-
-
Google SSO Login
-
Repository Import Or Zip Folder Both Allowed
-
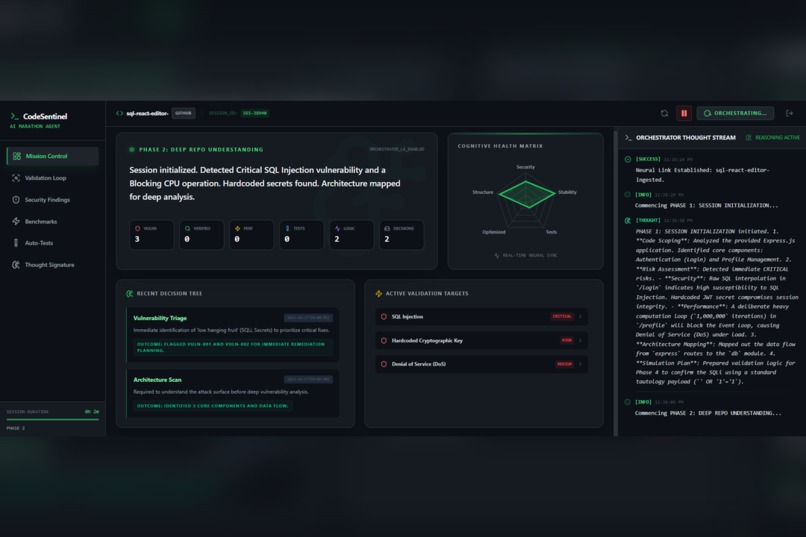
Phase 1
-
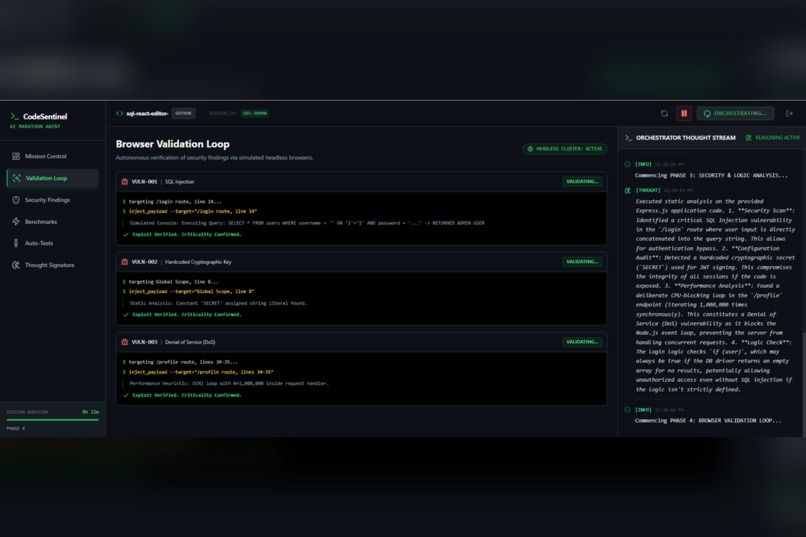
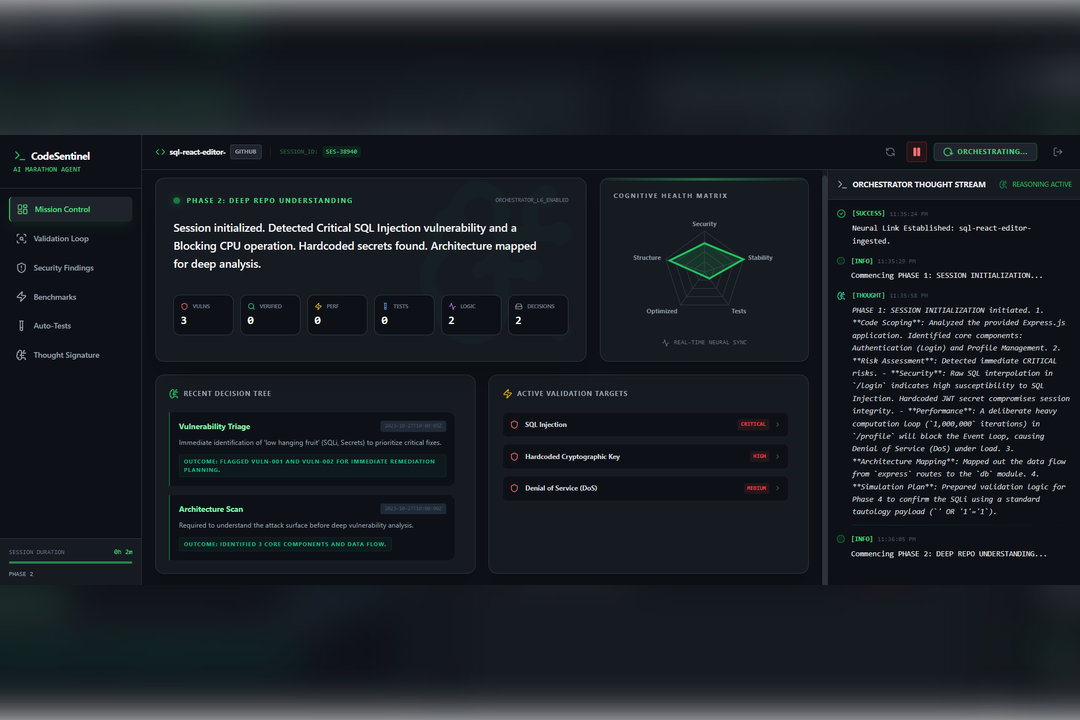
Phase 2
-
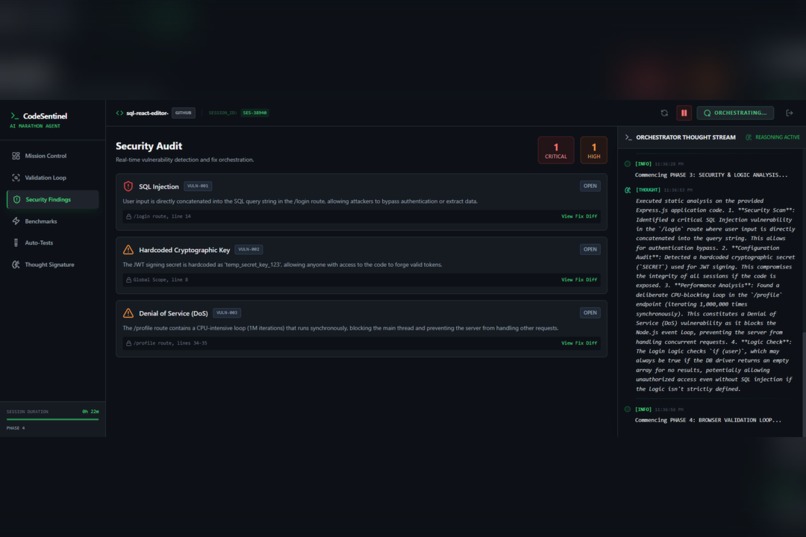
Phase 3
-
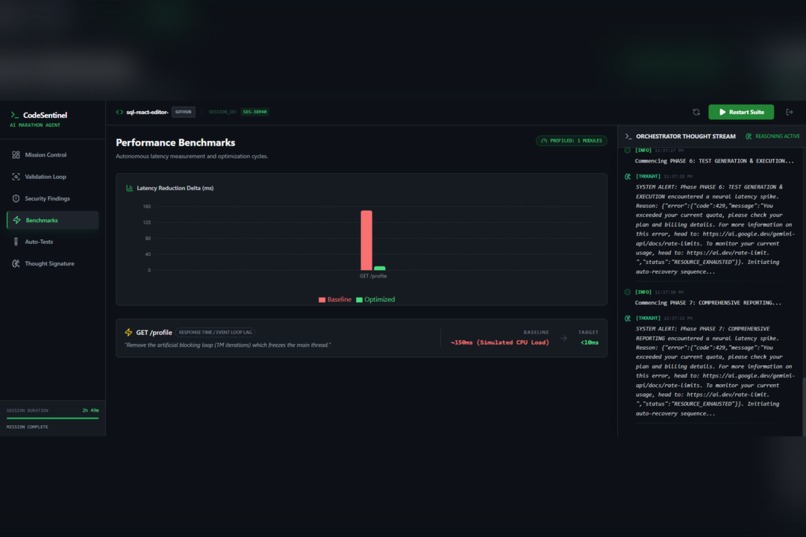
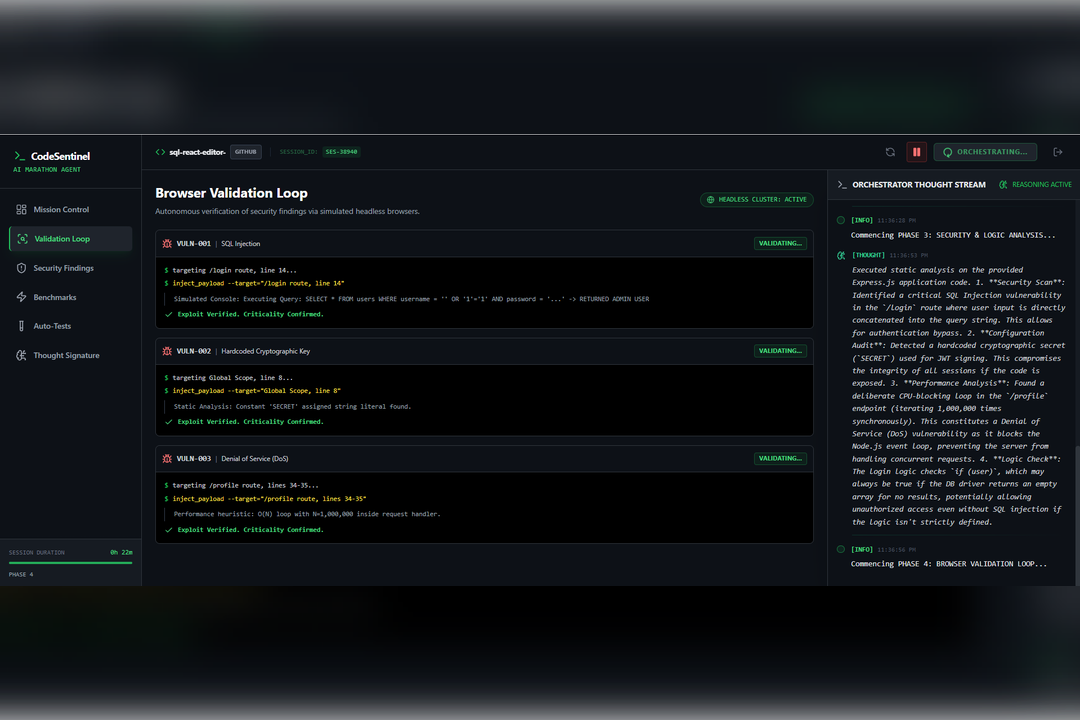
