Inspiration
EmotiFlow (and its sibling name MindPulse) was born from a simple observation: people spend a large fraction of their day interacting with web applications and communication tools, yet there are few lightweight, privacy‑respecting ways to notice and respond to emotional states in those everyday moments. We were inspired by brief, evidence‑based micro‑interventions from psychology (e.g., controlled breathing, grounding exercises) and by the growing maturity of on‑device sensing: low‑latency NLP, simple acoustic analysis, and compact facial pose/expression models. The combination suggested a practical product idea: a browser‑based agent that unobtrusively senses multimodal signals, reasons locally when possible, and offers short, context‑appropriate wellness prompts without collecting or exposing raw personal data. The project also drew inspiration from the need for reproducible, demonstrable behavior during live demos—hence deterministic fallbacks and offline‑first designs—so the system remains useful and safe even when network APIs are unavailable or the user declines cloud services.[1]
What it does
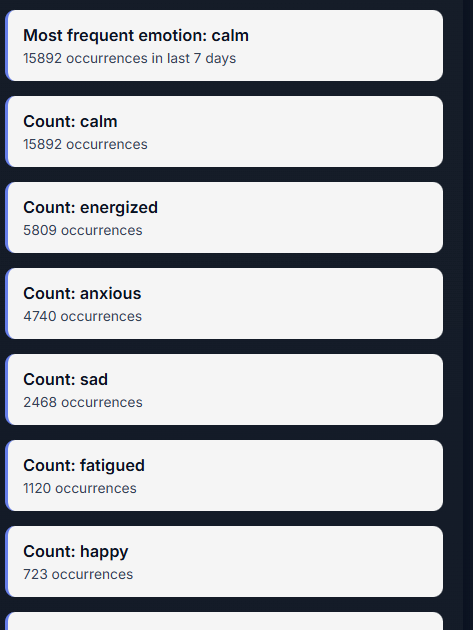
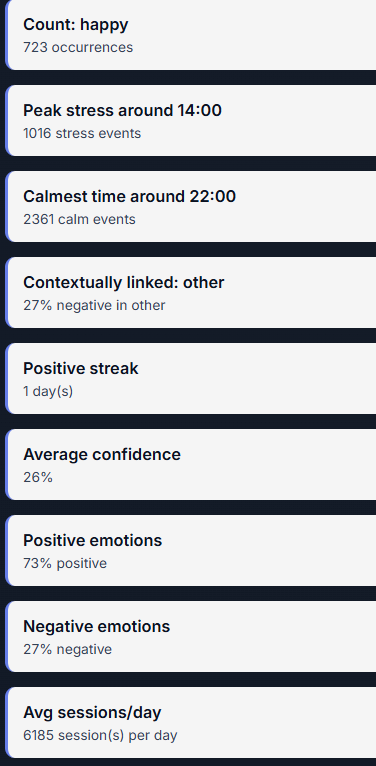
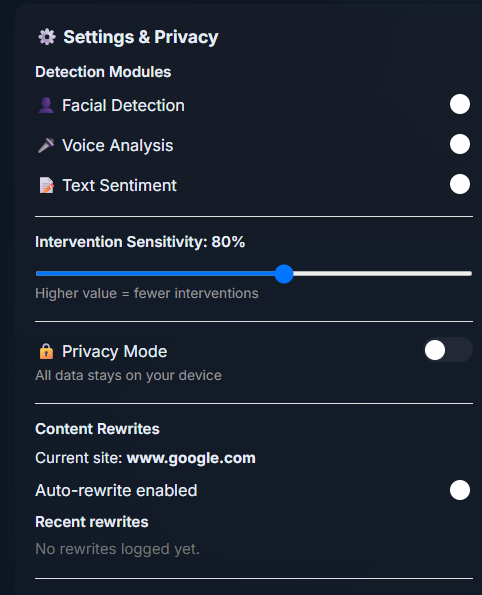
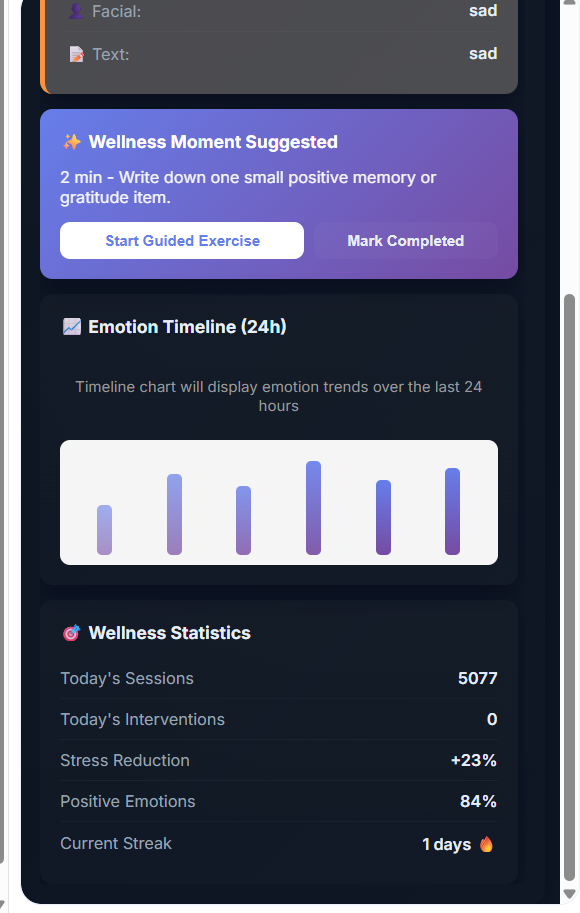
EmotiFlow is a compact browser extension that continuously (and with user consent) listens for signals from three complementary channels: text typed by the user, brief voice samples, and optional face cues from a small, draggable camera overlay. It converts each signal into a lightweight emotion estimate (label + confidence) and combines them using a calibrated fusion engine to produce a single, robust EmotionState. When the fused state crosses defined thresholds or when modalities agree, EmotiFlow surfaces short, actionable wellness suggestions—breathing exercises, grounding prompts, quick stretches, or content‑focused actions like rewriting a negative sentence. The sidepanel shows current emotion, confidence, a recent timeline, and wellness stats, with local‑first operation and optional, explicit‑consent cloud refinement.[1]
How we built it
Architecture and components
