
Inspiration
As someone who uses AI often, I noticed a frustrating pattern: every conversation felt like starting over. Chatbots felt personal in the moment, but they forgot details from older conversations, didn’t apply past experiences consistently, and couldn’t connect events across time.
The problem isn’t the intelligence of the model — it’s the architecture. Identity and memory aren’t persistent.
I wanted to build something fundamentally different: an AI that doesn’t just respond to you, but actually remembers you and thinks like you. No more temporary chat context, but a persistent, searchable memory of your life. That idea became Ditto — a digital twin grounded in your real experiences, capable of evolving with you over time.
What it does
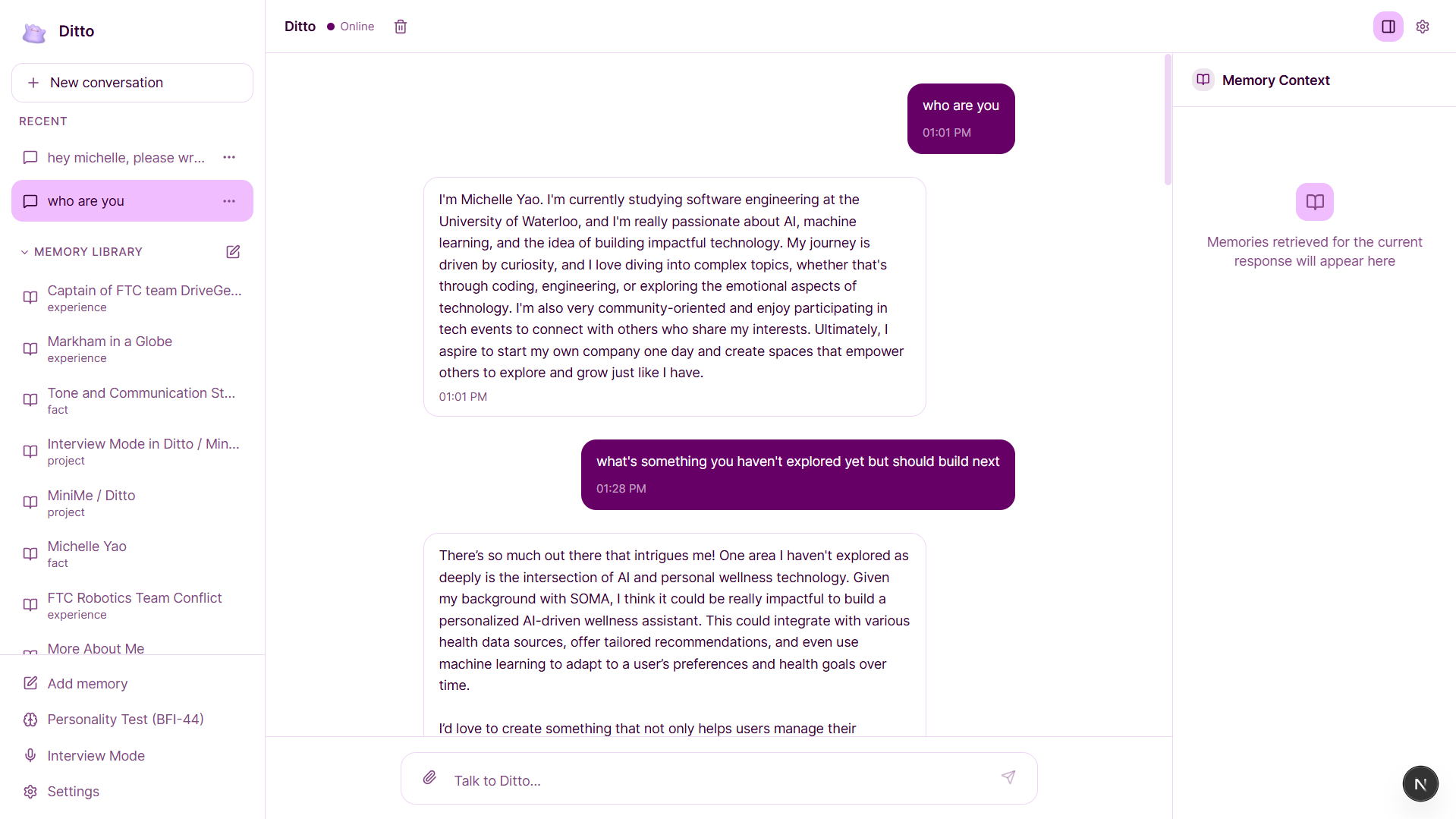
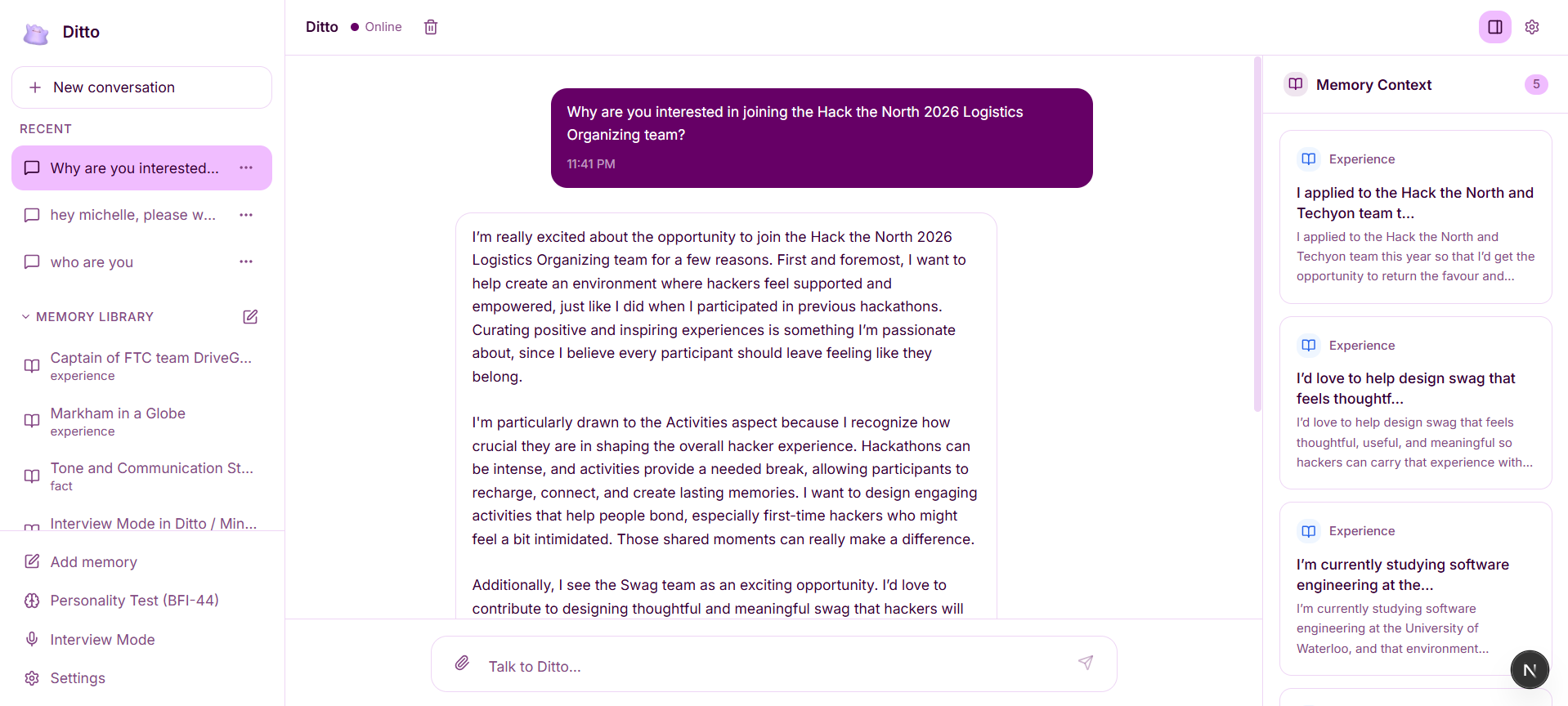
Instead of relying on a limited chat window, Ditto stores memories permanently, retrieves the most relevant ones using semantic search, and injects them into every response. This allows it to speak from your life context, not generic assumptions.
