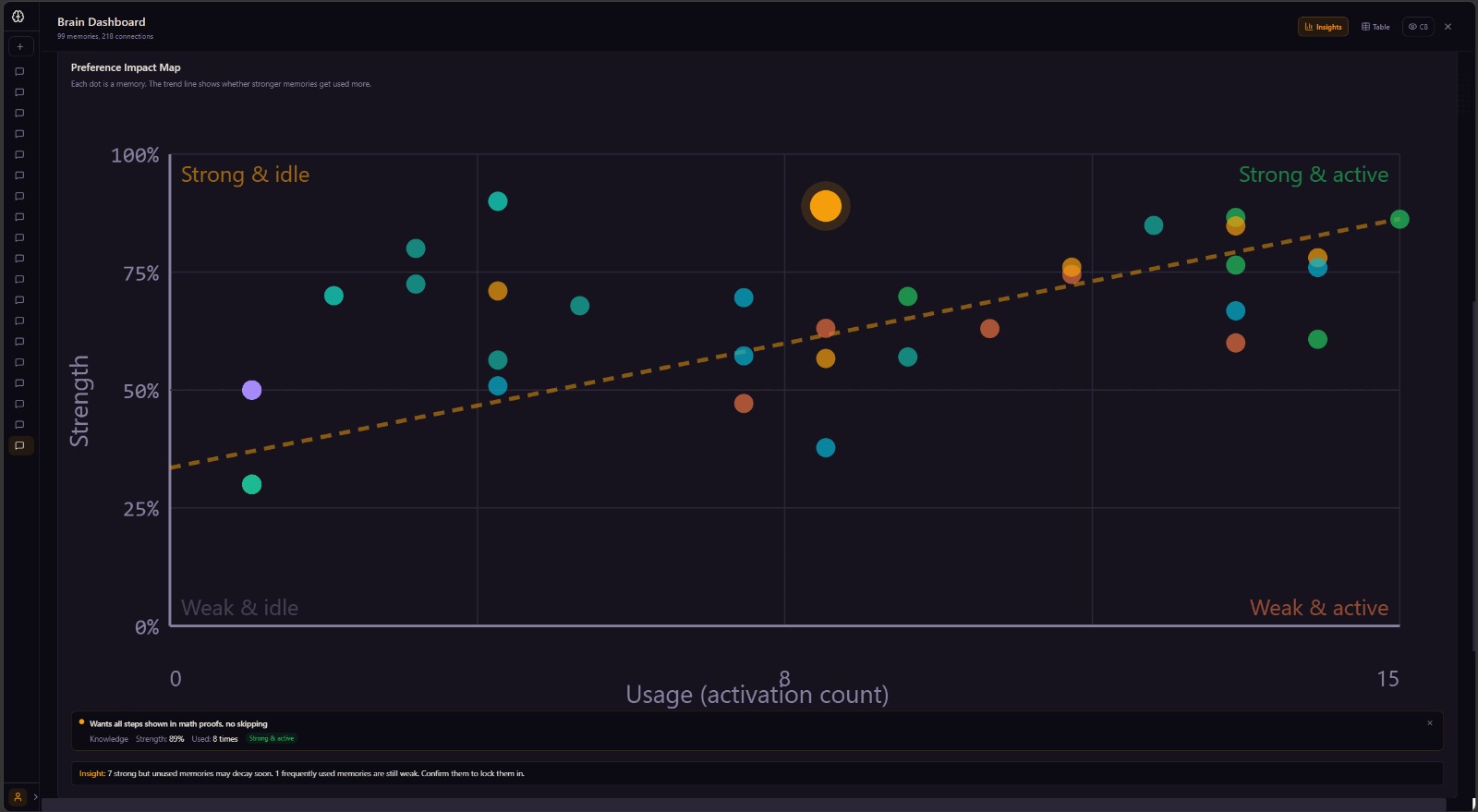
Unused memories decay proportionally to days since last activation -- the same forgetting curve Ebbinghaus described in 1885 [2]. Nothing gets deleted; dormant nodes reactivate when relevant context appears, matching how long-term memory consolidation works during sleep [3]. Nodes that fire together strengthen their connections (Hebbian learning [4]) -- so retrieving a memory about vocabulary automatically pulls in related memories about tone without any explicit link. When you reject something the AI suggested, a negative edge forms between that memory and the context that triggered it. Future activations in similar contexts suppress that node, which mirrors how the brain forms inhibitory associations through negative reinforcement [5].
