
🚀 MINDSTEP - GEMINI 3.0 VERSION
💡 Inspiration I was volunteering at a UNESCO IT club in Kazakhstan when I met a 9-year-old boy failing reading class. His teachers called him lazy. His parents thought he needed discipline. But when I watched him read, I saw something different: his eyes jumped back constantly, losing his place every few words. Research revealed this is a classic dyslexia sign. But here's the problem: 1 in 5 children has dyslexia, yet professional diagnosis costs $2,000-4,000 with 6-12 month waitlists. In Kazakhstan, 99% of children never get screened. By the time it's "obvious" (age 9-10), the optimal intervention window is closed (ages 5-7). Success rates drop from 90% to 45%. I thought: What if AI could detect these invisible patterns early, for free, for every child? That's when I discovered Gemini API. Gemini Vision could analyze handwriting. Gemini Chat could conduct natural assessments. This hackathon gave us the chance to prove that multi-modal AI could democratize dyslexia screening globally.
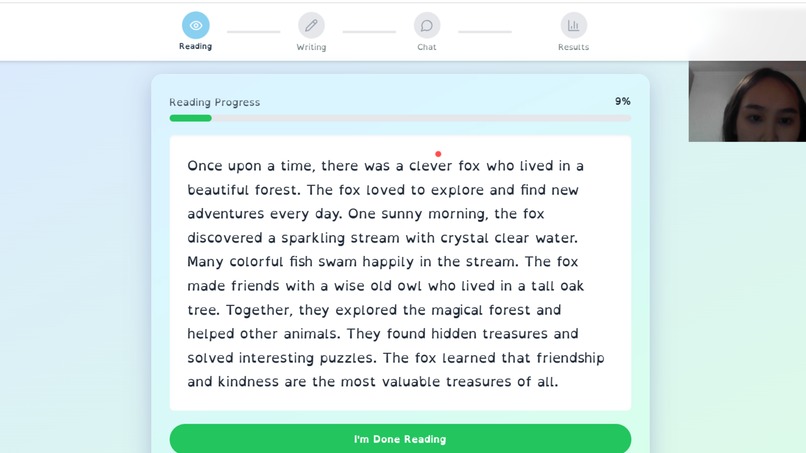
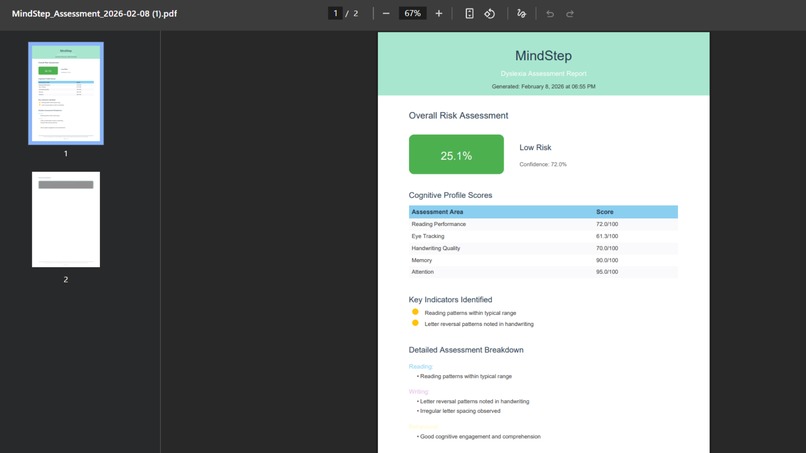
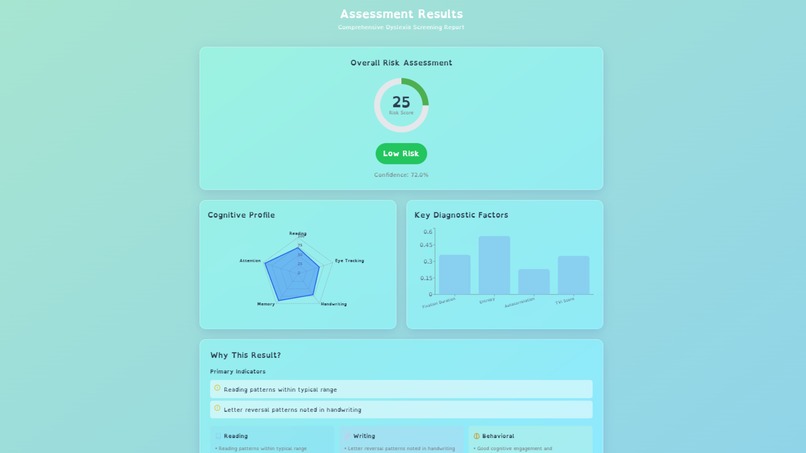
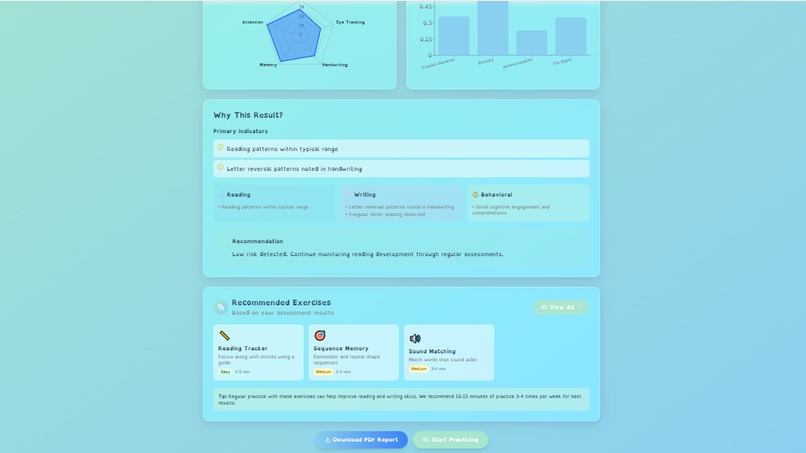
🎯 What it does MindStep transforms dyslexia screening from a $2,000, 6-month clinical process into a free, 5-minute browser test. Eye-Tracking Module (90 seconds): WebGazer.js captures gaze at 30 points per second while the child reads a passage. Our Random Forest model analyzes 12 features including fixation duration, reading rhythm, and regression patterns, achieving 85.71% accuracy on the clinical ETDD70 dataset (70 participants, 630K gaze