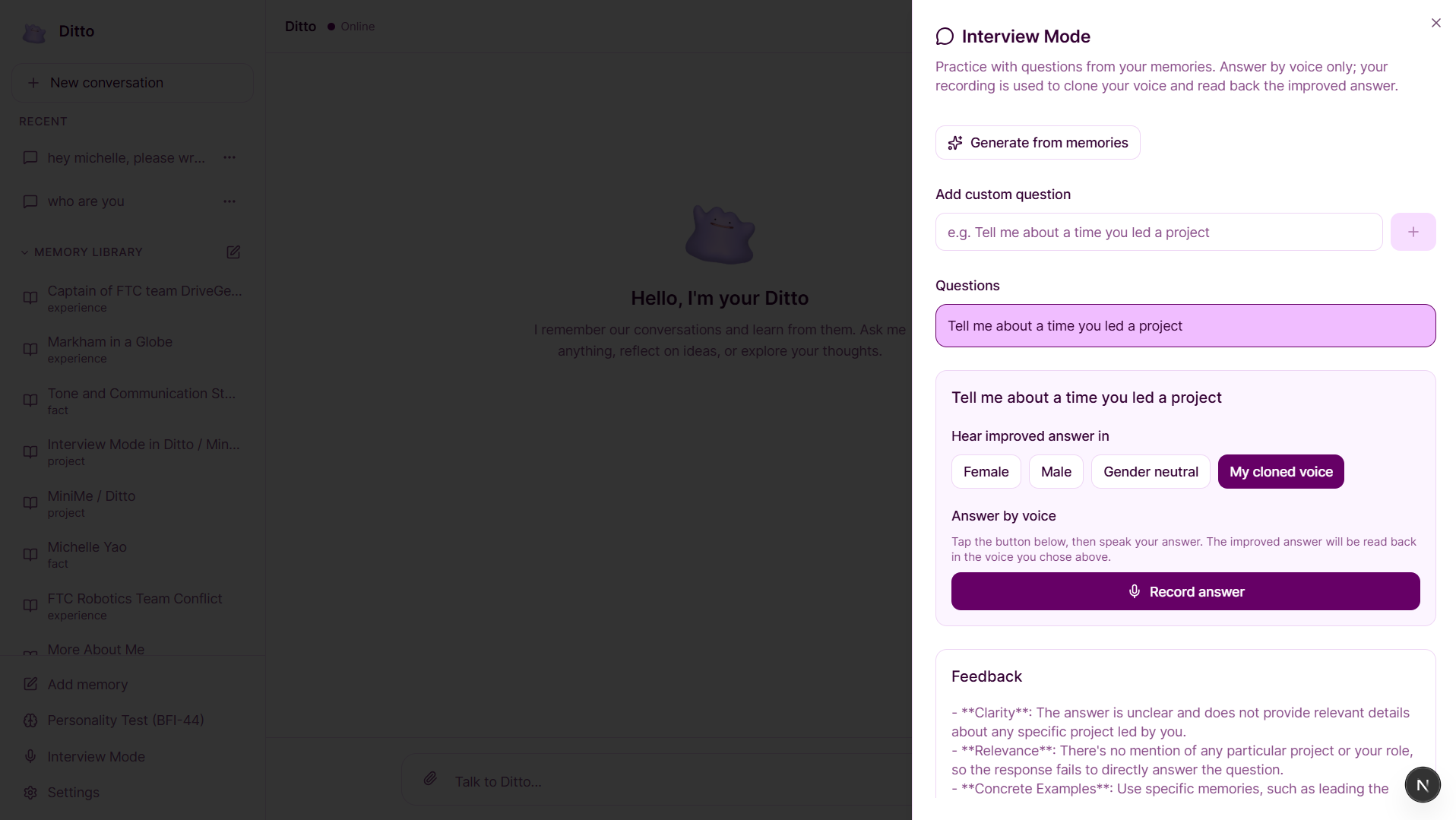
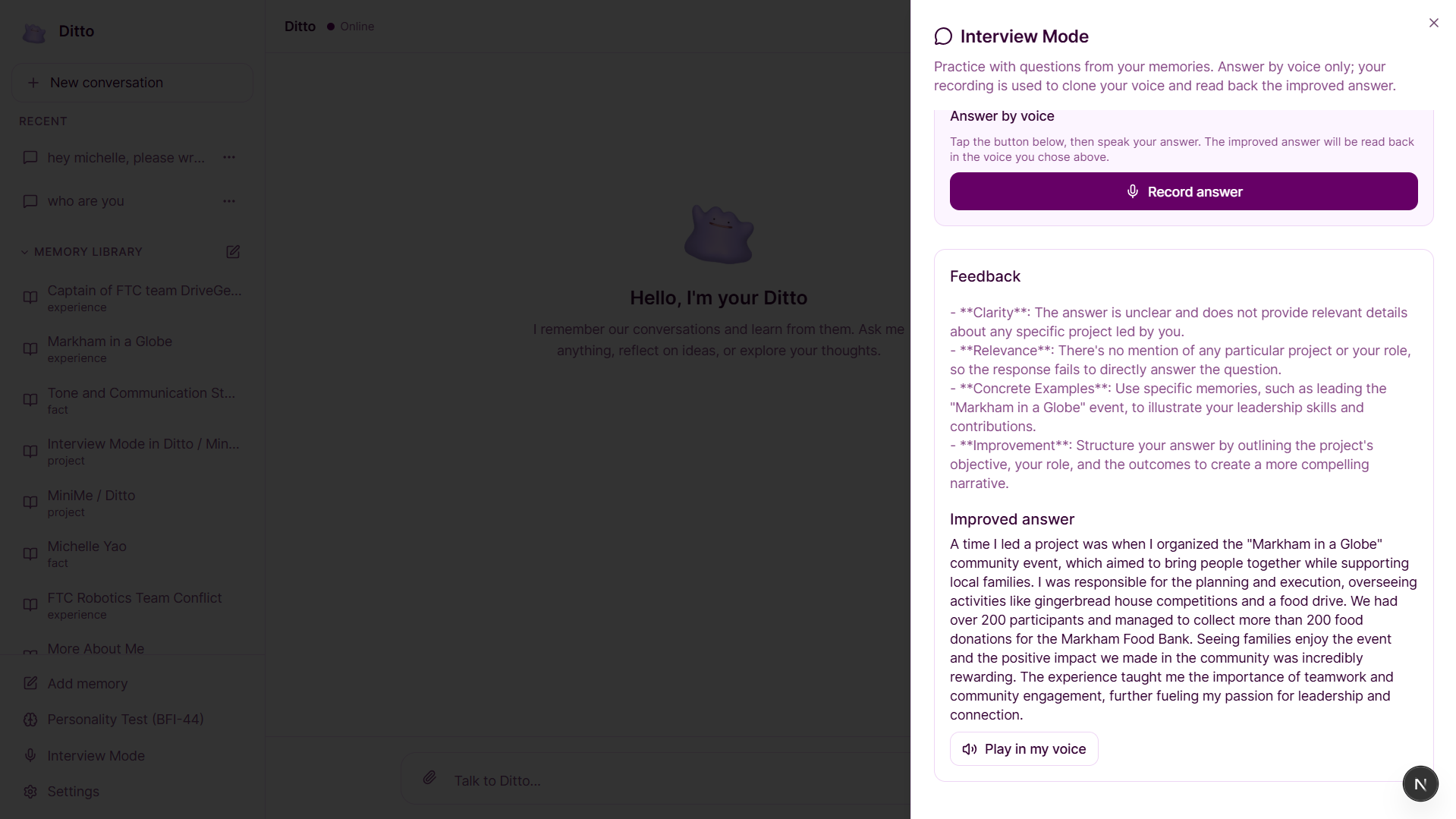
Ditto also includes Interview Mode, where it generates realistic behavioral interview questions based on your actual experiences, provides structured feedback, and produces an improved version of your answer grounded in your memory. Ditto understands, remembers, and coaches you.
How we built it
Ditto is a full end-to-end Retrieval-Augmented Generation system designed around persistent identity.
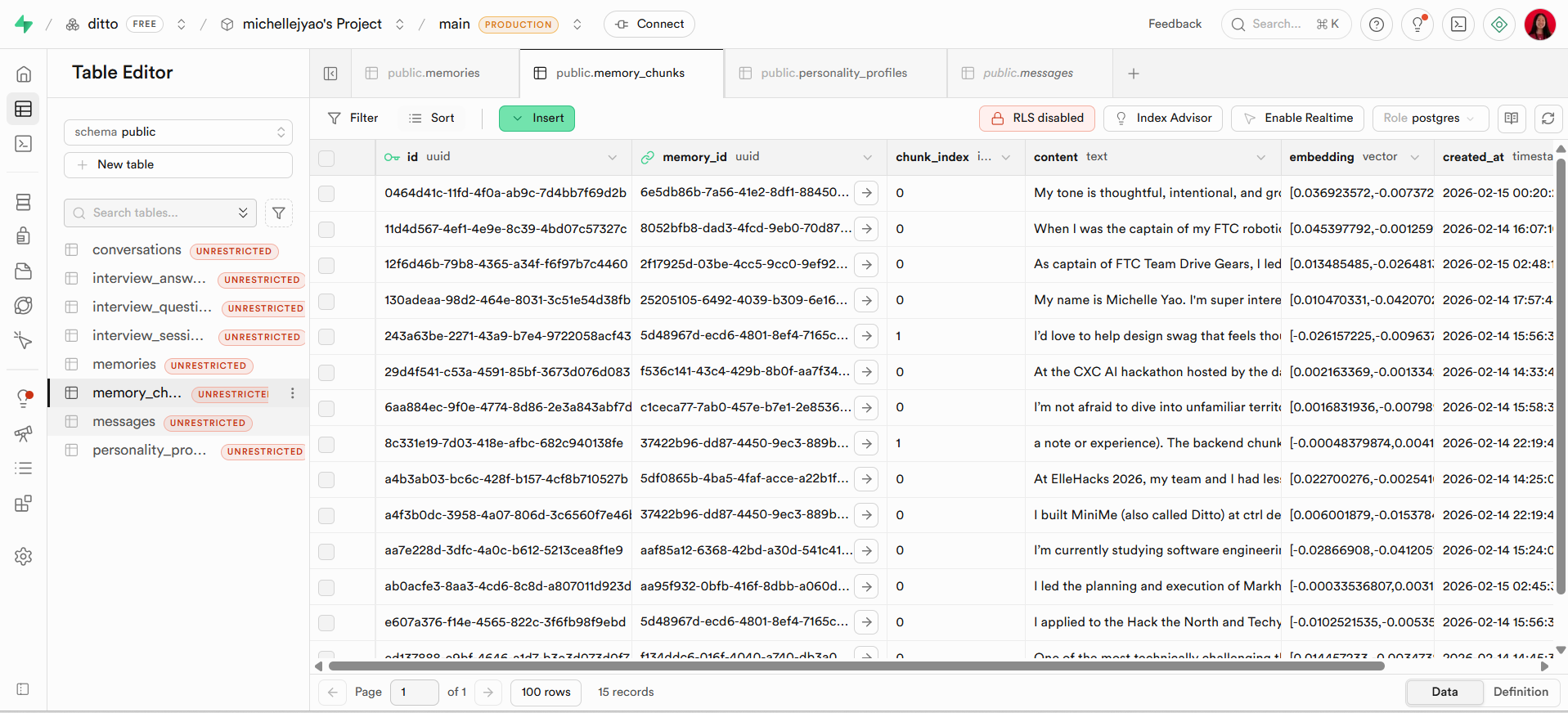
Memories are ingested, chunked using tiktoken, embedded with OpenAI’s text-embedding-3-small, and stored in Supabase Postgres with pgvector using HNSW indexing and cosine similarity search. When a user sends a message, the system embeds the query, retrieves the most relevant memory chunks, and injects them into the prompt alongside a fixed digital-twin system identity. GPT-4o-mini then generates responses grounded in those memories.