When the brain encounters a new observation that contradicts a strongly held preference, it detects the conflict and discards the new one rather than storing opposing preferences simultaneously -- matching how human belief revision works under cognitive dissonance [6].
Raw episodes get compressed into concise memory nodes by an LLM during idle periods, mirroring how the hippocampus consolidates short-term episodic memory into long-term semantic memory during rest [3].
Why those brain regions
The six memory regions aren't arbitrary. Each maps to where those functions actually live in the brain:
Language and Style maps to Broca's area (BA44/45) and Wernicke's area (BA22), the two regions responsible for language production and comprehension [7] Domain Knowledge maps to the anterior temporal lobe and prefrontal cortex, associated with semantic long-term memory storage [8] Habits maps to the basal ganglia, which governs procedural memory and routine behavior [9] Tool Use maps to the parietal and premotor cortex, activated during tool manipulation and learned motor sequences [10] Metacognition maps to Brodmann area 10 and the anterior cingulate cortex, associated with self-monitoring and reflective thought [11] Neuroadaptive voice
The voice MiniMe speaks with isn't fixed. It adapts in real time based on which brain regions are currently activated. When domain knowledge nodes are firing, the voice slows down slightly and becomes more measured. When habit nodes are active, it speeds up and gets more casual. When language style nodes dominate, the delivery becomes warmer and more expressive.
This maps to research on prosody and cognitive load -- people naturally modulate speech rate and expressiveness based on the nature of the information they're conveying [12]. We implemented this through ElevenLabs' stability, style, and speed parameters, with each brain region contributing a weighted delta. The voice also learns from explicit feedback -- say "too fast" or "too robotic" and it adjusts its learned deltas persistently across sessions, so the voice keeps evolving the same way the memory does.
Brain visualization and accessibility
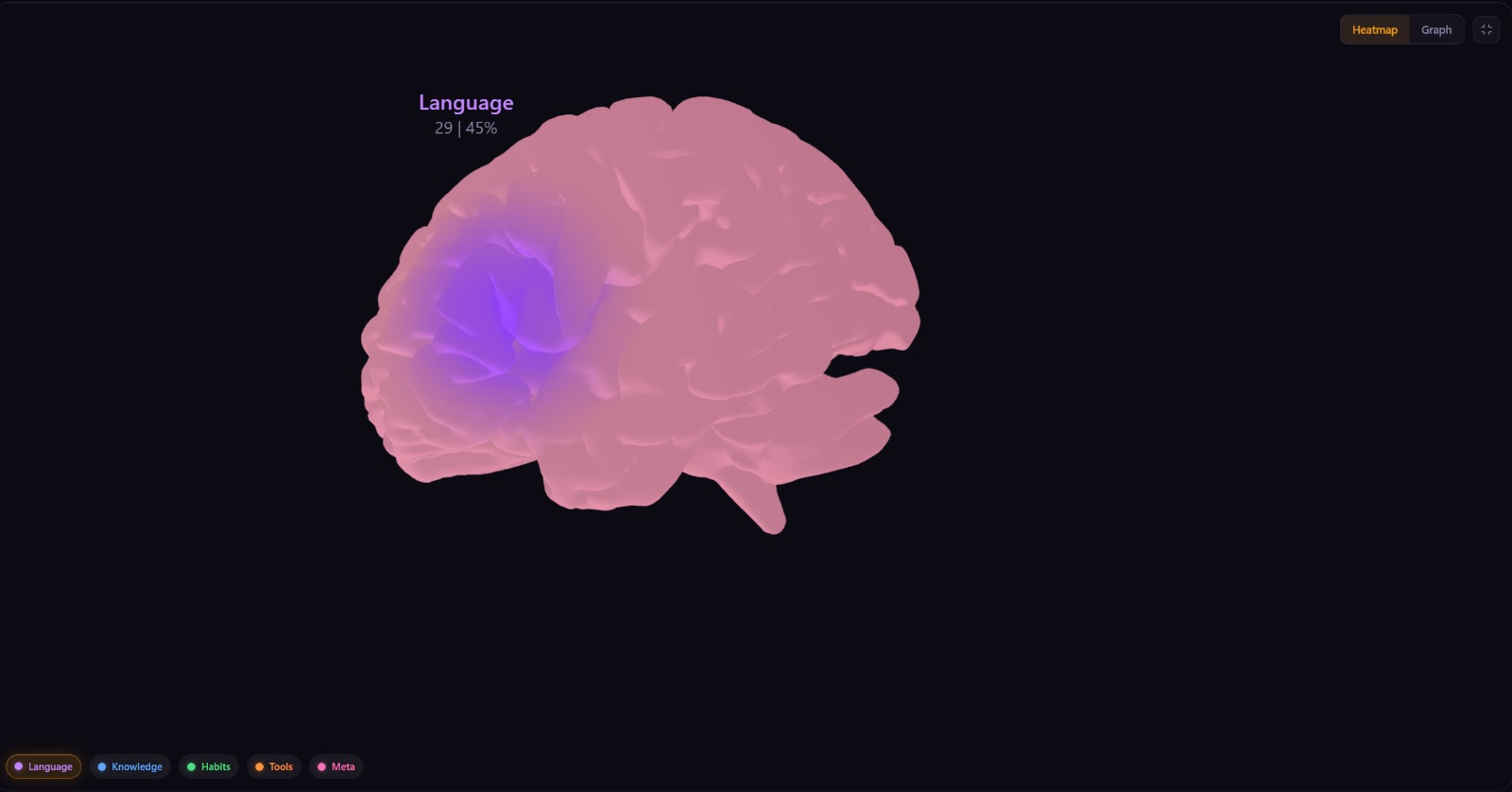
The 3D brain is a real neuroscience mesh -- the BrainNet Viewer ICBM152 model [13], cited in over 3000 papers, 77,000 vertices rendered with custom GLSL shaders in React Three Fiber. Memory nodes are distributed across anatomical regions using Fibonacci sphere placement around MNI coordinates so they spread evenly without overlap.
