Here's each section written for a hackathon submission:
Inspiration Mental health care has a critical gap between sessions. A patient might see their therapist for one hour a week, but the other 167 hours are unmonitored. Therapists rely on patients self-reporting how their week went -- which is unreliable, filtered by recency bias, and misses early warning signs.
We saw three problems converging:
Patients need support between sessions but generic mental health chatbots give untethered advice that can contradict their therapist's approach Therapists have no visibility into how patients are doing day-to-day until the next appointment Clinical assessments like GAD-7 are filled out on paper, handed over, and manually interpreted -- a workflow that hasn't changed in decades We wanted to build something where the AI assistant is an extension of the therapist, not a replacement. Every response is grounded in materials the therapist chose. Every journal entry quietly feeds a monitoring system. And standardized assessments like GAD-7 can be submitted digitally with instant structured reports.
The final push came from the privacy angle: mental health data is the most sensitive data there is. We wanted to prove you can build a fully functional AI mental health platform where zero patient data leaves the machine -- local LLM, local vectors, local database.
What it does MindWell is a full-stack mental health platform with two roles:
For Patients:
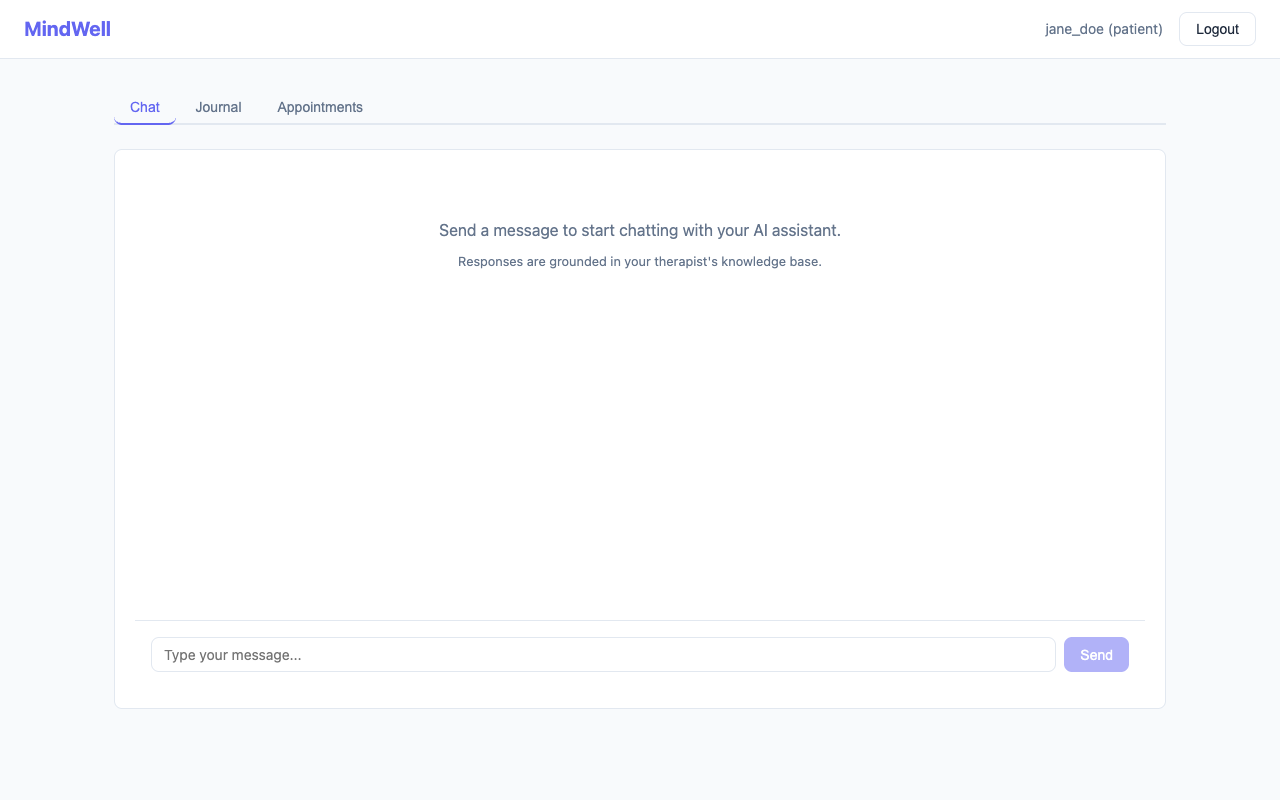
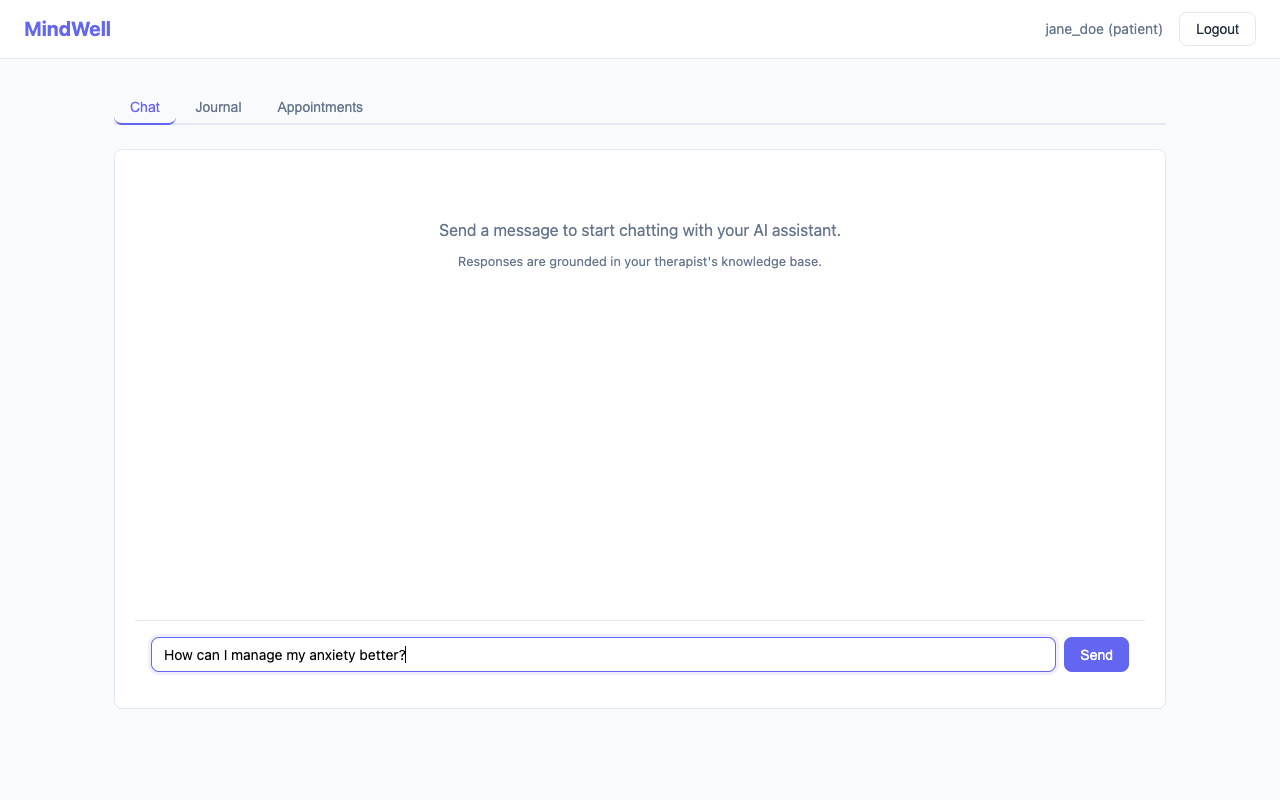
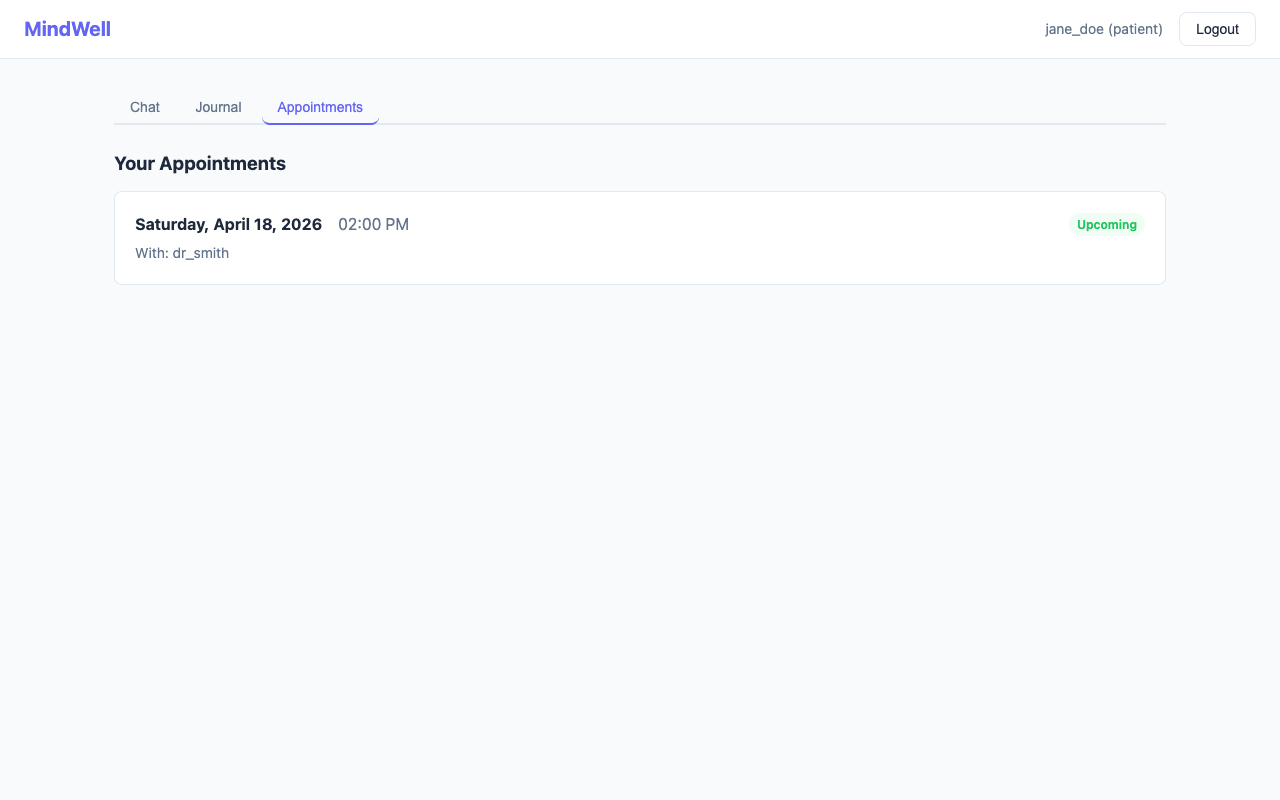
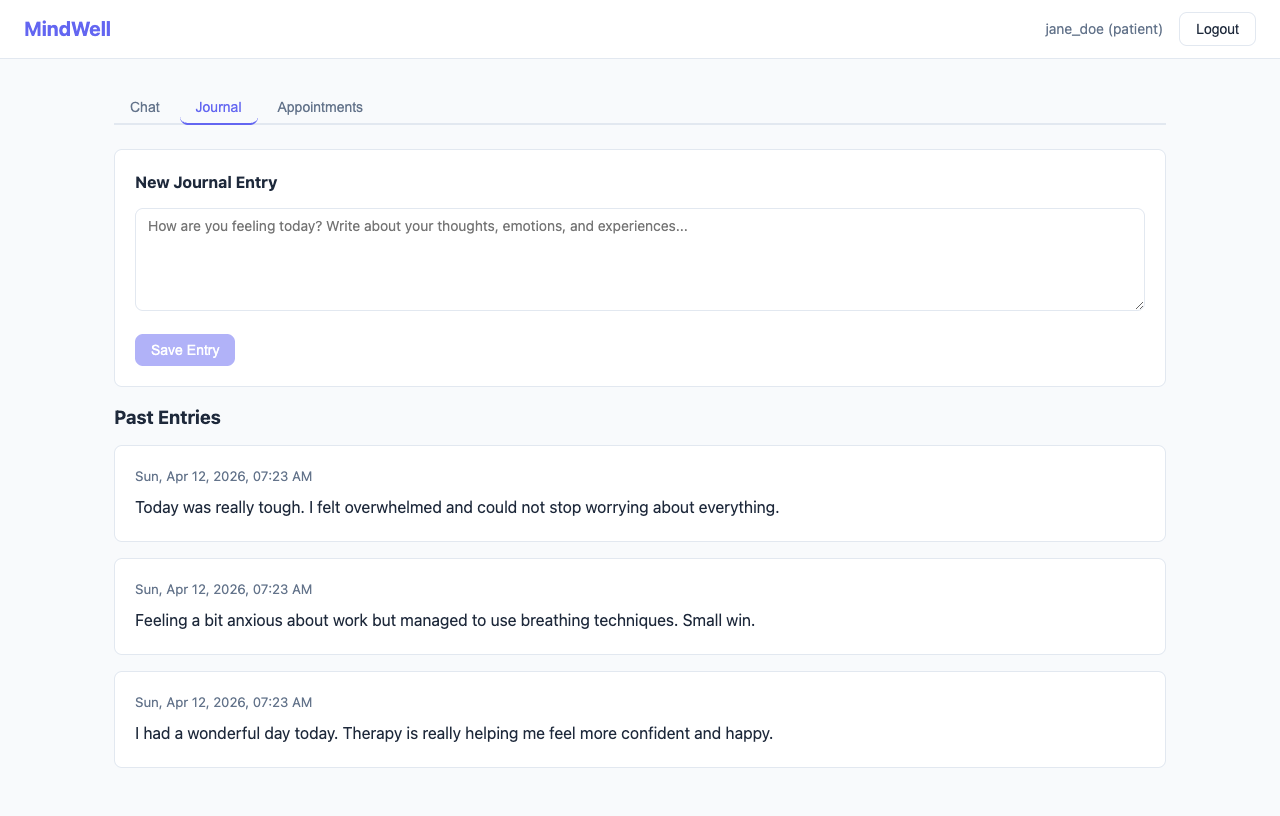
Chat with an AI assistant whose responses come exclusively from their therapist's curated knowledge base (CBT worksheets, coping strategies, clinical guides) -- not the open internet Write daily journal entries that are automatically sentiment-scored to track emotional trajectory Fill out GAD-7 anxiety assessments directly in the app, or upload a filled GAD-7 PDF that the AI parses automatically View upcoming appointments with their therapist For Therapists:
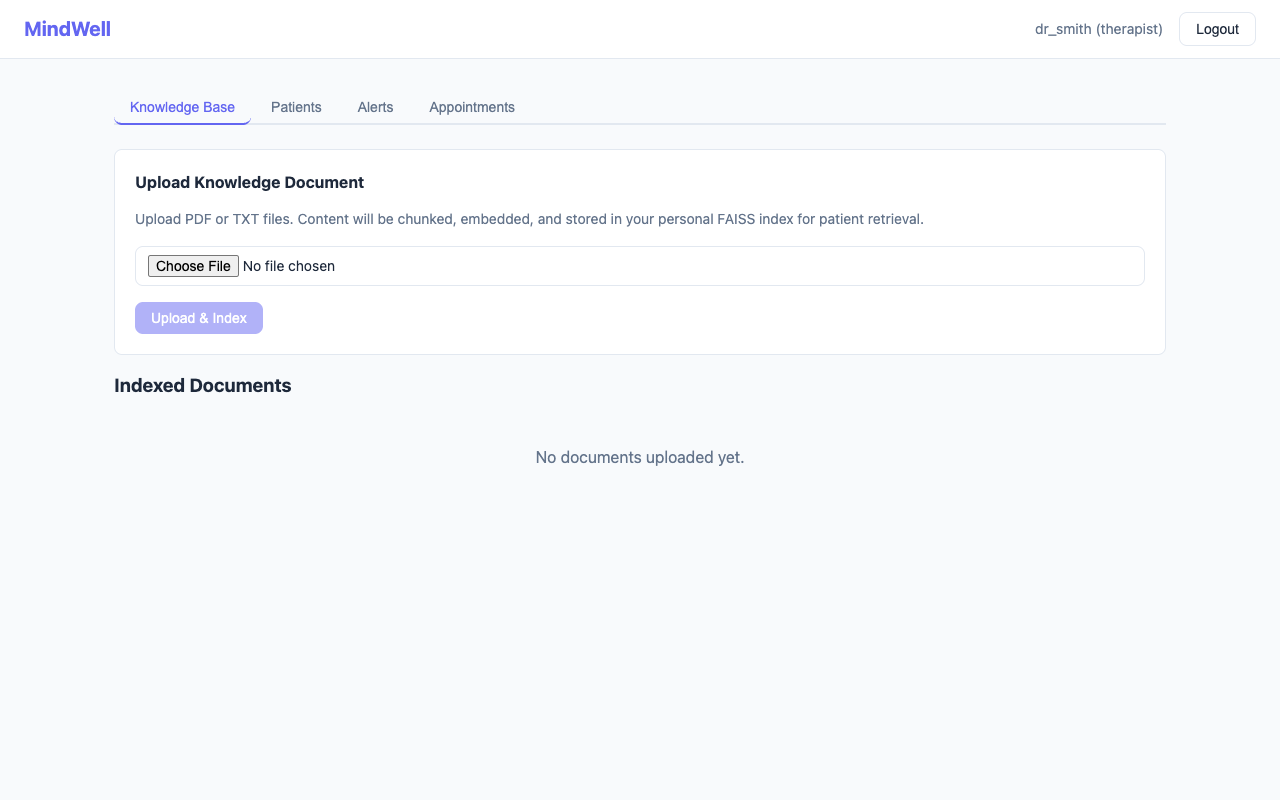