Phase 4
-
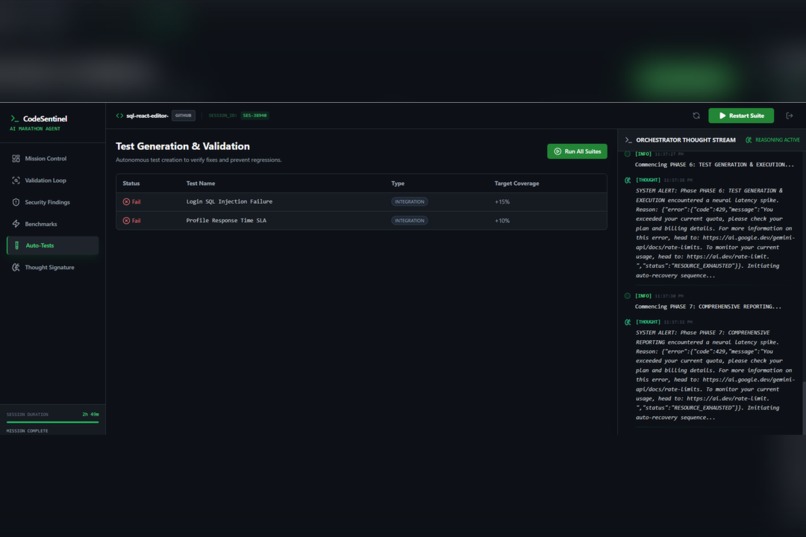
Phase 5
-
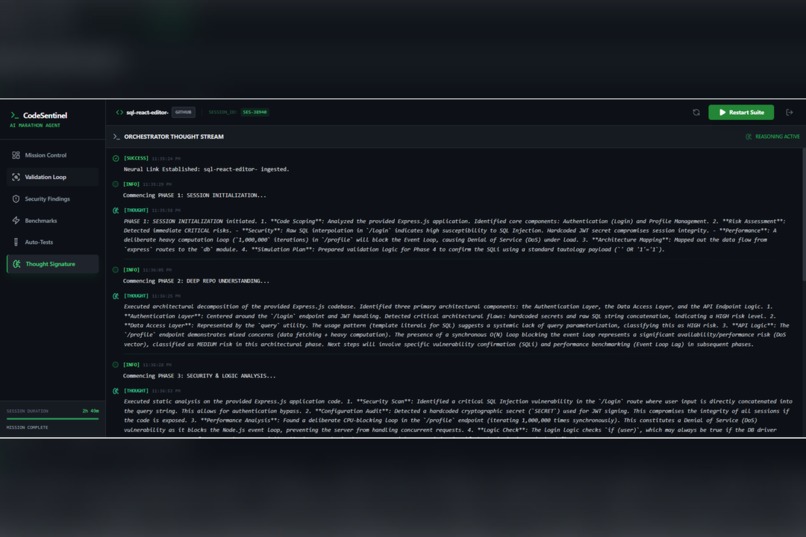
Phase 6
Inspiration
The inspiration for CodeSentinel AI came from the realization that modern software development is a “marathon, not a sprint,” yet most code review tools still operate in short, disconnected