- Modular MV3 extension: content scripts capture signals; a background service worker performs fusion, timing, and storage; a React sidepanel handles UI and interaction, isolating sensing, decision logic, and presentation.[1]
- Multimodal content scripts:
- textSentiment: clause‑aware, negation‑handling classifier on focused inputs emitting fine‑grained sentiment events.[1]
- voiceAnalysis: short‑time audio frames → energy and pitch features → tone + intensity score.[1]
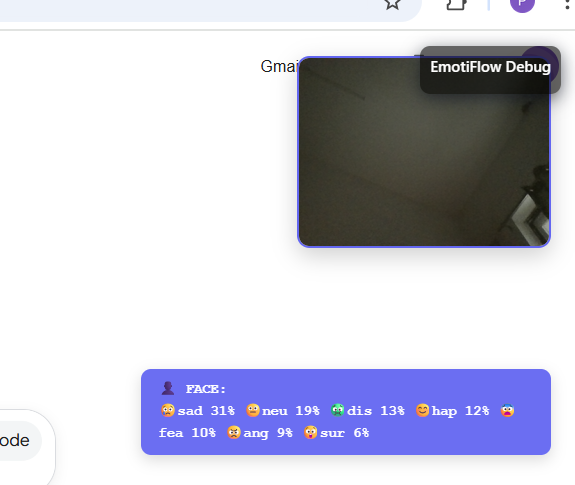
- facialDetection: small draggable overlay; on opt‑in, dynamically imports face‑API and reports expressions + confidence.[1]
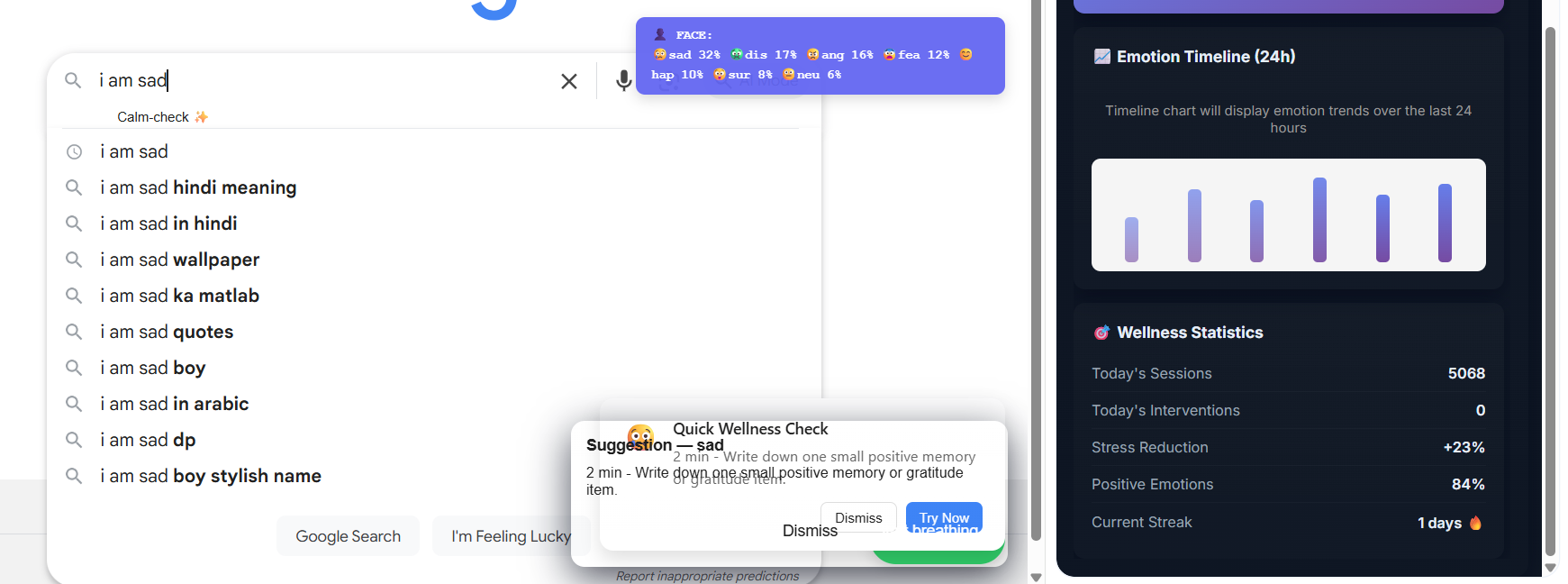
- Fusion engine: decision‑level fusion with default weights (face 0.4, voice 0.35, text 0.25), temporal smoothing (5s window), similarity thresholds, and per‑user baseline calibration.[1]
- Suggestions pipeline: immediate heuristic suggestions for low latency, and asynchronous AI‑refined suggestions only with explicit consent; deterministic template fallback and IndexedDB caching for offline reliability.[1]
- Safety & resilience: sendMessageSafe wrapper around MV3 restarts, guarded init and permission flows, and clear UI status reporting.[1]
Development process
Iterative cycles: identify failing cases (e.g., negation), add targeted rules, expand unit harnesses, and hot‑rebuild in the extension; emphasized negation/fusion harnesses and a CDN‑fallback model downloader for offline demos.[1]
Challenges we ran into
Technical challenges
- Negation & clause complexity: naive token lists misclassified “I am not happy” and contrastive sentences; combined clause segmentation, windowed negation scope, and contrast weighting with extensive tests.[1]
- MV3 service worker lifecycle: restarts produced intermittent messaging errors; built a safe messaging wrapper, acknowledgments, and retry logic without noticeable UI latency.[1]
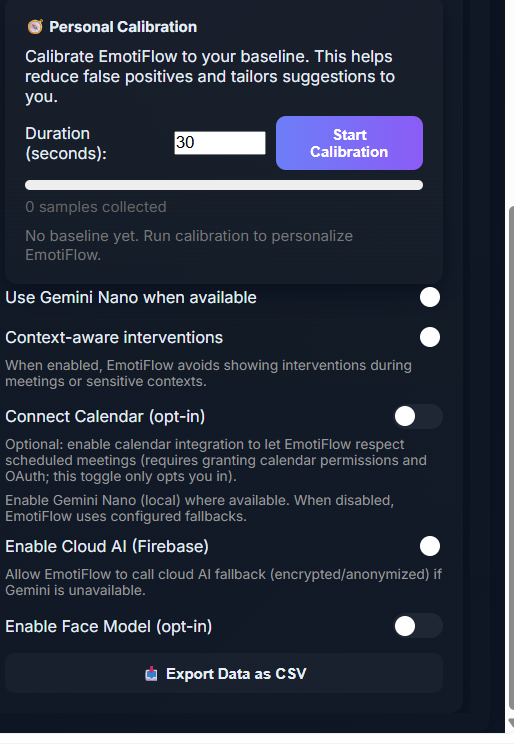
- Privacy vs quality: cloud LLMs improve phrasing but raw media is unacceptable by default; hybrid design keeps local processing and uses consented, text‑level cloud calls only.[1]
- Resource constraints: bundle size control with dynamic imports, external model downloader, and UX guardrails against heavy defaults.[1]
