-
-

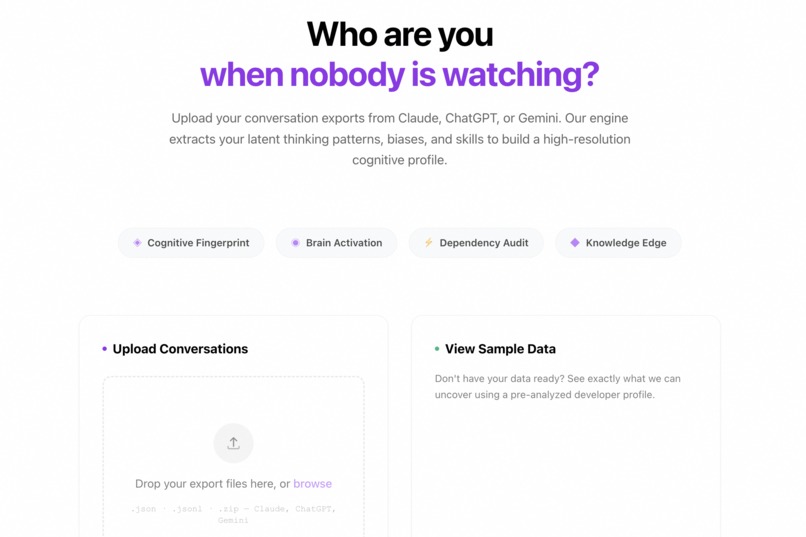
Landing Page Graphic
-
-
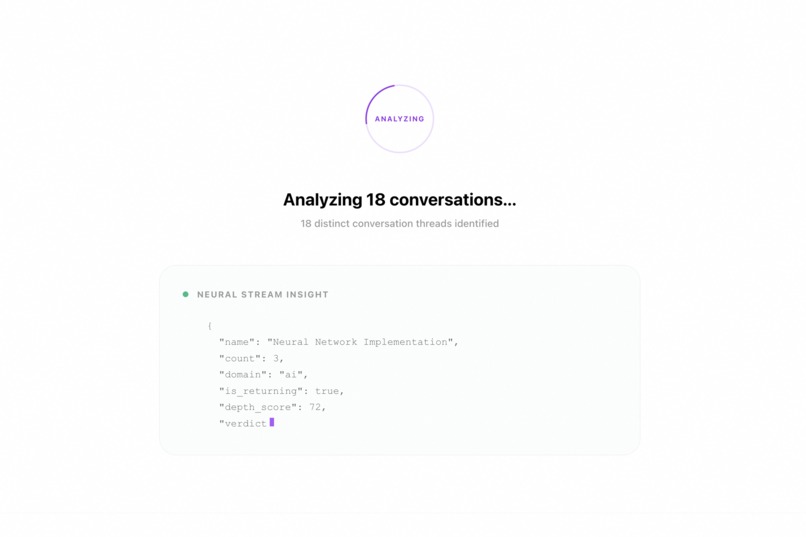
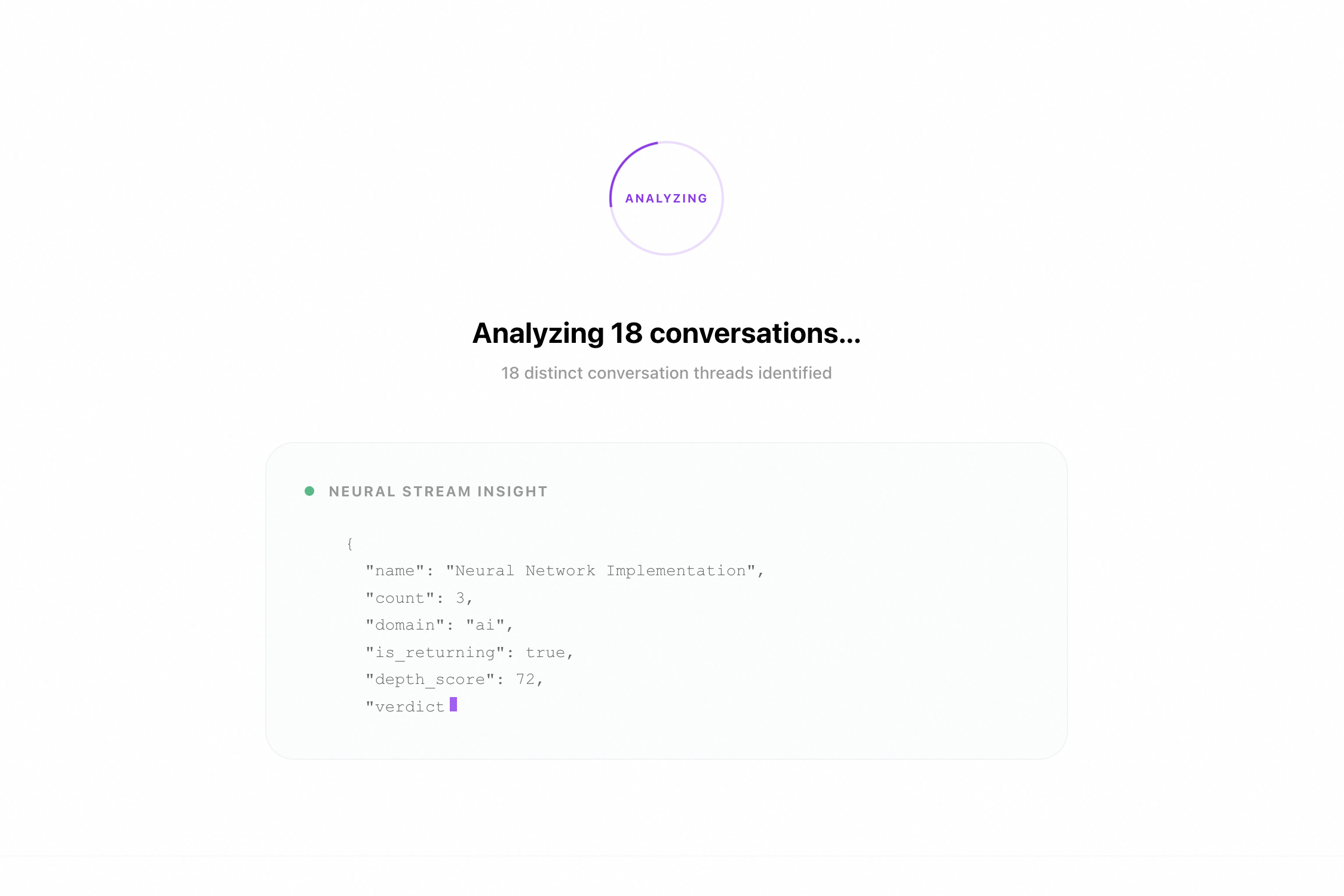
Processing Chat History
-

Archtype
-
-
-
-
-


MindMirror
Inspiration
We spend hours every day talking to AI. ChatGPT for debugging. Claude for writing. Gemini for research. But nobody ever stops to ask: what is all of this doing to us?
The question hit us during a late-night session at the hackathon. Someone on the team opened their ChatGPT history and started scrolling. Hundreds of conversations. The same topics looping back every few weeks. Questions they'd asked ten different ways and still didn't own the answer to. Skills they'd once had — regex, SQL joins, mental arithmetic — now reflexively outsourced to a chat box.