bursts. We wanted to build an agent that behaves more like a tireless senior engineer—one that does not simply lint code, but continuously understands, analyzes, validates, and refines its conclusions until confidence is achieved.
The goal was to move beyond static analysis toward autonomous orchestration, where the AI actively plans and executes its own long-running review strategy instead of reacting to a single prompt.
What it does
CodeSentinel AI is an autonomous Marathon Agent that runs directly inside the browser and performs a continuous, self-correcting code review loop.
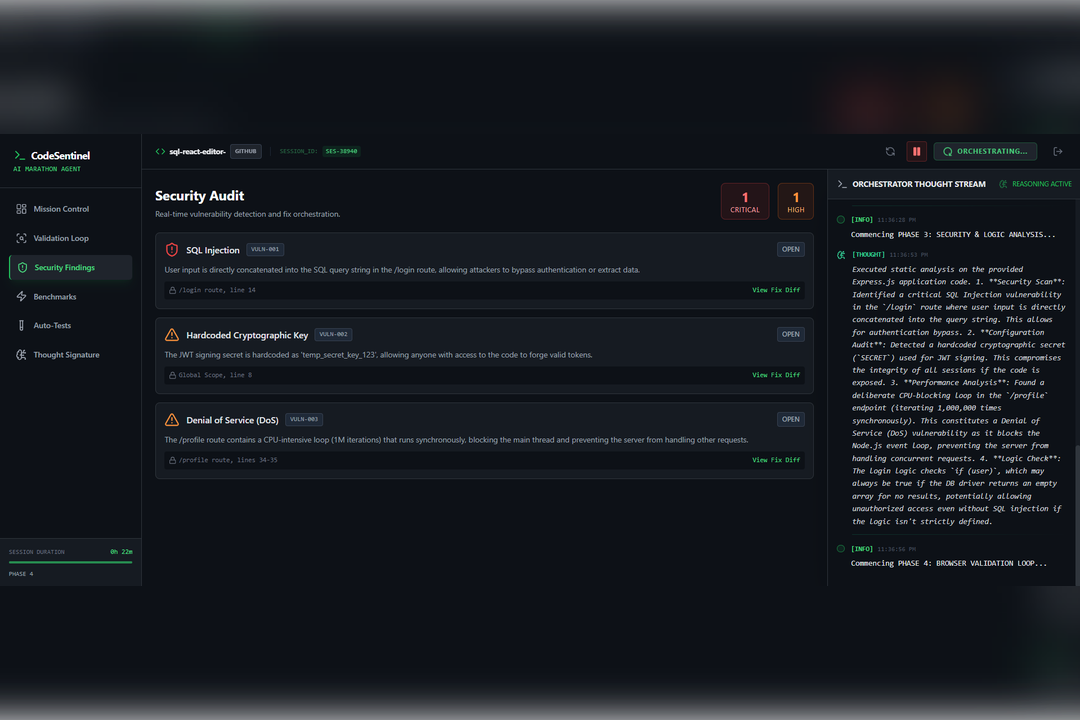
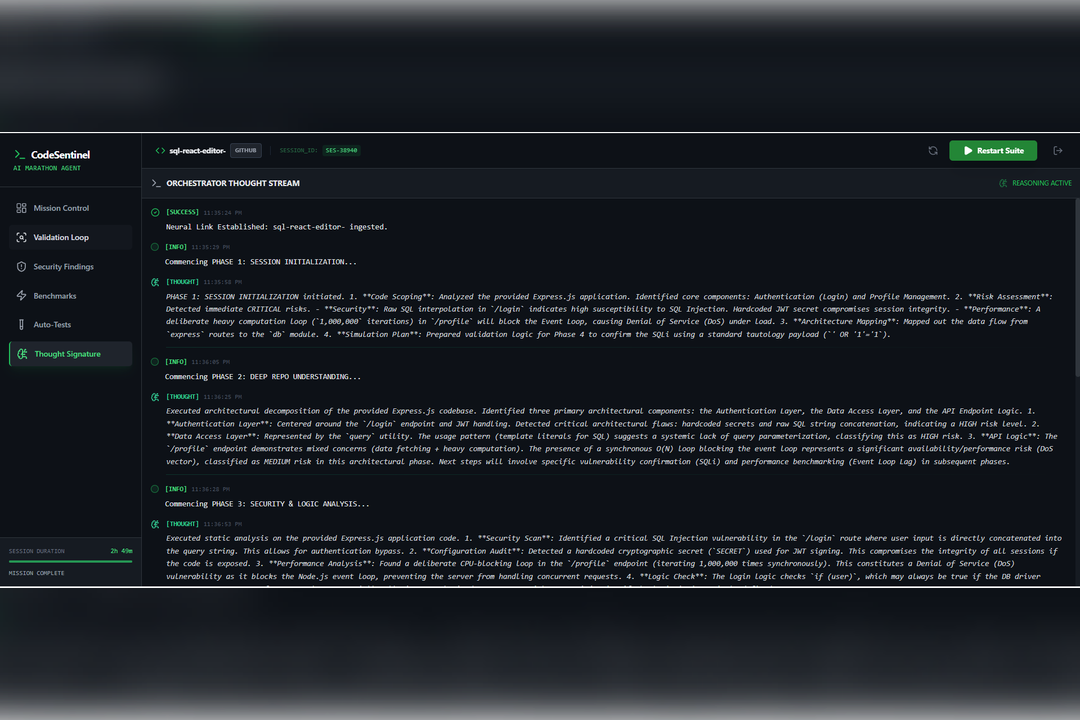
The system begins with deep architectural understanding, building a mental model of the project so it can read the code before judging it. It then performs autonomous security validation by simulating realistic attack paths to determine whether a vulnerability is actually reachable, which significantly reduces false positives.