Upload PDF/TXT knowledge documents that get chunked, embedded, and stored in a personal FAISS vector index -- this becomes the foundation for their patients' AI chat Monitor patient sentiment trends via a 7-day rolling average with color-coded visualizations Receive automatic alerts when a patient's sentiment drops below a clinical threshold View structured GAD-7 reports with per-question breakdowns, severity classification (minimal/mild/moderate/severe), and trend tracking across assessments Schedule appointments with session notes (private to the therapist) Key design constraints we enforced:
Patients cannot see their own sentiment scores (prevents self-monitoring anxiety) Each therapist's knowledge base is fully isolated from others Appointment notes are therapist-only All AI responses cite their source chunks for transparency How we built it Architecture: Flask REST API backend, React 18 frontend, Mistral 7B running locally via Ollama, FAISS for vector search -- all connected through a clean service-layer architecture.
RAG Pipeline: When a patient sends a chat message, we embed it using sentence-transformers (all-MiniLM-L6-v2), search the therapist's personal FAISS index for the top-5 most relevant chunks via cosine similarity, inject them into a carefully designed empathetic system prompt, and stream the response from Mistral via Server-Sent Events. The prompt explicitly instructs the model to stay grounded in context, avoid hallucination, and recommend therapist escalation for serious concerns.
Sentiment Engine: Every journal entry runs through VADER (Valence Aware Dictionary and sEntiment Reasoner), producing a compound score from -1.0 to +1.0. We compute a 7-day rolling average per patient. If it drops below -0.2, the alert service flags that patient on the therapist's dashboard.
GAD-7 Processing: Patients can either fill out the standardized 7-question form in-app, or upload a filled PDF. For PDF uploads, we extract text via PyMuPDF, then send it to Mistral with a structured extraction prompt that returns the 7 scores as JSON. This means it works with any GAD-7 PDF format -- printed, handwritten-and-scanned, or digitally filled -- because the LLM interprets the content rather than relying on fixed field positions.
Auth: JWT-based with bcrypt password hashing and role-gated decorators (@token_required, @role_required) that keep patient and therapist routes cleanly separated.
Single-command launch: python main.py starts Ollama (if not running), the Flask backend, and the React dev server -- one terminal, one command.
Challenges we ran into FAISS index isolation was trickier than expected. Each therapist needs their own independent vector index, and those indexes need to persist across server restarts. We built a file-based system (one index.faiss + meta.pkl per therapist) with load/save helpers that handle the empty-index case gracefully. The metadata pickle stores the original chunk text and source filename alongside the vectors, so we can return sources with every RAG response.
Parsing arbitrary GAD-7 PDFs was a real challenge. GAD-7 forms come in dozens of layouts -- some have checkboxes, some have circled numbers, some are free-text. Rather than building brittle template-matching, we leaned into the LLM: extract the raw text from the PDF, send it to Mistral with a structured prompt, and ask for JSON output with the 7 scores. Getting the prompt right (so it returns clean JSON and handles edge cases like unclear answers) took significant iteration.
