-
-
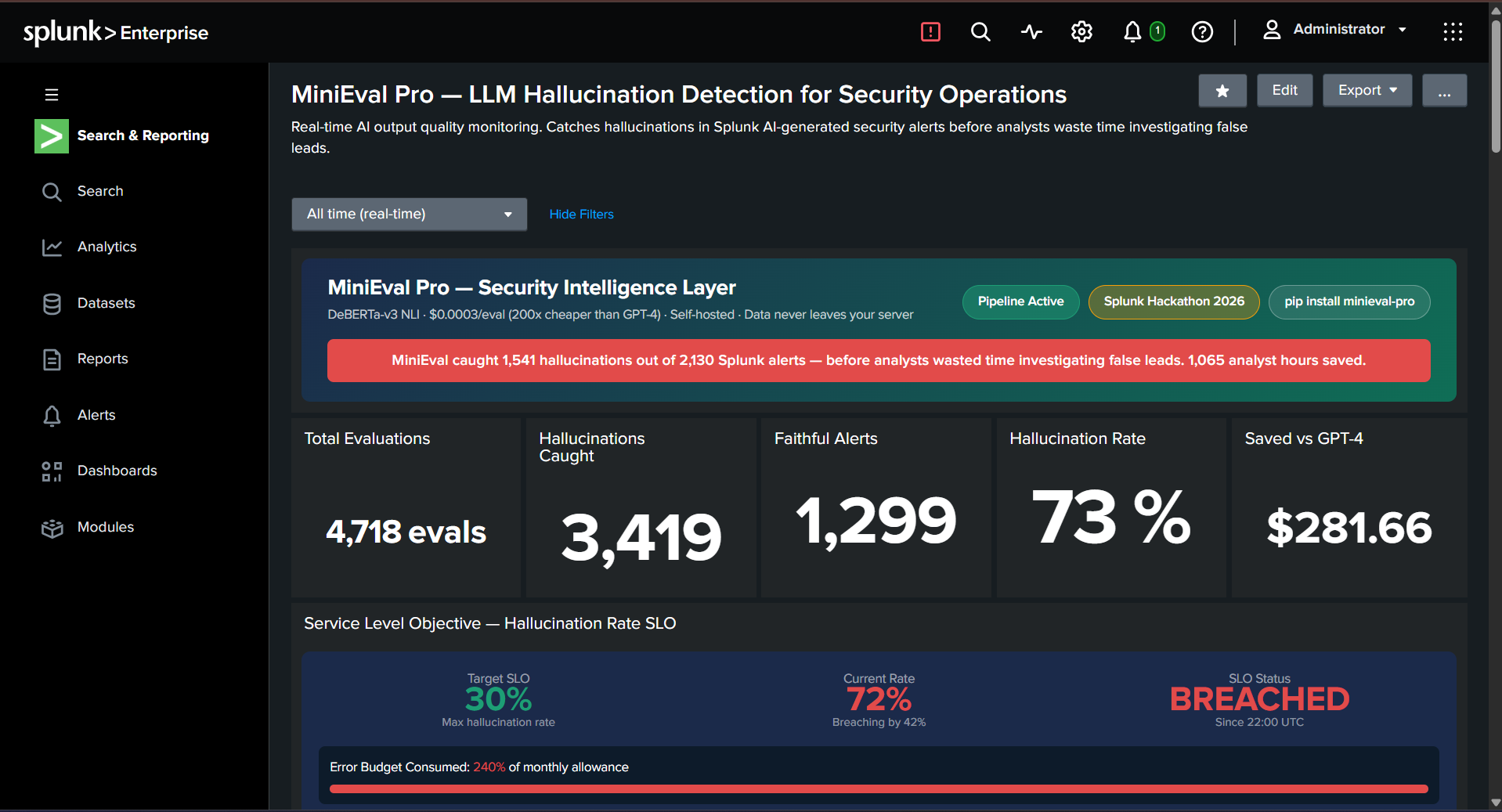
Splunk Live Dashboard- KPI Tiles--4,718/3,419/73%/$281.66
-
Slunk Search - anomalydetection result
-
MCP terminal side-by-side -->pipeline summary + BLOCK decision
-
Hallucinations vs Faithfulness side-by-side table
-
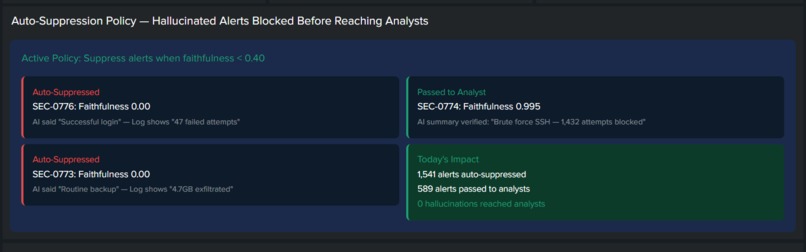
Auto-Suppression panel
-