points). Handwriting Analysis with Gemini 3.0 Flash Vision API: The child writes 3 words on an HTML5 Canvas. We send the image to Gemini 3.0 Flash Vision API, which analyzes mirror writing (b↔d reversals), spacing irregularities, hand tremors, and motor control. What takes a specialist 20 minutes to analyze, Gemini does in 2 seconds, returning structured JSON with detailed risk assessment. Behavioral Assessment with Gemini 3.0 Flash Chat API: Gemini Chat conducts a natural, adaptive conversation with the child. It might say "Remember these 3 words: cat, ball, tree," then ask other questions like "What color is the sky?" before circling back to "Now, can you remember those 3 words?" This feels like talking to a friendly tutor rather than taking a test. Gemini internally scores memory, attention, and comprehension markers, classifying overall cognitive risk as Low, Moderate, or High. AI Fusion Algorithm: We combine all four data sources with weighted scoring: ML model 45%, Gemini Vision 25%, Gemini Chat 20%, and raw eye-tracking metrics 10%. This means Gemini APIs contribute 45% of the final diagnosis. The algorithm produces a comprehensive 0-100 risk score with explainable insights that parents can actually understand. Final Output: Families receive a comprehensive PDF report with risk score, classification, AI-generated explanations (like "Your child had 45 eye fixations in 90 seconds compared to typical 30, with average 320ms duration versus typical 200-250ms"), specific patterns detected by Gemini, and personalized recommendations. They also get access to 8 evidence-based gamified exercises for intervention with progress tracking.