- UX timing: non‑intrusive interventions via heuristics, cooldowns, and meeting suppression.[1]
Operational and testing challenges
- Multimodal aligned datasets are scarce; used synthetic/semi‑synthetic fusion scenarios and public corpora for controlled tests.[1]
- Determinism vs personalization: maintained parallel code paths (deterministic vs AI) and verified cache semantics for predictable demos.[1]
Accomplishments that we’re proud of
Technical achievements
- Negation robustness: clause segmentation + scope heuristics + compact classifier reduced negated‑positive false positives in text‑dominant scenarios.[1]
- Deterministic offline fallback: template generator + IndexedDB caching preserves useful behavior when cloud is unavailable or disabled.[1]
- Opt‑in face model with downloader: local storage of face‑API weights with CDN fallback, keeping default install lightweight.[1]
- Robust messaging & errors: sendMessageSafe, guarded initializers, and improved DOMException logging stabilized runtime behavior.[1]
- UX polish: draggable overlay, feedback‑ready InterventionCard, and WellnessStats for transparent control.[1]
Project and process wins
- Reproducible test harnesses for negation/fusion with measurable improvements.[1]
- Build configuration for rapid iteration and offline demo reproducibility.[1]
- Practical balance of privacy, accuracy, and usability with opt‑in enhancements.[1]
What we learned
On technical trade‑offs
- Targeted heuristics + small models can beat monoliths on specific failure modes (e.g., negation) under browser latency/size constraints.[1]
- Hybrid local‑deterministic + optional cloud AI delivers robust demos while enabling higher quality for opted‑in users; clear tier contracts are key.[1]
On user experience
- Users prefer brief, actionable suggestions; cooldowns, per‑site opt‑outs, and meeting suppression increase acceptance.[1]
- Transparency and explicit opt‑ins are essential for camera/microphone usage.[1]
On engineering and operations
- MV3 lifecycle idiosyncrasies demand resilient messaging and background logic with restart simulation and safe wrappers.[1]