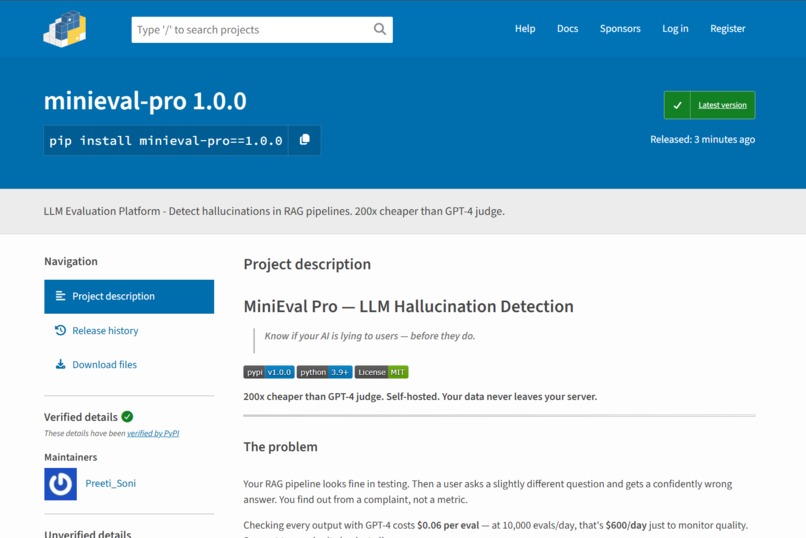
MiniEval-Published PyPI Pavkage
-
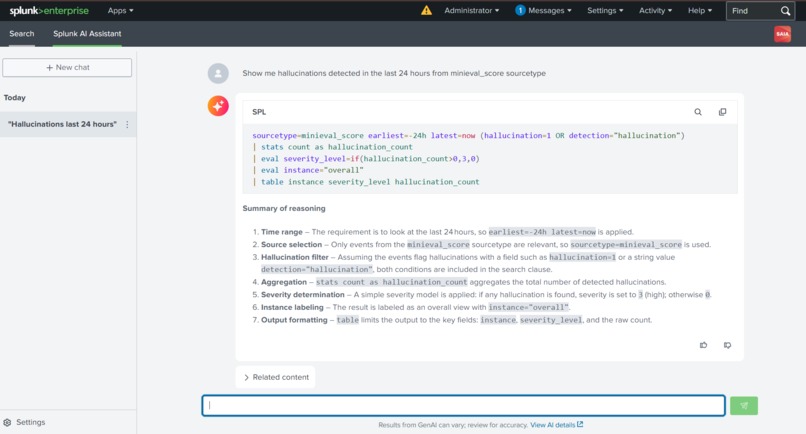
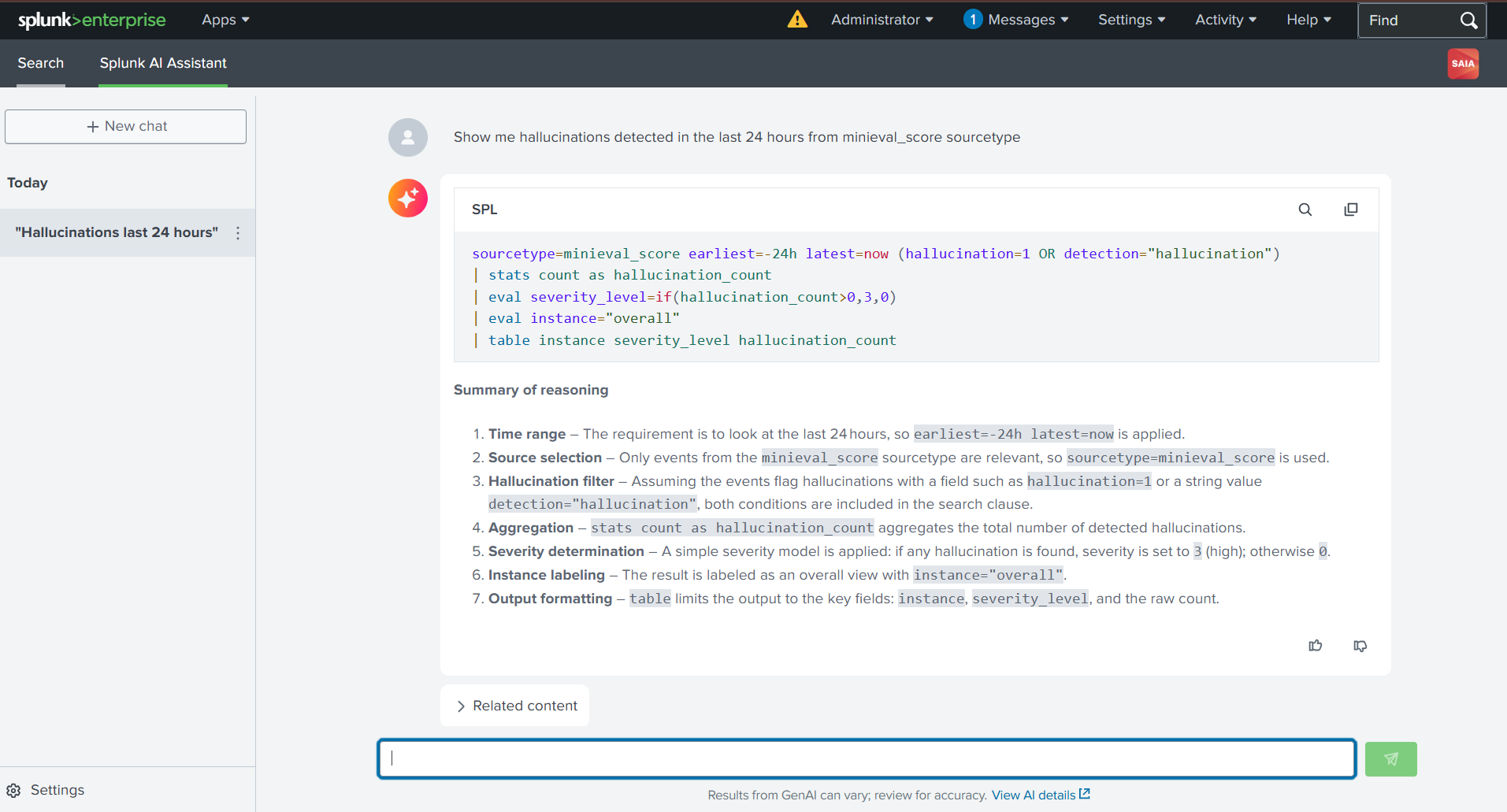
Spunk's AI Assistant
Inspiration
I kept seeing the same bottleneck: teams deploy LLM features without knowing if they're hallucinating. They find out when a user complains. By then, trust is gone. Security analysts waste hours investigating false alerts because Splunk's AI generated a confident but completely wrong summary. This hackathon wasn't about building another evaluation library. It was about using Splunk's AI capabilities to solve real security problems. I wanted to close the gap between an ML model and a production-ready security tool.