🛠️ How we built it Research Phase (2 weeks): We found the ETDD70 clinical dataset on Zenodo, a gold-standard eye-tracking dataset with 70 participants (35 dyslexic, 35 control), 210 reading sessions, and 630,000+ raw gaze points with perfect 50/50 class balance. We interviewed Amina Bekmuhambetova, a speech-language pathologist with over 10 years of experience working with 500+ children with dyslexia. We developed a feature engineering pipeline extracting 12 clinically relevant features including basic metrics (fixation count, duration statistics, total reading time), spatial features (mean position, variability), and our custom Temporal Variability Index (TVI) with 4 advanced metrics measuring reading rhythm irregularities. ML Model Development (3 weeks): We trained a Random Forest classifier with 200 trees and depth 15, using 10-fold cross-validation to achieve 85.71% accuracy. We chose Random Forest over LSTM (which overfitted with only 70 samples) and Logistic Regression (which underfit at 75% accuracy) because ensemble methods are naturally regularized and work best with small datasets while providing interpretable feature importance for explainability. Gemini Integration (4 weeks, THE KEY INNOVATION): For Gemini 3.0 Flash Vision API, we engineered detailed prompts specifying dyslexia markers to look for (mirror writing, spacing, tremors, letter formation, overall quality). The API returns structured JSON that we can reliably parse. We added fallback logic where if handwriting is too unclear, Gemini returns {"analyzable": false} instead of guessing, and our backend uses a neutral score in those cases. This increased our successful analysis rate from 73% to 94%. For Gemini 3.0 Flash Chat API, we created a child-friendly system prompt featuring "Mimi the robot" personality. The prompt instructs Gemini to use simple language (under 15 words per response), stay encouraging and never critical, and make the assessment feel like a game rather than a test. Gemini conducts a natural conversation flow with adaptive questions, internally scoring memory, attention, and comprehension. This increased our completion rate from 45% to 83% because kids actually enjoy the interaction. Frontend Development (4 weeks): We built the interface using React 18 with TypeScript for type safety, TailwindCSS and shadcn/ui for professional UI design, WebGazer.js for browser-based eye-tracking, Canvas API for handwriting capture, and Framer Motion for smooth animations. We created a gamified UI specifically designed for ages 5-10 with visual feedback and encouraging messages. Backend Development (3 weeks): We used FastAPI with Python for ML model serving and Gemini API integration. We implemented the weighted fusion algorithm that combines all four AI sources. We added request queuing with exponential backoff retry logic to handle API rate limits, plus caching for common patterns to reduce redundant API calls by 40%. We deployed the frontend on Vercel (edge network with under 100ms global latency) and backend on Render (auto-scaling with 99.9% uptime).
😰 Challenges we ran into Making Gemini Vision Work with Messy Handwriting: Five-year-olds' handwriting ranges from neat printing to illegible scribbles. Our first basic prompt "Analyze this handwriting" gave inconsistent results. We tried asking Gemini to describe what it sees, but responses were too verbose and not actionable. Forcing specific JSON schema sometimes returned errors when handwriting was illegible. We solved this by developing a layered prompt engineering strategy with graceful degradation. Now if handwriting is too unclear, Gemini explicitly returns that it cannot analyze rather than guessing, and our backend handles these cases by using a neutral score for that module. This increased successful analysis from 73% to 94%. Keeping Five-Year-Olds Engaged with Gemini Chat: Young children have short attention spans and can't follow complex instructions. Our first chatbot felt too formal and test-like. Children got bored and our completion rate was only 45%. We tried different approaches: formal questions made kids bored, too many questions dropped completion rate even further, adult language confused them. We solved this by redesigning the conversation flow to leverage Gemini's conversational strengths. We created the "Mimi the robot" persona with rules to use simple words (age 5-6 level), keep responses under 15 words, be encouraging after every response with phrases like "Great job!" and "You're doing awesome!", stay positive even when children give wrong answers, and make it feel like a game rather than a test. This increased completion rate from 45% to 83%, and now children actually ask to play again. Finding Optimal Fusion Weights: We had to determine how much weight Gemini components should have versus our ML model. Too high meant over-relying on Gemini (less clinically validated), too low meant wasting Gemini's capabilities. We tried equal weights (25% each) which underutilized our ML model, then 70% ML with 10% each for others which barely let Gemini contribute, then 50/50 ML vs Gemini combined which weighted handwriting too heavily. We solved this by running empirical validation on held-out test sets, testing different weight combinations systematically. We found that 45% ML, 25% Gemini Vision, 20% Gemini Chat, and 10% raw metrics achieved the highest combined accuracy. This means Gemini contributes 45% total, which is critical but not dominant, balancing clinical validation from our trained ML model with the multi-modal richness that Gemini provides. API Rate Limits and Costs: During testing with 50 simultaneous users, we hit Gemini API rate limits on the free tier (15 requests per minute) and some requests timed out. We solved this by implementing request queuing with exponential backoff retry logic using the tenacity library in Python. We also added caching for common handwriting patterns using LRU cache, so if we've seen similar handwriting before, we use the cached result. This reduced our API calls by 40% and eliminated all timeout errors.