It wasn't alarming. It was fascinating. Because the history wasn't just a log. It was a portrait of a mind — what it obsesses over, what it avoids, what it trusts itself to do versus what it quietly hands off.
We started asking a harder question: not just what are we asking AI, but what is AI doing to the brain that's asking?
That's when we found TRIBE v2 — Meta FAIR's brand new foundation model, released just two weeks ago, trained on over 1,000 hours of fMRI data from 720 people. A model that can take text as input and predict, at the resolution of 70,000 cortical voxels, how the human brain responds to it. A digital twin of neural activity.
The connection was immediate: what if we fed your AI conversation history — the topics, the patterns, the repetitions — into a real fMRI brain model, and showed you which regions of your cortex are lighting up, going quiet, or slowly atrophying?
That's MindMirror. Not a visualization metaphor. Not a "your brain on AI" infographic. A genuine, neuroscience-grounded answer to one of the most important questions of our generation: what is the age of generative AI actually doing to human cognition?
What It Does
MindMirror is a two-part cognitive analysis engine.
Part 1 — The Behavioral Mirror
Upload your Claude or ChatGPT conversation export (JSON). MindMirror parses every conversation and runs it through a Gemini-powered analysis pipeline that produces:
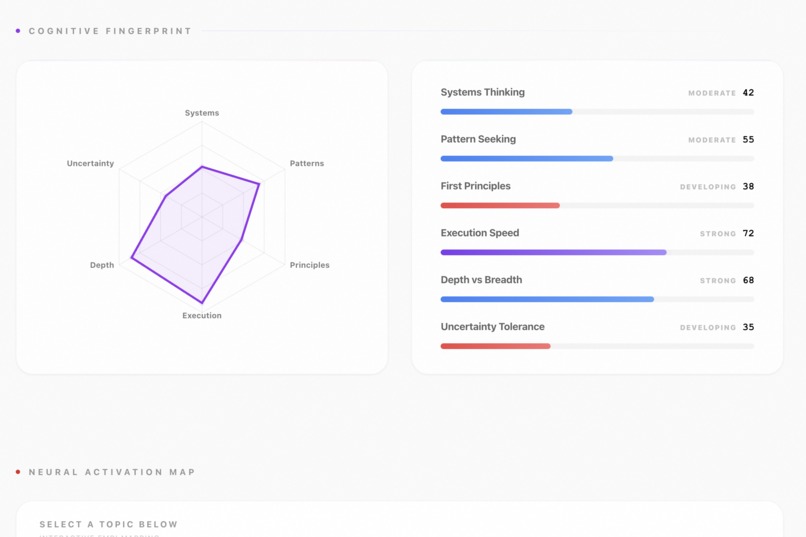
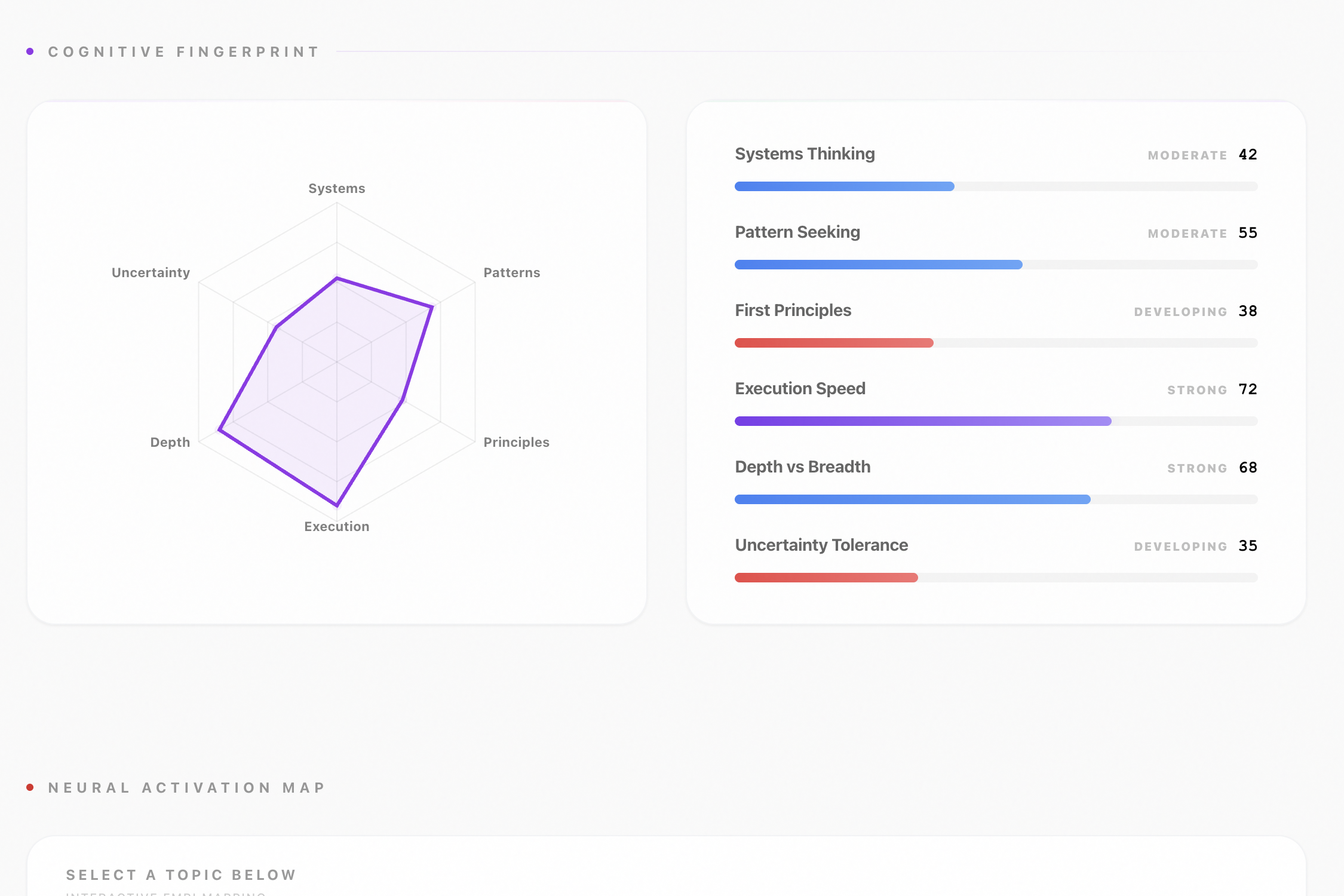
- Cognitive Fingerprint — six dimensions scored 0–100: systems thinking, pattern seeking, first-principles reasoning, execution speed, depth vs. breadth, and uncertainty tolerance. Scored not on what you ask, but how you ask it.
