-
-
Main Page
-
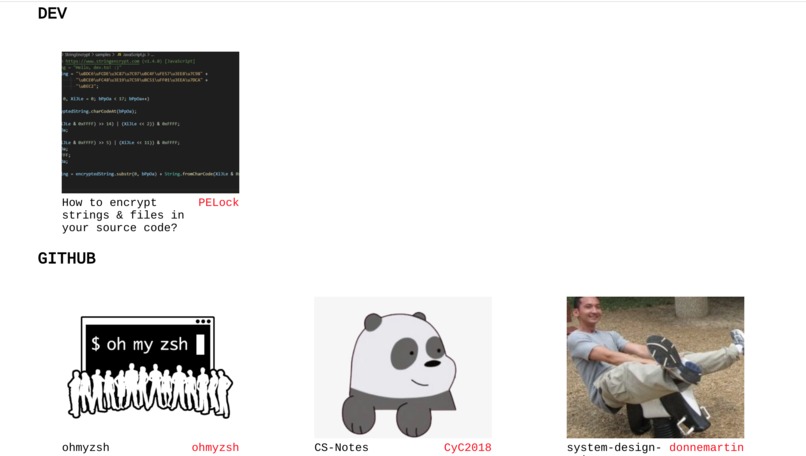
Example Search
-
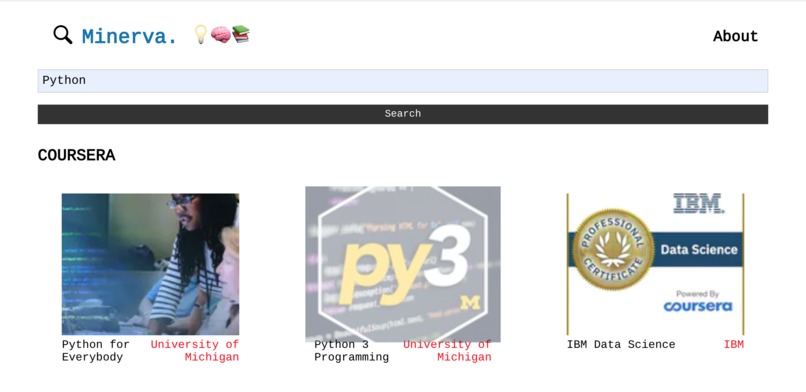
Example Search
-
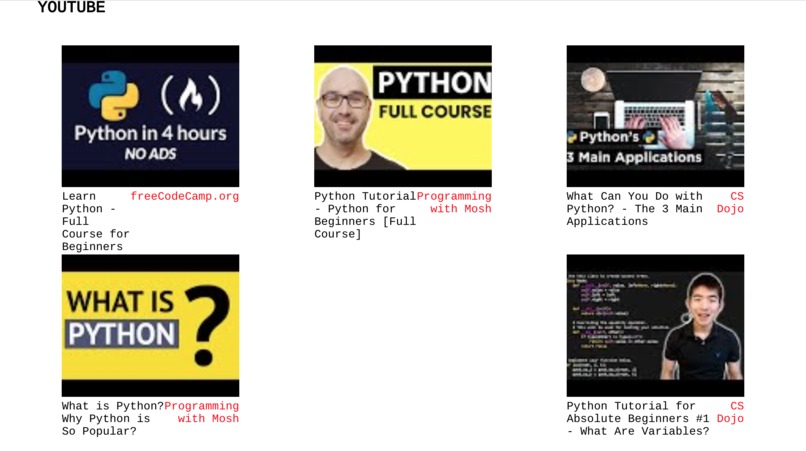
Example Search
-
Example Search
-

Example Search



What it does
We were inspired to build this since we feel that matching a curious mind to learning resources can be made more efficient.
We feel that there are a plethora of resources (MOOCs, Podcasts, Videos) out there that lack a centralized search engine to find the best content in line with the learner's needs. People around the world, especially students, are currently at home and are looking for ways to improve their skills! They try to take online courses for different skills but often end up confused - which one should I use? This website helps you by fetching tutorials + courses + books + more from different sources with the top content. This makes learning much easier and faster.
You can search for courses, videos, books, and codebase through our platform. We present all-encompassing learning resources for whatever you want to learn about!
Example resources: Coursera, Udemy, Github, Youtube, Libgen.
What We learned
We learned how to integrate selenium in python and how to deploy selenium apps on Heroku. We had a working knowledge of flask but scraping using selenium was something that made the task much easier. This project helped us learn how to combine web scraping with web applications to display content dynamically.
Integrating a React front with a Flask backend was also fun, and something we hadn't done before.
Inspiration
This product has been built by students who have gone through the challenges of doing an online course. While looking for a course, we often got confused by which website to follow. While looking for courses on Udemy, we overlooked the courses on other websites like Coursera and Edx. This product allows the student to avoid that problem by presenting data from all the different websites and helping them with their course search. We were inspired by websites like Trivago, Expedia, etc. that look up information from all the different hotel websites and presents the user with the best options.
We also allow you to diversify where you learn from!
How We built it
We started with BeautifulSoup and requests to scrape data from static websites. We set up a Flask application to handle these scraping requests. We setup a pipeline to get information from the backend and present it in the frontend. We then integrated Selenium with our application and scraped data from dynamic websites.
On the frontend, we used React components to make the webpages dynamic, reusable, and smooth. We then provisioned resources on Heroku and deployed the project in a container by using chromedriver and nginx plugins.
Challenges We ran into
We had some challenges in publishing the project to Heroku since we are using a chromedriver and didn't know about how to provision resources for that. We also had some problems when we were just using BeautifulSoup to scrape websites since most websites used JavaScript to render information. We started using Selenium to scrape dynamic websites and had to work on making the search faster by optimizing the algorithm.
What's Next
We hope to make the search faster and diverse. We also plan to expand this product to include more websites and work on similar products in the future! Another cool feature we want to go for is autocompleting in the search bar!
Note: The backend and frontend are two separate code bases. Links attached!





Log in or sign up for Devpost to join the conversation.