Flask's watchdog reloader caused an infinite restart loop. Creating the SQLite database and FAISS index directories at startup triggered file-change events, which restarted the server, which created the files again. We had to disable the reloader and build a custom launcher instead.
Port 5000 conflicts on macOS -- Apple's AirPlay Receiver silently occupies port 5000. Debugging "connection refused" on a freshly written server that you know is correct is a special kind of frustration.
Streaming responses through the full stack -- getting SSE (Server-Sent Events) working from Ollama through Flask through fetch() in the React client, with proper chunked parsing and real-time UI updates, required careful handling at each layer.
Accomplishments that we're proud of The entire system runs locally with zero external API calls. No OpenAI, no cloud services, no data leaving the machine. Mistral 7B handles both the chat responses and the GAD-7 PDF parsing. For a mental health application, this isn't a nice-to-have -- it's a fundamental requirement.
The RAG pipeline actually works well. Responses are genuinely grounded in the therapist's uploaded materials. The source citations let patients verify where guidance is coming from, and the empathetic prompt design produces responses that feel supportive rather than clinical.
GAD-7 PDF parsing via LLM is a genuinely novel approach. Instead of building a fragile form-field extractor, we use the LLM as a flexible parser that handles any PDF layout. This could generalize to PHQ-9, DASS-21, or any standardized assessment.
The alert system catches real patterns. Sentiment scoring individual journal entries is noisy, but the 7-day rolling average smooths it into a clinically useful signal. A therapist can see a patient trending downward days before their next session.
Clean architecture throughout. The backend has proper separation -- models, routes, services, utils. No business logic in route handlers. The frontend uses proper component composition with role-based routing. The codebase is something you could hand to another developer and they'd understand immediately.
What we learned LLMs as structured data extractors are surprisingly effective. Using Mistral to parse GAD-7 PDFs into structured JSON was more reliable than we expected and far more flexible than template-based approaches. The key is constraining the output format tightly in the prompt.
Sentiment analysis has real limits. VADER is fast and works well for clearly emotional text, but therapy journal entries are often nuanced. "I managed to get through the day" could be positive (resilience) or negative (barely surviving) depending on context. We learned that VADER is a useful first pass, but a production system would need clinical-grade NLP.
Local LLM inference is production-viable now. Ollama makes running Mistral 7B trivially easy. Response quality is strong enough for a support assistant (not diagnosis), and streaming makes the UX feel responsive despite running on local hardware.
Privacy-first architecture changes design decisions. When you commit to keeping everything local, you can't reach for cloud vector databases, hosted embeddings APIs, or managed auth services. Every component has to have a local equivalent. This constraint actually produced a cleaner, more self-contained system.
Role-based systems need careful information barriers. Deciding what patients can and cannot see (no sentiment scores, no appointment notes, no access to other therapists' knowledge bases) required deliberate design at every layer -- API routes, database queries, and frontend rendering.
What's next for MindWell Conversation memory -- Currently each chat message is stateless. Adding sliding-window conversation history to the RAG prompt would make multi-turn dialogue feel natural rather than each message starting from scratch.
More clinical assessments -- The GAD-7 infrastructure (LLM-based PDF parsing + in-app form + therapist reports) generalizes directly to PHQ-9 (depression), DASS-21 (depression/anxiety/stress), and PCL-5 (PTSD). We'd build a pluggable assessment framework.
Crisis detection model -- Replace keyword-based crisis detection with a trained classifier that catches implicit risk signals ("I don't see the point anymore" rather than just explicit self-harm language).
Therapist co-pilot -- An AI-powered view for therapists that summarizes a patient's journal entries since the last session, suggests topics to discuss, and highlights the most concerning sentiment shifts.
Hybrid search -- Combine FAISS vector search with BM25 keyword matching via rank fusion. Pure semantic search misses exact medical terminology; hybrid search handles both "what is CBT" and "I feel lost and don't know what to do."
HIPAA-ready encryption -- At-rest encryption for the SQLite database and FAISS indexes, plus audit logging for all data access, to meet technical safeguard requirements for actual clinical deployment.
Mobile PWA -- A Progressive Web App with push notifications for appointment reminders and journal prompts would dramatically increase patient engagement compared to a desktop-only interface.

Log in or sign up for Devpost to join the conversation.