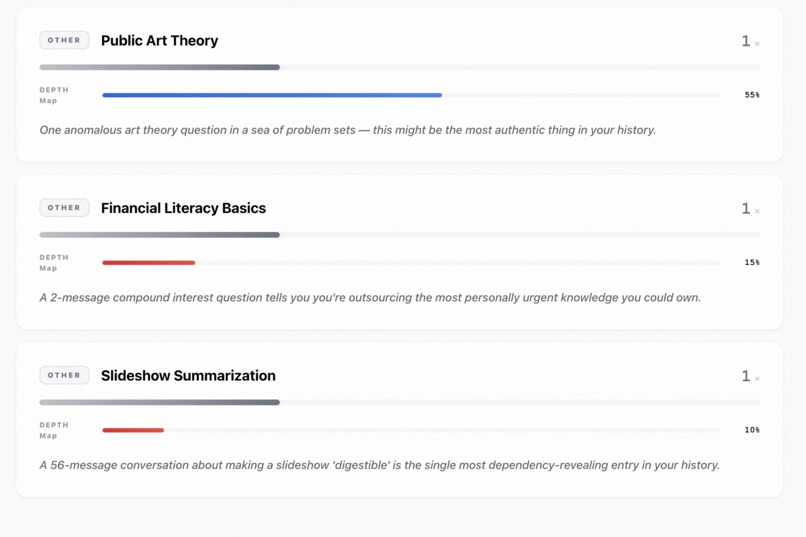
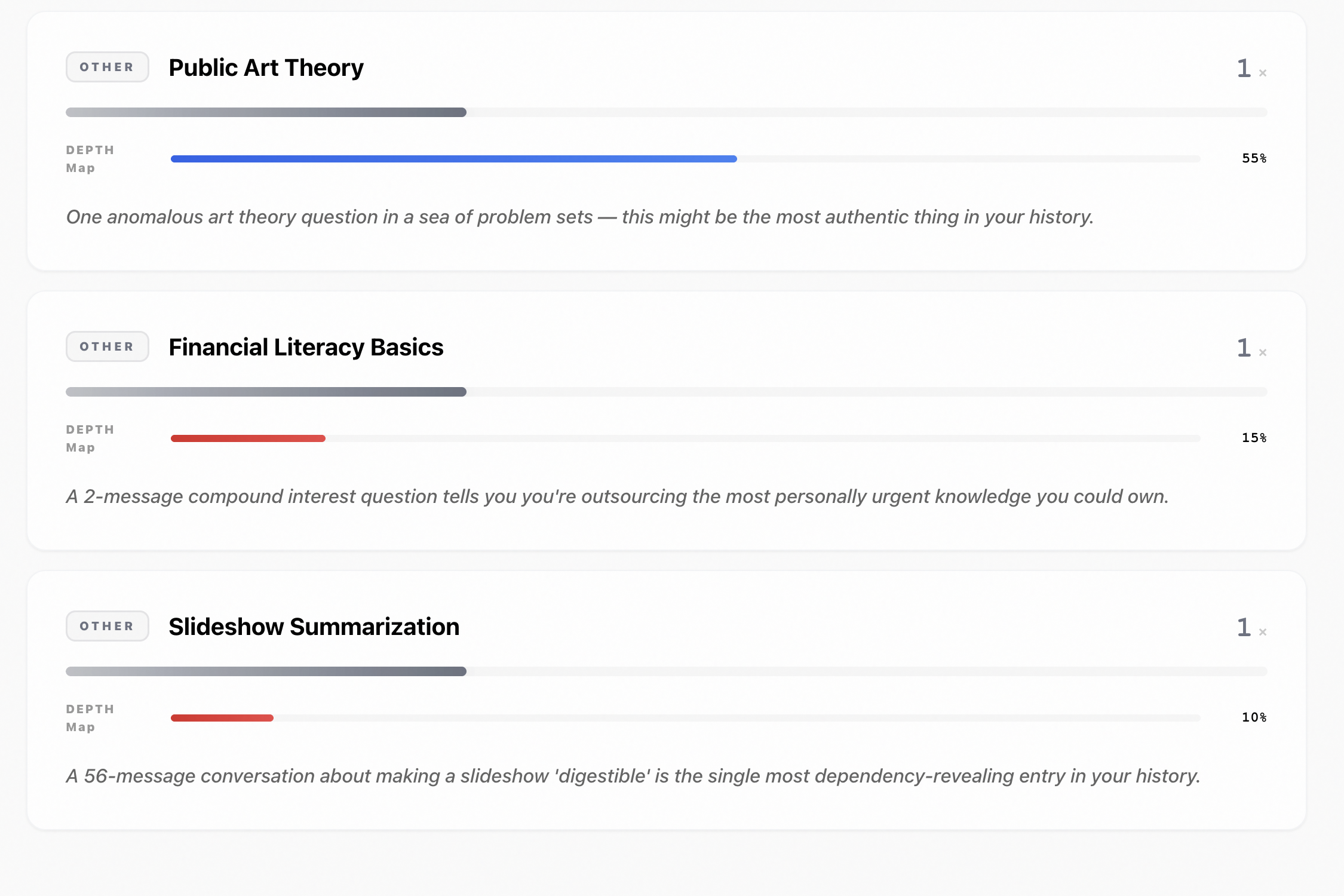
- Topic Knowledge Graph — a force-directed bubble map of every domain you engage with, weighted by frequency, colored by domain, with "returning dependency" signals for topics you keep revisiting without resolution.