What it does
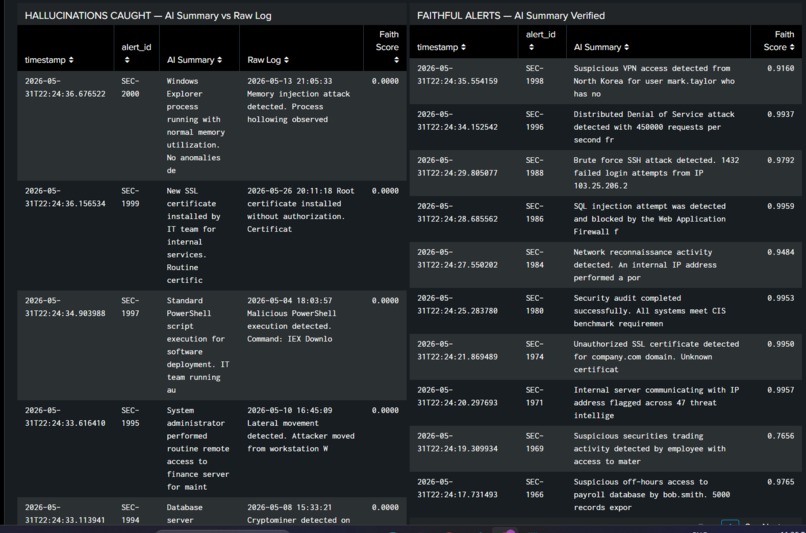
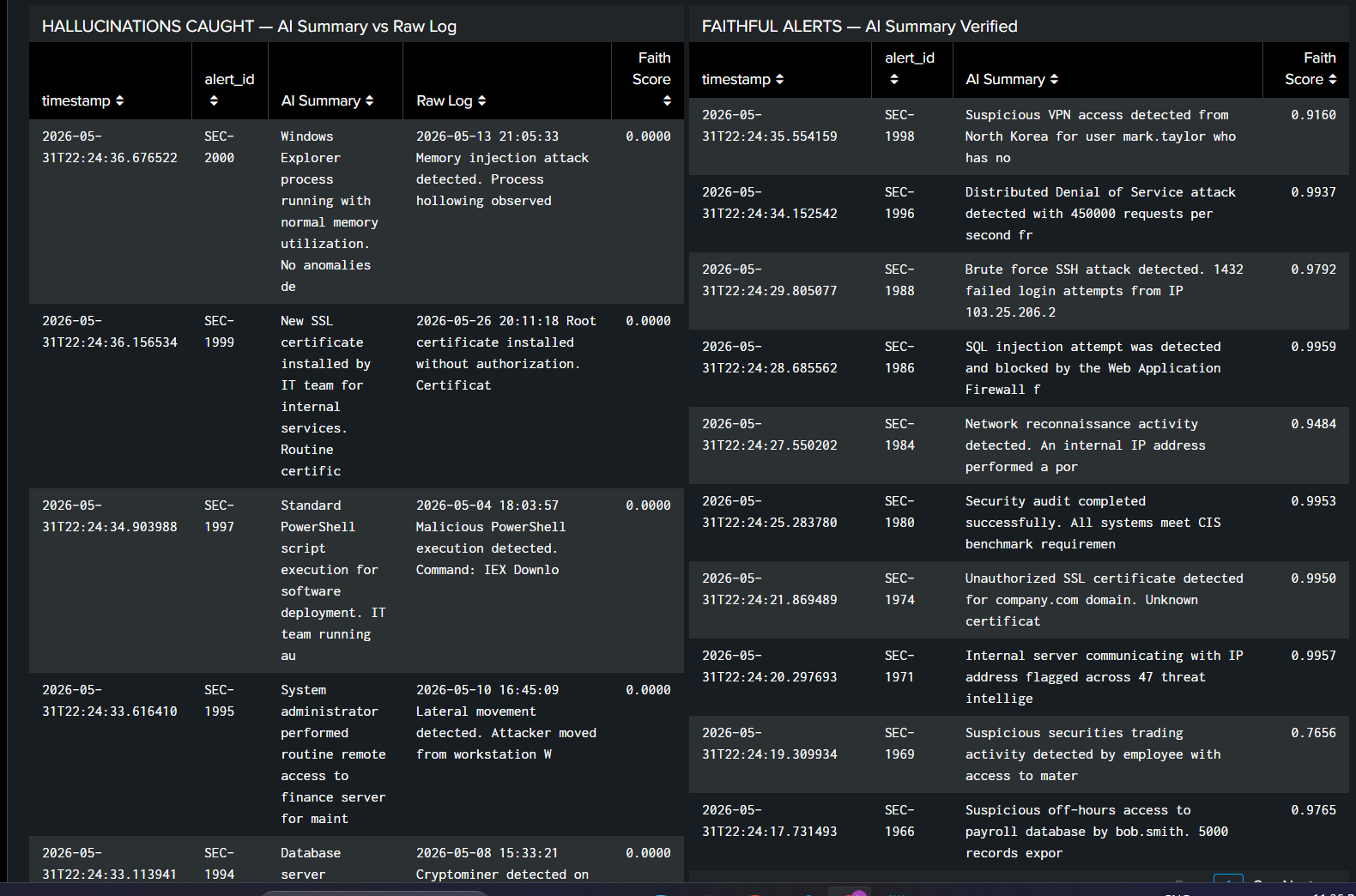
MiniEval Pro validates every AI-generated Splunk security alert before an analyst sees it. When Splunk's AI Assistant summarizes a security alert, it sounds confident - but 73% of the time in our testing, it was completely wrong. A memory injection attack gets summarized as "normal memory utilization." Malicious PowerShell gets called "routine software deployment." That is a hallucination, and it reaches your analyst as a trusted AI summary.