- Compact, repeatable harnesses speed iteration and reduce regressions in nuanced NLP.[1]
What’s next for MindPulse and EmotiFlow
Short‑term (next sprint)
- Complete safe‑messaging sweep with optional exponential backoff for critical UI messages.[1]
- Expand multilingual/colloquial negation tests and retune weights.[1]
- Add “last suggestion timestamp” and a lightweight audit log UI with inline feedback.[1]
Medium‑term (next release)
- Personalization without raw uploads: local calibration and optional federated aggregation.[1]
- Small quantized transformer for richer local text understanding under size budgets.[1]
- Better multimodal alignment via consented, in‑browser experiment harness.[1]
Long‑term (research/product roadmap)
- Lightweight joint multimodal models for subtle states with on‑device quantization and privacy‑preserving training.[1]
- Federated calibration and opt‑in community models with differential privacy.[1]
- Clinical/longitudinal studies for measurable stress and wellbeing outcomes.[1]
- Marketplace and ecosystem for vetted intervention packs and clinician content.[1]
Overview
Purpose
EmotiFlow detects emotional states from text, voice, and optional facial signals, fuses them into one EmotionState, and delivers short, context‑aware wellness suggestions and UI adaptations—defaulting to deterministic, privacy‑first, offline‑ready behavior with optional consented cloud refinement.[1]
Audience
End users, demoers, researchers, and developers extending multimodal emotion‑aware interventions in the browser.[1]
Feature list — quick summary
Multimodal sensing
- Text sentiment and fine‑grained emotion with negation/clause handling.[1]
- Voice tone (intensity, pitch) via short‑time energy.[1]
- Optional opt‑in facial expressions via dynamic face models.[1]
Fusion and decision‑making
- Weighted decision‑level fusion; temporal smoothing; uncertainty and baseline calibration.[1]
- Immediate heuristics plus asynchronous AI‑refined suggestions.[1]
Suggestions and interventions
- Deterministic templates with personalization tokens; IndexedDB caching.[1]
- Actions: breathing, grounding, stretches, writing prompts, rewrite proposals; lifecycle with feedback logging.[1]
Privacy and UX controls