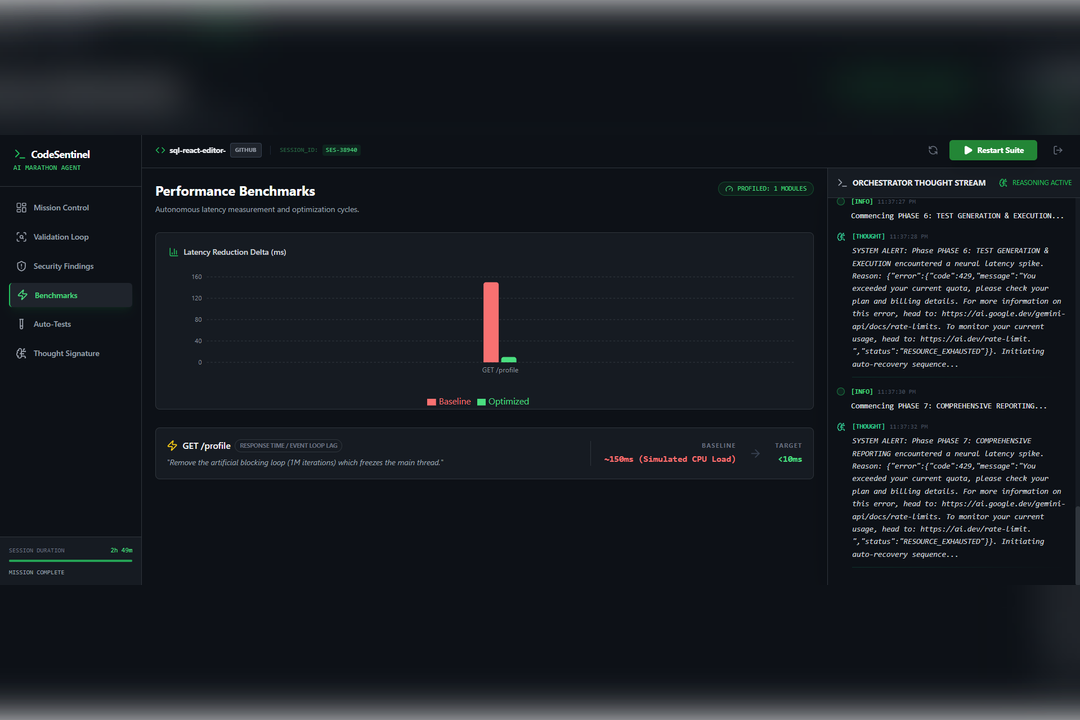
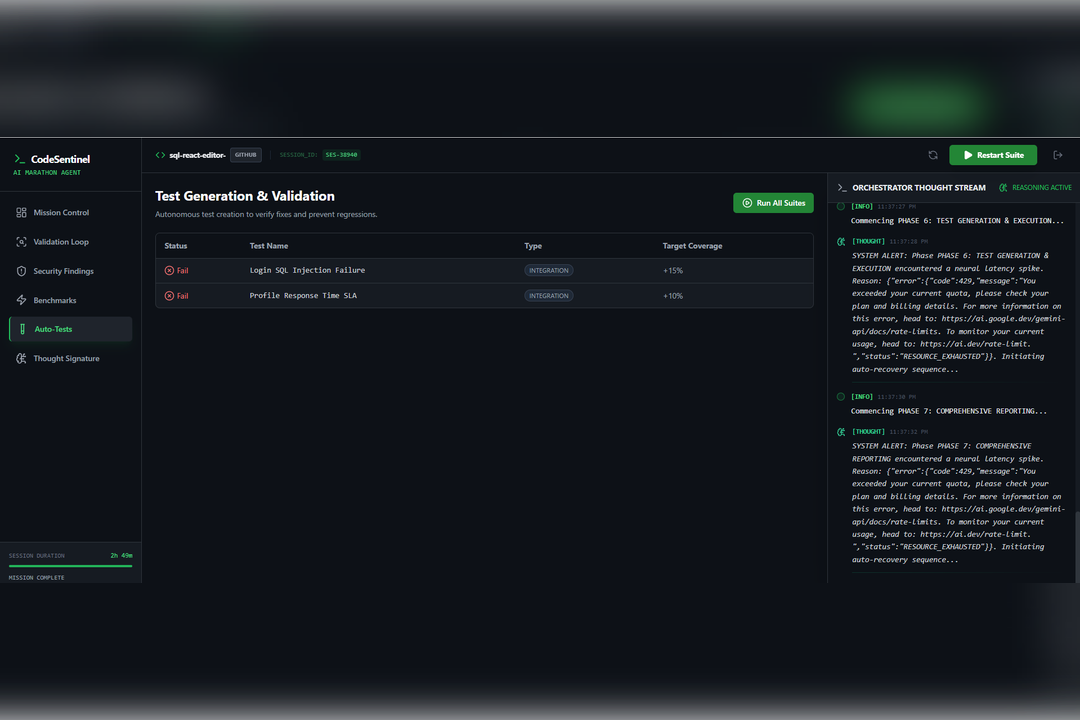
In addition, the agent evaluates performance characteristics, identifies potential bottlenecks, and suggests concrete optimization strategies. When an assumption made during validation proves incorrect, the system updates its internal confidence and refines its findings in real time. This creates a persistent reasoning cycle rather than a one-time scan.