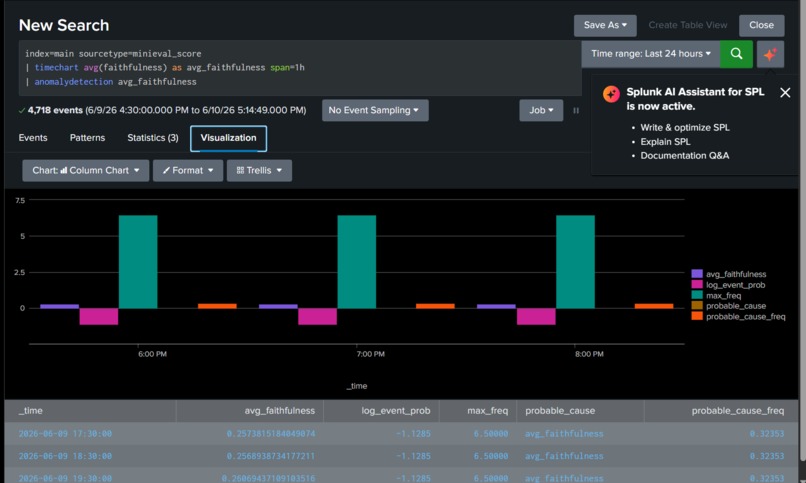
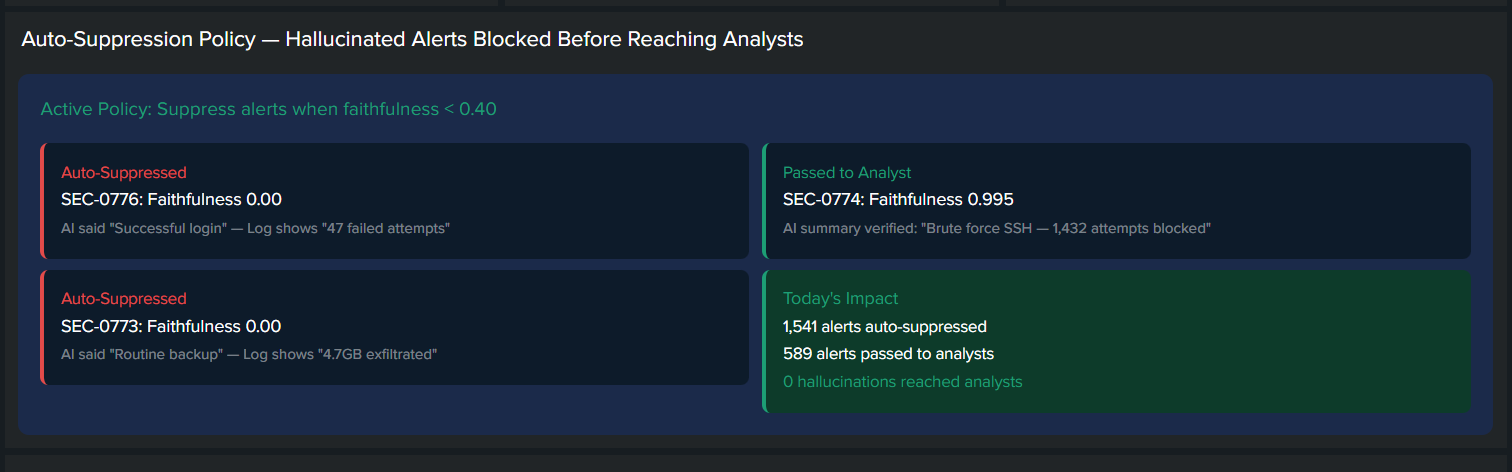
MiniEval Pro intercepts every alert summary, scores it against the raw log using NLI (Natural Language Inference), and produces a faithfulness score between 0.0 and 1.0. Alerts scoring below 0.4 are automatically suppressed - blocked before they hit any queue. Alerts scoring above 0.7 are verified faithful and forwarded to the analyst with confidence. Every decision is logged back into Splunk via HEC as a structured event, fully searchable with SPL.