The heatmap mode pushes activation strength as a vertex attribute and colors flow across the brain surface like an fMRI scan. The graph mode lets you click individual nodes to see their connections -- activated nodes highlight, unrelated ones dim.
The region color palette was chosen deliberately for accessibility. The five region colors (violet, blue, green, amber, rose) are distinguishable under the three most common forms of color vision deficiency -- deuteranopia, protanopia, and tritanopia -- by separating them across both hue and luminance axes rather than relying on hue alone. A person who cannot distinguish red from green can still tell the difference between Habits (green, high luminance) and Tool Use (amber, warm hue) because the brightness contrast is sufficient. This matters because roughly 8% of men have some form of color vision deficiency [14].
Voice overlay
The overlay is PyQt6 running a transparent always-on-top fullscreen window with Win32 extended styles (WS_EX_TRANSPARENT, WS_EX_LAYERED) so it never intercepts mouse events or blocks your work. The orb animates with a 600ms InOutCubic easing curve and pulses continuously while active. Screenpipe polls every 10 seconds, deduplicates captures by MD5 hash, and filters out noise using a response-pattern indicator threshold before anything reaches the brain.
Challenges we ran into Getting the memory to learn the right thing was the hardest part. A naive diff picks up everything -- reformatting, rephrasing, content changes -- and you can't treat all of those the same. We built an edit classifier: formatting-only changes hit style nodes immediately at 60% strength, content removals weaken the nodes most activated for that specific prompt, and both create negative edges for future suppression. Getting that classification accurate without false positives took most of the backend time.
Screenpipe captures everything on screen, which means a lot of noise. Toolbar labels, tab titles, partially typed sentences -- all of it comes in as OCR text. We wrote a filter that only stores an episode when the captured text contains at least two response-pattern indicators (phrases like "for example", "step 1", code blocks) and exceeds a minimum length. Without that, the brain fills up with garbage fast.