- Camera/mic opt‑in; explicit consent for any cloud LLM usage.[1]
- Per‑site opt‑out, cooldowns, draggable overlay, and clear status labels.[1]
Robustness and safety
- MV3‑safe messaging wrapper; graceful failure modes; informative error logs.[1]
Developer and research tools
- Face‑model downloader scripts; negation/fusion/complex‑sentiment harnesses; public messaging contract.[1]
UI components
- Sidepanel (React): EmotionIndicator, InterventionCard, EmotionTimeline, WellnessStats, SettingsPanel; in‑page popovers via pageAdapter.[1]
Detailed behavior and math
Fusion contributions are computed as inline math $$ \text{contribution}_m = (\text{confidence}_m/100) \times \text{weight}_m $$, and uncertainty is $$ (1 - \text{maxProb}) \times 100 $$, with temporal smoothing using similarity thresholds and factor $$ \alpha $$.[1]
Displayed example:
$$
\text{Confidence} = \operatorname{clamp}\big(\operatorname{round}(\sum_m \text{contribution}_m \times 100),\ 1,\ 100\big)
$$
[1]
Example walkthrough
User types “I am not happy.” The system detects negation → detailedEmotion = ‘sad’; fusion yields primary = ‘sad’, confidence ≈ 70; an immediate heuristic suggestion appears, the user runs a 30‑second breathing exercise, then completion feedback updates WellnessStats.[1]
Quick copyable metadata
- Short name: EmotiFlow[1]
- Tagline: Real‑time, private multimodal emotion care[1]
- Short description: EmotiFlow senses text, voice, and optional facial signals (opt‑in) to detect emotion and deliver brief, safe wellness suggestions—privacy‑first with deterministic fallbacks for reliable offline demos.[1]
Built With
- browser-messaging/tabs-apis
- built?in/local-llm-apis-and-optional-cloud-llm-apis-(e.g.
- chrome-extension-mv3
- chrome-extensions-api
- chrome-extensions-apis-(chrome.runtime
- chrome.scripting)
- chrome.sidepanel
- chrome.storage
- chrome.tabs
- css
- dexie
- face-api.js
- fetch-api
- google-vertex
- html
- indexeddb
- indexeddb-(dexie)
- javascript
- mediadevices.getusermedia
- node.js
- npm
- postcss
- react
- tailwind-css
- tensorflow.js
- tensorflow.js-(face-api.js)
- typescript
- vite
- web-audio-api
- web-crypto-api
- webgl

Log in or sign up for Devpost to join the conversation.