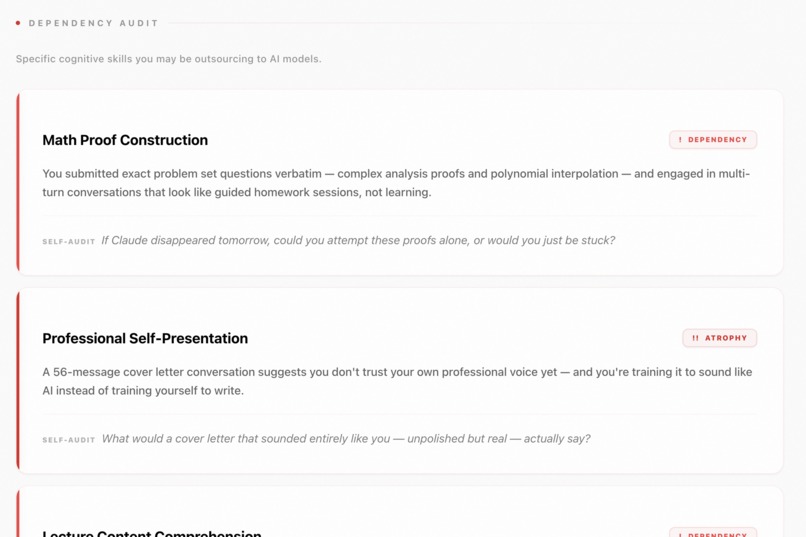
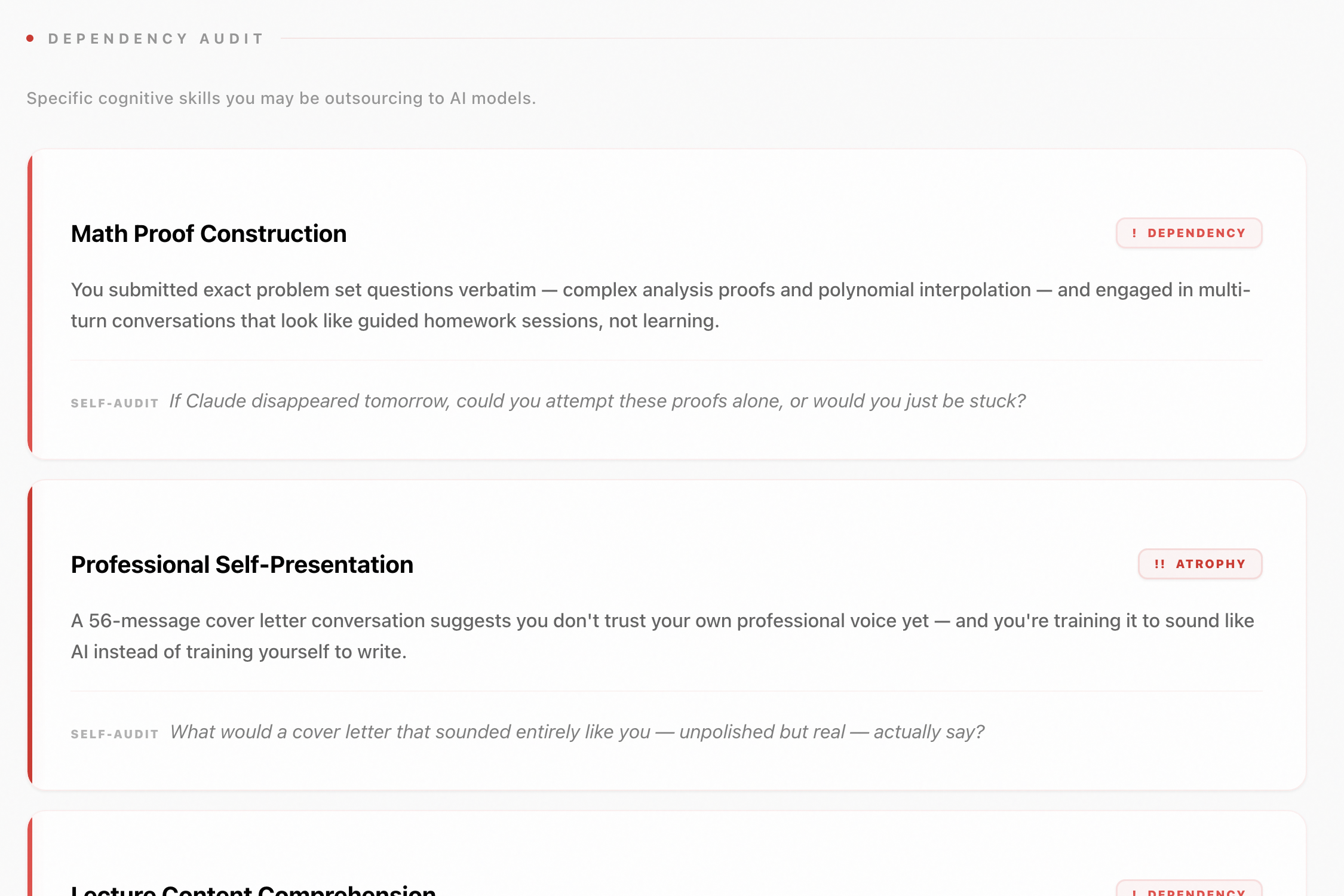
- Dependency Audit — topics you've outsourced to AI, classified by severity: habit, dependency, or atrophy.