The backend runs on FastAPI, managing ingestion, retrieval, and generation pipelines. Interview Mode reuses the same architecture, adding Whisper for voice transcription and ElevenLabs for text-to-speech so users can hear improved answers in their own voice.
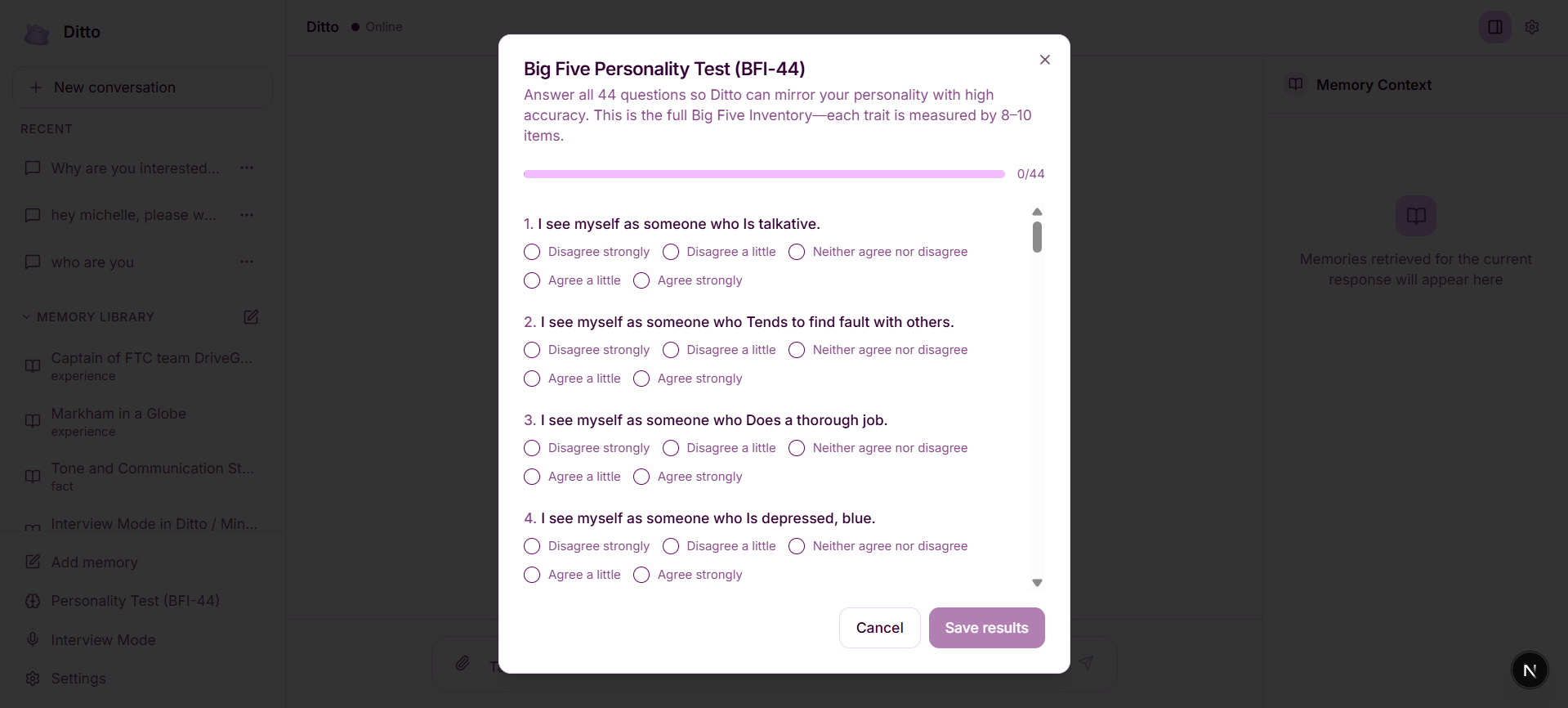
To make the digital twin reflect not just the user’s experiences but also their personality, we implemented a Big Five (OCEAN) personality test. The user’s openness, conscientiousness, extraversion, agreeableness, and neuroticism scores are stored as structured personality metadata and injected into the prompt alongside retrieved memories. This allows the model to adjust tone, communication style, and response structure to match the user, making the AI feel more authentically like them.
This architecture ensures identity comes from retrieval, not temporary context.
Challenges I ran into
The biggest challenge was treating memory as a first-class system component, not just an extension of chat context. This required designing a dedicated memory database, tuning chunk sizes and retrieval parameters, and ensuring relevant memories surfaced consistently.