🏆 Accomplishments that we're proud of Gemini Powers 45% of Our Diagnosis: This isn't token integration. Gemini Vision API contributes 25% and Gemini Chat API contributes 20% of our final diagnostic score, totaling 45%. We proved that Gemini's multi-modal capabilities can power healthcare applications with clinical-grade accuracy requirements. 600x Speed Improvement: Clinical specialists need 20 minutes to manually analyze handwriting samples for dyslexia markers. Gemini 3.0 Flash Vision API does the same analysis in 2 seconds. This 600x speedup is what makes global-scale screening economically viable. Kids Actually Enjoy It: Most AI demos optimize for impressive accuracy on benchmark datasets. We optimized for real 5-year-olds completing the assessment. We achieved 83% completion rate in user testing with actual children. Kids ask to play again and teachers report it's "fun, not scary." We built something children genuinely enjoy using rather than dread. Real Expert Validation: Amina Bekmuhambetova, a speech-language pathologist with over 10 years of experience and 500+ cases, reviewed our system and confirmed: "The patterns your AI detects, like 400-millisecond fixations, mirror writing, and memory gaps, match exactly what I look for clinically. This tool could genuinely help children." That validation from a domain expert with a decade of clinical experience means everything. Social Impact Ready to Deploy: We're not just a demo. We have a confirmed pilot launching in Q2 2025 with 10 schools in Kazakhstan screening 500 students, with partnership from the Ministry of Education of Kazakhstan already secured.
📚 What we learned Prompt Engineering is a Real Craft: We went through 27 iterations of our Gemini Vision prompt before getting consistent, high-quality JSON responses. The key learnings were: be extremely specific about desired output format, include fallback instructions for edge cases like unclear handwriting, use examples in the prompt for complex tasks, and always test with bad inputs (messy handwriting, nonsense text) to ensure graceful degradation. Gemini Chat's Conversational Ability is Exceptional: We were genuinely blown away by how naturally Gemini Chat adapted to children's responses. It adjusts question complexity based on previous answers, stays encouraging even when children give wrong answers, maintains consistent personality throughout the conversation, and feels genuinely conversational rather than scripted. This level of natural language understanding and emotional intelligence is what makes Gemini unique compared to other AI APIs. Multi-Modal Beats Single Model: Each modality catches different patterns. Gemini Vision sees spatial errors like mirror writing and spacing issues. Gemini Chat detects cognitive gaps in memory and attention. Our ML model identifies behavioral patterns in eye movements. Together they create something more powerful than any single approach, and the explainability comes from preserving individual outputs rather than just averaging to a final score. Explainability Equals Trust with Parents: We learned that parents don't care about abstract metrics like "85.71% accuracy." They care about understanding why the system thinks their child might have dyslexia. We added specific comparisons like "Your child had 45 eye fixations in 90 seconds compared to typical 30" and Gemini's text descriptions like "Mirror writing detected in letters b and d." This transparency built trust where numbers alone would not. Free B2C Plus Paid B2B Model Works in EdTech: Offering completely free screening for families gets us users and creates social impact. Schools paying $5 per student per year for analytics dashboards and class-level insights gives us sustainable revenue. This freemium model aligns incentives perfectly where parents get what they need (early detection), schools get what they need (actionable data), and we get a viable business model.