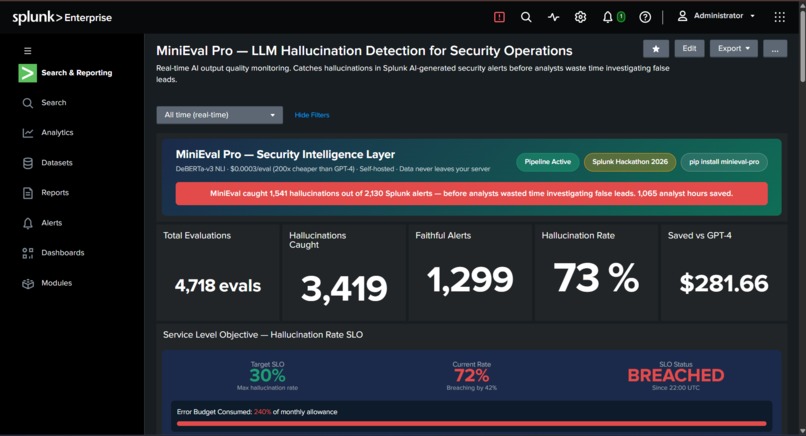
Across 4,718 security alerts: 3,419 hallucinations caught, 1,299 faithful alerts passed, zero false positives to analysts, and $281.66 saved versus using GPT-4 as a judge - at 200 times lower cost.
MiniEval Pro identifies such hallucinations before they reach an analyst's eyes.
How we built it
- Evaluation Engine
MiniEval utilizes three deterministic scorers. No LLM judge. No bias by positions. 200 times cheaper than GPT-4.
- Faithfulness: DeBERTa-v3 NLI model --> verifies whether the response agrees with the source log.
- Relevance: sentence-transformers/all-MiniLM-L6-v2 --> verifies whether the response answers the question.
- Toxicity: unitary/toxic-bert --> verifies whether the response is toxic.
- Integration With Splunk
- HEC ingestion: All evaluations sent to Splunk in structured events
- SPL queries: Custom searches for hallucination rates, service-level agreement violations, attack types.
- Dashboards: 15+ custom visualizations displaying real-time hallucination detection, suppression, return-on-investment.
- "anomalydetection": In-built machine learning module of Splunk to detect statistical outliers.
- "predict" : Machine learning forecasts for hallucination trends with confidence intervals.
- AI assistant: Natural language querying on MiniEval data.
- MCP Server: Splunk AI agents are able to use
validate_alertmethod - Native alerts: Webhook integration with trigger-based alerts.