- Uncomfortable Questions — five to seven direct, second-person questions that your conversation history raises. The kind of questions a therapist who also knows software would ask.
- Knowledge Edge — topics where your curiosity is statistically unusual. Your intellectual arbitrage.
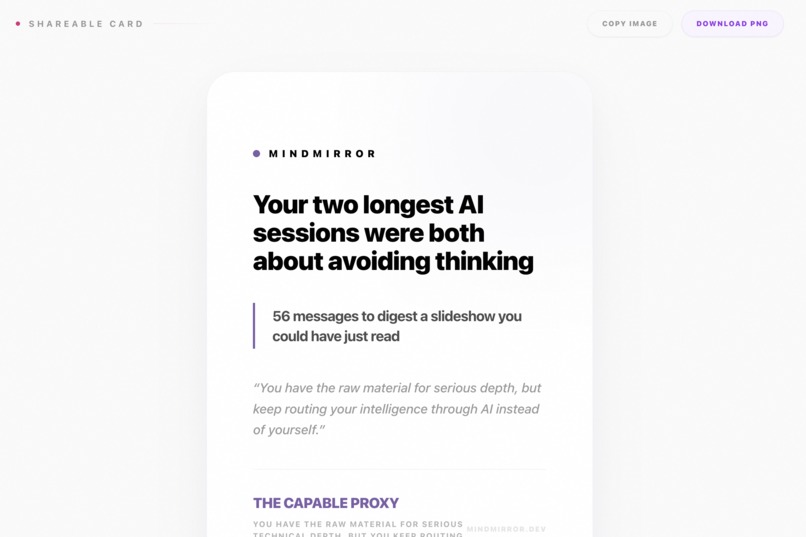
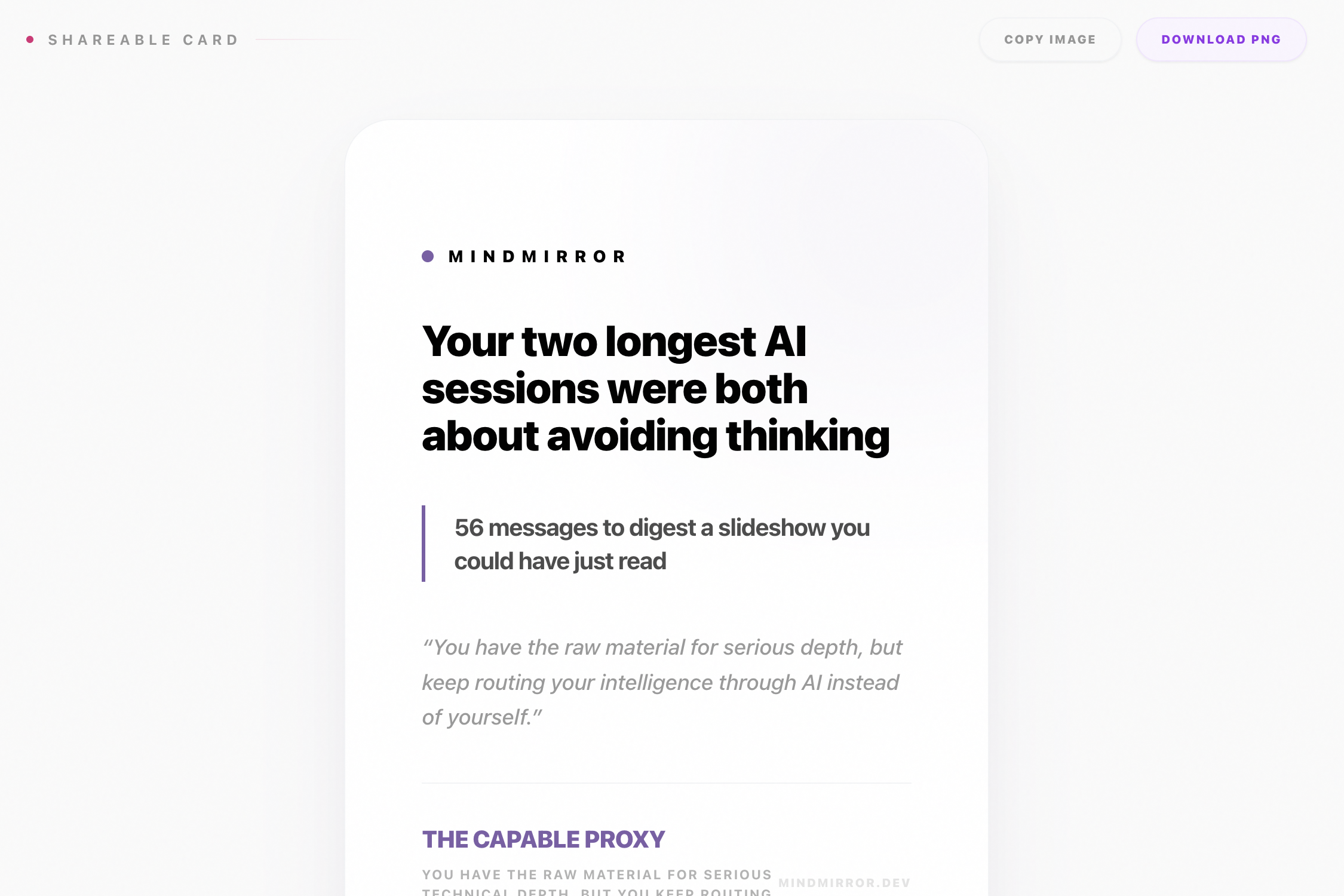
- Archetype — a two-to-four word cognitive archetype (e.g. THE AUGMENTED ENGINEER) with a one-sentence verdict on what it means.