I also needed to handle time-aware identity — making sure responses reflected who the user was at different points in time using structured metadata like occurred_at.
Another key challenge was architectural simplicity. Instead of building Interview Mode as a separate system, I designed it to reuse the same RAG pipeline, so that one identity-grounded retrieval layer could power multiple features.
Accomplishments that I'm proud of
I successfully built a true digital twin architecture where identity emerges from persistent memory retrieval, not prompt tricks.
I designed a unified system where chat, coaching, and voice interaction all use the same memory foundation, showing the scalability of identity-grounded AI.
Most importantly, this project transformed my understanding of RAG from theory into practice. I learned how embeddings and vector databases work a year ago, and was finally able to implement what I learned.
What we learned
I gained deep hands-on experience designing a full RAG pipeline, including chunking strategies, embedding generation, vector indexing with pgvector and HNSW, and semantic retrieval tuning.
I learned how database structure shapes AI behavior, and how structured metadata and retrieval logic directly affect identity consistency.
What's next for Ditto
I plan to expand Ditto into a fully persistent identity platform with richer memory ingestion, bulk import from past conversations, and smarter retrieval using hybrid search and reranking.
I also want to improve Interview Mode with deeper coaching, tone analysis, and personalized feedback over time.
I also want to add a functionality where if the user is not satisfied with the response Ditto gave, the user can tell Ditto what's wrong with the response and provide a response they would have liked to see so that Ditto can learn from its mistakes and reflect its users better.
Ditto will evolve into a lifelong digital twin that grows with you — remembering your experiences, reflecting your identity, and helping you navigate the future.
Built With
- embeddings
- fastapi
- next.js
- node.js
- pgvector
- postgresql
- python
- rag
- react
- supabase
- typescript


Log in or sign up for Devpost to join the conversation.