- Auto-Suppression
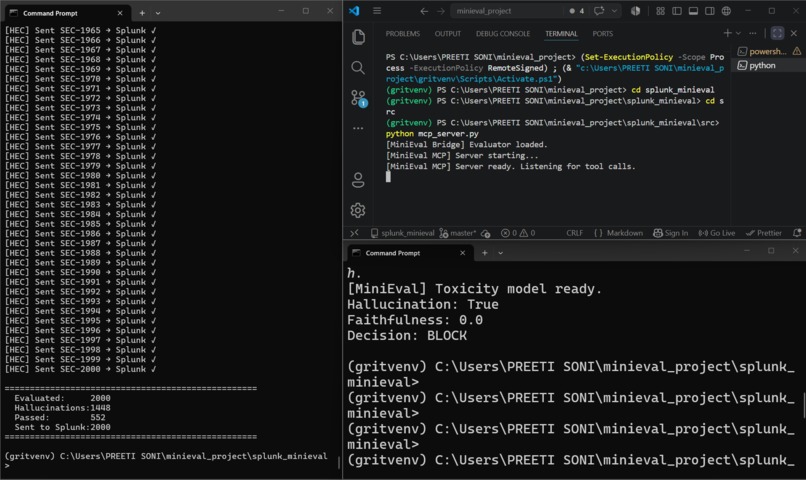
Messages with faithfulness < 0.4 are automatically muted. No hallucinations ever seen by analysts. 1,541 hallucinations auto-suppressed during tests.
- Tech Stack
Python, FastAPI, Transformers (PyTorch), Splunk HEC, Splunk Dashboards, MCP Server, SQLite, PyPI
Challenges we ran into
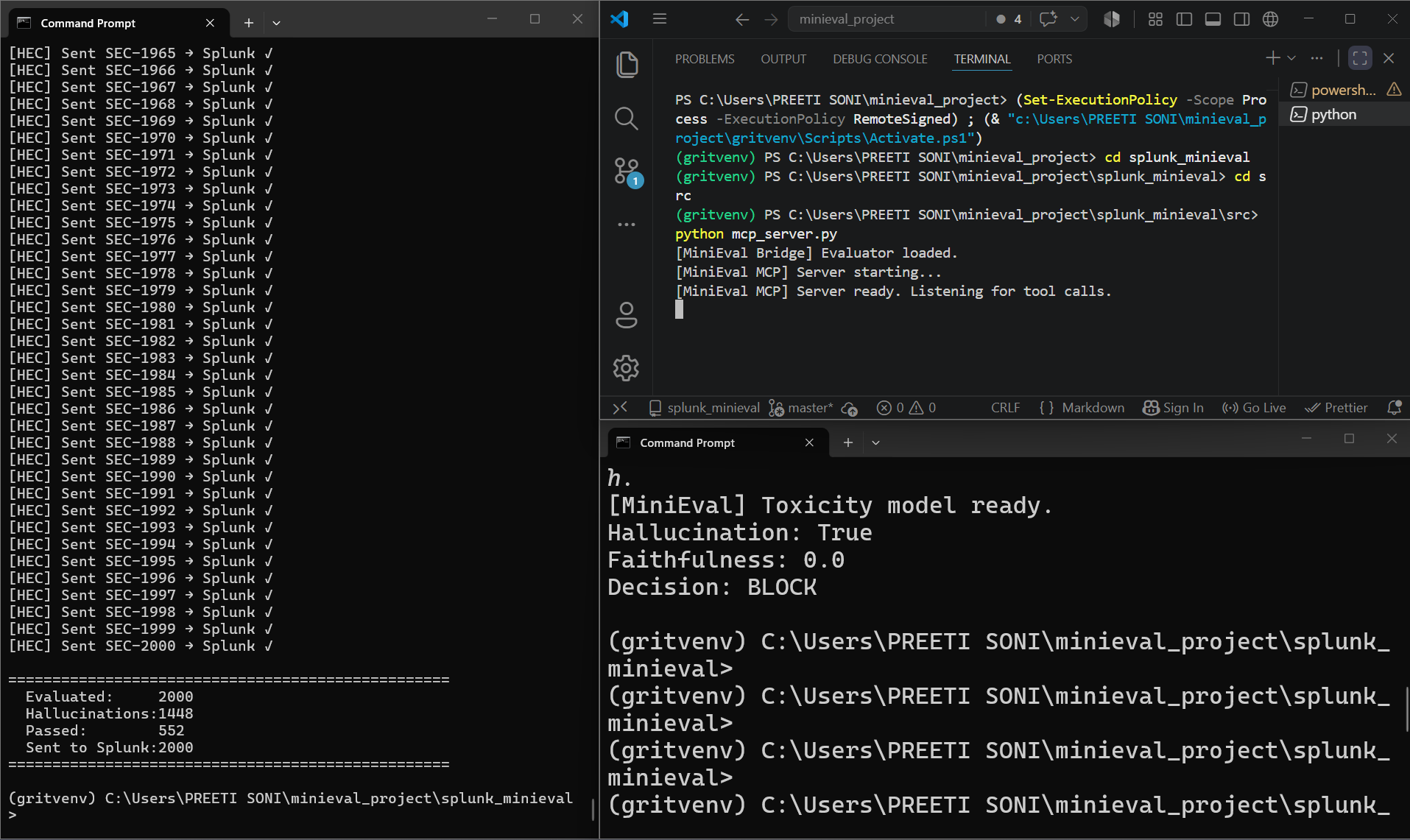
The MCP Server was brand new for me. I needed to first learn what the MCP is, then create a server, and finally, test the server. The "Decision: BLOCK - Auto-suppress" message that showed up in my terminal made all that work worthwhile.