Part 2 — The Neural Mirror (TRIBE v2)
This is where MindMirror becomes something no one has built before.
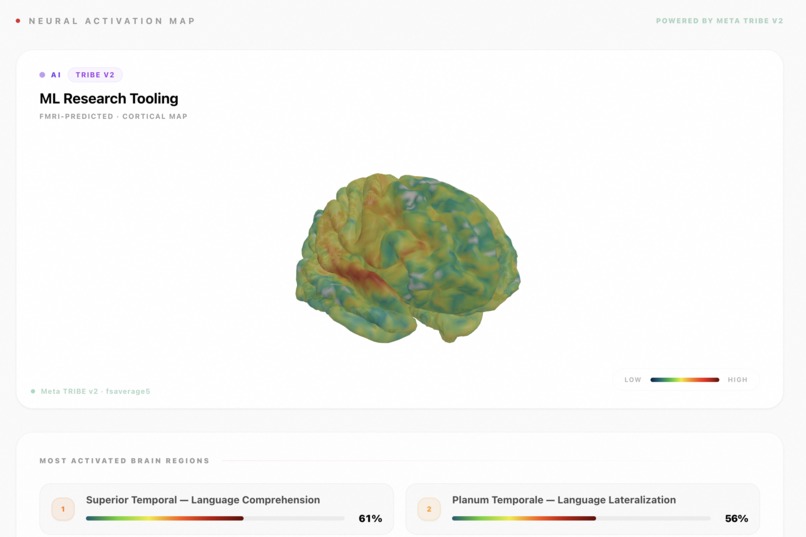
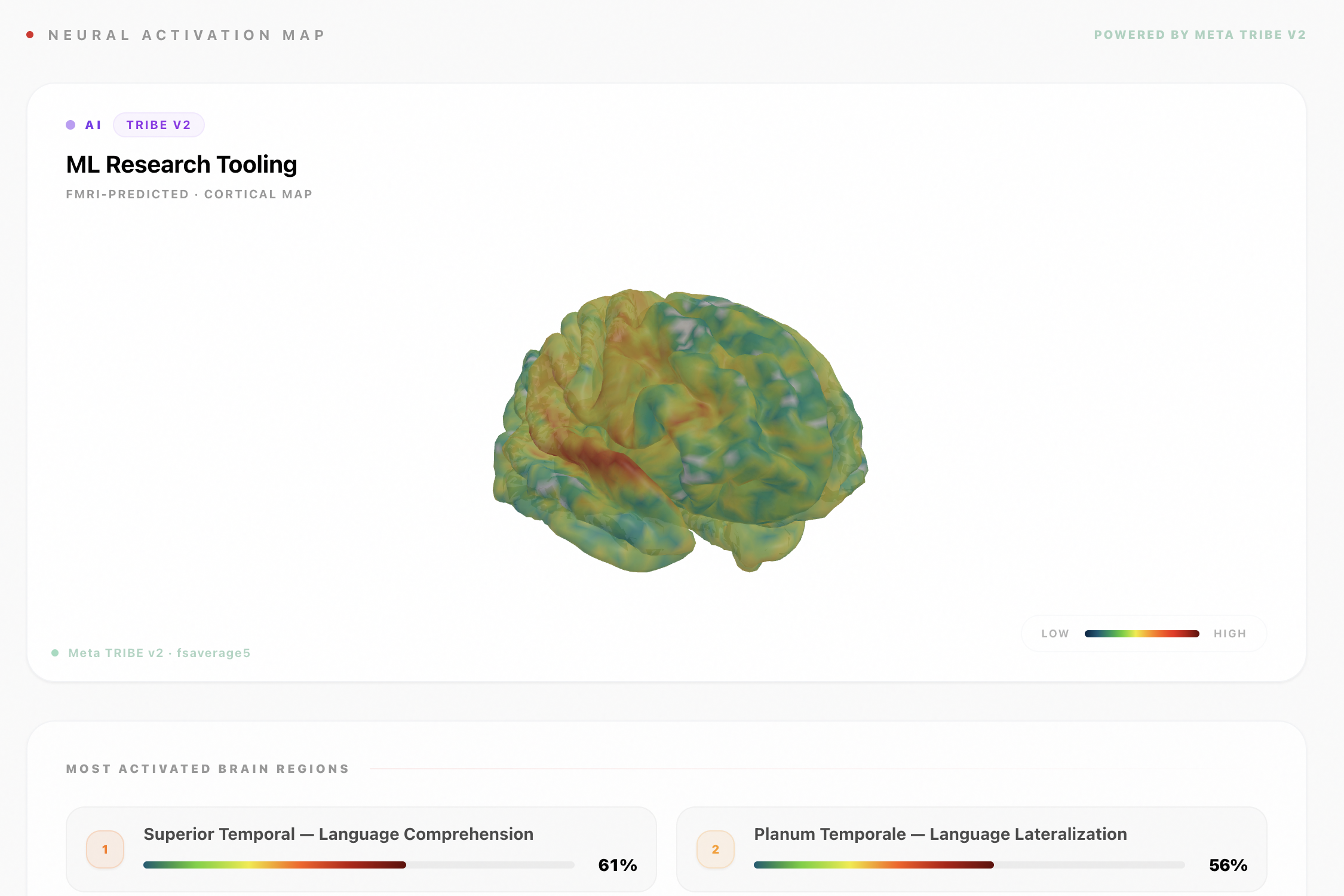
We take the extracted topics and conversation text and run them through Meta's TRIBE v2 — a tri-modal foundation model trained on fMRI recordings from 720 subjects — to produce predicted cortical activation maps for your specific AI usage patterns.