The orb pointing required Gemini to reliably embed a normalized coordinate inside a natural language response. Getting it to point at a specific element rather than the general area of the screen meant careful prompt engineering around the coordinate system with explicit examples of near-edge elements and a strict output format that the parser could extract cleanly.
Accomplishments that we're proud of The Screenpipe integration working transparently is the one that felt the best. You open any app, do anything, never touch MiniMe, and the brain learned from it. That passive accumulation across your whole workflow -- not just inside one chat interface -- is what makes this different from a better chatbot.
The moment the orb correctly pointed at a specific button while answering a question about it, it stopped feeling like a voice assistant and started feeling like someone sitting next to you.
The brain model being real neuroscience rather than decorative also mattered to us. The regions map correctly, the activation patterns reflect what's actually firing, and you can drill into individual nodes to see exactly what the brain knows and why.
What we learned Biological memory is a surprisingly good model for this problem. Spreading activation, Hebbian learning, decay, consolidation -- these aren't just metaphors. They solve real engineering problems. Spreading activation is why retrieving a memory about vocabulary automatically surfaces related memories about tone without any explicit connection. Decay is why the brain doesn't get cluttered with one-off preferences. We ended up reading more neuroscience papers than we expected and using more of what we read than we expected.
What's next for MiniMe Screenpipe already watches your full workflow. The next step is making the brain smarter about what it infers from behavior rather than just what you explicitly teach it in chat. It should know you prefer visual explanations because you always open the diagram tab. It should know you work in focused blocks because of how you move between apps. Preferences inferred from how you actually work, without you having to say anything.
The orb pointing works for questions. The next version uses it for proactive nudges -- the brain notices you have been stuck on the same thing for ten minutes and surfaces a relevant memory without you asking.
References
[1] Collins, A. M., & Loftus, E. A. (1975). A spreading-activation theory of semantic processing. Psychological Review, 82(6), 407-428.
[2] Ebbinghaus, H. (1885). Uber das Gedachtnis. Duncker & Humblot.
[3] Stickgold, R. (2005). Sleep-dependent memory consolidation. Nature, 437, 1272-1278.
[4] Hebb, D. O. (1949). The Organization of Behavior. Wiley.
[5] Rescorla, R. A., & Wagner, A. R. (1972). A theory of Pavlovian conditioning. In A. H. Black & W. F. Prokasy (Eds.), Classical Conditioning II. Appleton-Century-Crofts.
[6] Festinger, L. (1957). A Theory of Cognitive Dissonance. Stanford University Press.
[7] Broca, P. (1861). Remarques sur le siege de la faculte du langage articule. Bulletins de la Societe Anatomique de Paris, 6, 330-357.
[8] Patterson, K., Nestor, P. J., & Rogers, T. T. (2007). Where do you know what you know? The representation of semantic knowledge in the human brain. Nature Reviews Neuroscience, 8, 976-987.
[9] Knowlton, B. J., Mangels, J. A., & Squire, L. R. (1996). A neostriatal habit learning system in humans. Science, 273, 1399-1402.
[10] Johnson-Frey, S. H. (2004). The neural bases of complex tool use in humans. Trends in Cognitive Sciences, 8(2), 71-78.
[11] Fleming, S. M., Weil, R. S., Nagy, Z., Dolan, R. J., & Rees, G. (2010). Relating introspective accuracy to individual differences in brain structure. Science, 329, 1541-1543.
[12] Scherer, K. R. (2003). Vocal communication of emotion: A review of research paradigms. Speech Communication, 40(1-2), 227-256.
[13] Xia, M., Wang, J., & He, Y. (2013). BrainNet Viewer: A network visualization tool for human brain connectomics. PLOS ONE, 8(7), e68910.
[14] Sharpe, L. T., Stockman, A., Jagle, H., & Nathans, J. (1999). Opsin genes, cone photopigments, color vision, and color blindness. In K. Gegenfurtner & L. T. Sharpe (Eds.), Color Vision: From Genes to Perception. Cambridge University Press.



Log in or sign up for Devpost to join the conversation.