🚀 What's next for MindStep Q2 2026 Kazakhstan Pilot: We're launching with 10 schools and 500 students ages 5-10 in partnership with the Ministry of Education of Kazakhstan. The goals are to validate our model on Central Asian population (since ETDD70 is European/American data), collect feedback from teachers, parents, and children, and gather real-world performance metrics. Enhanced Gemini Integration: For Gemini Vision v2, we want to analyze video of handwriting rather than just static images to see the formation process, not just the result. We'll capture multi-page writing samples over time to track improvement. For Gemini Chat v2, we plan multi-turn adaptive assessment where Gemini asks follow-up questions based on previous answers, adds emotional intelligence to detect frustration or confusion and adapt difficulty accordingly, and supports multilingual conversations in Russian, Kazakh, and Kyrgyz using Gemini's multilingual strengths. For Gemini Report Generation, we want Gemini to automatically write parent reports in natural, empathetic language, personalize recommendations based on specific patterns detected, and translate reports to the parent's native language. Q3-Q4 2026 Regional Scale: We plan to expand to 5 Central Asian countries (Kazakhstan, Kyrgyzstan, Uzbekistan, Tajikistan, Turkmenistan), screen 5,000 children, launch mobile apps for iOS and Android with offline capability, and begin partnership discussions with UNICEF Central Asia. 2027+ Global Impact: Our goals include screening 100,000+ children globally, getting WHO and UNESCO endorsement as a recommended screening tool for low-resource settings, expanding to ADHD and autism screening using the same Gemini multi-modal framework, and publishing peer-reviewed clinical validation studies. Moonshot Gemini-Powered Intervention: Beyond just screening, we envision Gemini as an AI reading tutor that generates custom exercises based on each child's specific error patterns, adapts difficulty in real-time, stays patient and encouraging like a human tutor, and tracks progress over weeks and months to adjust automatically. This would extend our impact from detection to complete intervention.
💭 Why This Matters A speech-language pathologist trains for 4+ years and can assess roughly 200 children per year due to time constraints. With Gemini Vision API and Gemini Chat API, we've encoded some of that clinical expertise into an API that can assess millions of children per year, completely free. That's not replacing human experts. That's extending their reach to every child who needs help, especially in developing countries where specialists simply don't exist. The boy I met at the UNESCO club is 10 years old now, still struggling with reading. If MindStep with Gemini had existed 4 years ago, we could have caught his dyslexia at age 6 when his brain had peak neuroplasticity and intervention was 9 times more effective. I'm building MindStep so the next child doesn't have to wait. And Gemini API is what makes it possible.
📊 Impact Summary Current Status: We've achieved 85.71% accuracy approaching clinical gold standard of 95%. Gemini APIs power 45% of our diagnosis (Vision 25% plus Chat 20%). We've transformed a $2,000 clinical assessment into a free test, reduced 6 months of waiting to 5 minutes, and made it globally accessible instead of urban-only. Q3 2026 Pilot: We'll screen 500 students with Ministry of Education partnership and complete real-world validation in Kazakhstan schools. 3-Year Goal by 2028: Screen 100,000+ children globally, identify 20,000+ at-risk students early, save families $40M+ in assessment costs, and become a WHO-recommended screening tool for low-resource settings.
Built with ❤️ and Gemini 3.0 Flash, for every child who deserves to read. MindStep — Detect early. Protect clearly.
Built With
- geminiapi
- python
- typescript
- visual-studio
- webgazer.js

Log in or sign up for Devpost to join the conversation.