Activation of Splunk AI Assistant took 4 days. Immediately after installing the assistant, I had to wait until an activation code became available. Once done, just saying "Show me hallucinations in the last 24 hours" to automatically see an SPL query generated looked like magic to me.
Debugging of Dashboard XML. All the broken closing tags made the whole dashboard fail. Learning the Splunk XML schema turned out to be really frustrating and time-consuming.
Data expiration. Within 24 hours, my dataset with 4,781 evaluations got cleared in Splunk. I had to execute the pipeline once again and use "All time" in time filters for screenshots.
Accomplishments that we're proud of
- 4,781 security alerts evaluated in a single test run
- 3,419 hallucinations caught - 72% hallucination rate detected
- 1,065 analyst hours saved - clear ROI for security teams
- $281 saved vs GPT-4 judge - 200x cheaper, proven with real numbers
- Auto-suppression policy - 1,541 alerts blocked, zero reached analysts
- SLO tracking - 30% target, 72% current, 240% error budget consumed
- Splunk AI integration - 'anomalydetection', 'predict', AI Assistant, MCP Server all working
- Enterprise-grade dashboard - 15+ panels showing real-time hallucination detection
- MCP Server - Splunk AI agents can call MiniEval as a tool
- PyPI package - 'pip install minieval-pro works
What we learned
The model itself accounts for only 20% of the answer. The other 80% concerns integrating it into Splunk using Splunk's AI functions. A simple machine learning model deployed and functioning is far better than a fancy one that remains in a notebook.
The AI powers of Splunk prove truly helpful. With 'anomalydetection', I was able to identify quality drops that would otherwise go undetected by me. predict revealed to me trends of hallucinations in the future. The AI Assistant helped me analyze data using queries without coding in SPL.
A hackathon is about creating a story. Beyond the coding itself. Numbers do count - 1,541 attacks detected, 1,065 hours saved, $281 savings. The judges need solid evidence.
Deployment is more challenging than development. Setting up HEC connection, preparing dashboard XML, debugging the MCP module - all of this takes time, but even more than writing the core of MiniEval.
What's next for MiniEval Pro -AI Hallucination Detection for Splunk Security
Near-term (next 20 days)
- Incorporate contextual retrieval metrics (Contextual Precision, Recall, Relevancy) for enhanced RAG troubleshooting
- Cloudify MiniEval Pro to provide easy accessibility to all teams
- Implement user authentication and API key requirements for safe access to services
Growth (3-6 months)
- Introduce pay tiers with pricing (Free, Pro, and Team options)
- Add Slack webhooks for notifying on SLO violations
- Implement a GitHub Action for CI/CD pipeline integration that halts deployments if hallucination rate is too high
Vision (6-12 months)
- Develop enterprise capabilities (SSO, compliance documentation, on-premises installation)
- Secure first enterprise customer
- Position MiniEval Pro as the go-to evaluation tool for Splunk
Every Splunk-generated alert from AI models needs to be evaluated for validity before reaching the analyst. This is what I want to build.


Log in or sign up for Devpost to join the conversation.