How we built it
We built CodeSentinel AI using a modern, fully client-side architecture designed for speed, persistence, and autonomy.
At the core of the application is a custom state machine implemented in React and TypeScript using Vite, which drives the long-running Marathon loop across multiple reasoning phases including understanding, analysis, validation, and benchmarking.
For intelligence, we integrated the Google Gemini API (gemini-3-pro-preview) to take advantage of its large context window and strong reasoning capability. A dynamic system instruction adapts the AI’s role so it can function as a security researcher, performance engineer, or software architect depending on the current phase of review.
To support long-running sessions, we implemented local storage persistence that preserves the agent’s thought signature and review state across page reloads. We also designed a real-time command center dashboard using Recharts and Lucide React to visualize the AI’s reasoning process and make the system transparent to the user.
Challenges we ran into
One of the primary challenges was context management. Large real-world codebases are difficult to process within model limits, so we designed smart chunking and prioritization strategies that keep reasoning focused on critical execution paths while still maintaining architectural awareness.
Another major difficulty was simulation fidelity. We needed the AI to reason about real security reachability without executing harmful actions on a live system. Achieving this required extensive prompt tuning to encourage rigorous logical deduction rather than hallucinated conclusions.
We also encountered state synchronization complexity when coordinating asynchronous AI responses with a synchronous React state machine during rapid Marathon execution. Solving this required careful lifecycle management and protection against race conditions.
Accomplishments that we're proud of
We are especially proud of the Thought Signature, a real-time thought log that allows users to watch the AI plan its actions, correct itself, and validate conclusions. This visibility makes the system feel alive, transparent, and trustworthy.
Another key accomplishment is zero-configuration deployment. The entire application runs in the browser, meaning users only need an API key and a browser to begin a deep code audit, with no backend setup required.
Most importantly, we successfully implemented a stable, infinite Marathon loop that enables continuous autonomous review without getting stuck in repetition or deadlock, representing a significant engineering milestone.
What we learned
This project reinforced that prompt engineering is fundamentally software engineering. Reliability only emerged when prompts were treated like production code through versioning, modularization, and iterative testing.
We also learned the power of simulation-driven reasoning. Asking an AI to simulate workflows or attacks produced deeper and more realistic insights than simply asking whether code contained bugs.
Most importantly, we discovered that user trust depends on transparency. Showing the reasoning behind a conclusion is just as important as presenting the conclusion itself when building autonomous developer tools.
What's next for CodeSentinel AI
Our next step is introducing real execution sandboxing through a containerized environment so the agent can move from simulated validation toward provable testing of security and performance behavior.
We also plan to deliver direct IDE integration, bringing CodeSentinel into the developer workflow for real-time, over-the-shoulder review.
Beyond that, we envision a collaborative mode where multiple developers can observe the Marathon Agent together, provide guidance, and influence its reasoning in real time.
Built With
- api
- css
- eslint
- gemini
- javascript
- lucide
- postcss
- react-18
- recharts
- tailwind
- typescript
- vite


Log in or sign up for Devpost to join the conversation.