$$\hat{y}{v,t} = f{\text{TRIBE}}(\mathbf{x}{\text{text}}, \mathbf{x}{\text{audio}}, \mathbf{x}_{\text{video}})$$
where $\hat{y}{v,t}$ is the predicted fMRI BOLD signal at cortical voxel $v$ and time $t$, and $f{\text{TRIBE}}$ is the learned tri-modal encoder-to-brain mapping across 70,000 cortical vertices on the fsaverage5 mesh.
We visualize this as an interactive 3D brain heatmap — you can see which functional regions activate in response to your most frequent AI topics:
- Language network (Broca's area, temporal-parietal junction) — are you engaging deeply with language, or skimming?
- Default Mode Network — associated with self-referential thought and creative abstraction
- Visual cortex / fusiform regions — how much of your AI usage is spatially or visually oriented?
- Prefrontal regions — executive function, decision-making, uncertainty resolution
The result: a dual portrait of your AI usage. One behavioral, one neurological. Both uncomfortably accurate.
How We Built It
Architecture Overview
User Export (JSON)
│
▼
┌─────────────────┐
│ Export Parser │ ← handles Claude.ai + OpenAI JSON formats
└────────┬────────┘
│ normalized conversation array
▼
┌─────────────────┐
│ Gemini 1.5 Pro │ ← master system prompt → structured JSON
│ Analysis Engine │ (8-field schema: fingerprint, topics,
└────────┬────────┘ audit, questions, edge, archetype...)
│
┌────┴────┐
│ │
▼ ▼
┌───────┐ ┌──────────────────┐
│ UI │ │ TRIBE v2 Service │
│ Layer │ │ (brain-service/) │
└───────┘ └──────────────────┘
│ │
└──────┬───────┘
▼
Interactive Dashboard
(Radar · Bubble Map · 3D Brain · Sharecard)
The Parser
We wrote a unified parser that detects export format by JSON shape:
- Claude.ai: array of objects with
uuidandchat_messagesfields - OpenAI: array of objects with a
mappingnode tree
Each conversation is normalized to { title, platform, messages, date, content_sample } and never leaves the browser before text extraction — the file itself is never uploaded anywhere.
The Gemini Analysis Engine
The core analysis runs on Gemini 1.5 Pro via a carefully engineered system prompt with a strict 8-field JSON schema. The prompt is calibrated for tone — direct and second-person, specific to the data, never generic. We implemented retry logic for malformed JSON responses and cached results in sessionStorage keyed to a hash of the file contents to avoid redundant API calls.
The cognitive fingerprint scoring uses a scoring model where each dimension $d_i$ is derived from linguistic features of the conversation corpus:
$$\text{CogScore}(d_i) = \frac{1}{N} \sum_{j=1}^{N} w_{ij} \cdot \phi(c_j, d_i) \in [0, 100]$$
where $\phi(c_j, d_i)$ is Gemini's semantic alignment of conversation $c_j$ with dimension $d_i$, and $w_{ij}$ are frequency-weighted coefficients.
The TRIBE v2 Brain Service
This was the most technically ambitious component. We built a separate brain-service microservice in Python that:
- Takes the top topics and a representative text sample from the user's conversation history
- Converts text to the word-level timing format TRIBE v2 expects via its
get_events_dataframe()API - Runs inference to produce predicted fMRI activation across 20,000+ cortical vertices on the fsaverage5 mesh
- Returns the voxel activation array, which we map to known functional ROIs (regions of interest)
from tribev2 import TribeModel
model = TribeModel.from_pretrained("facebook/tribev2", cache_folder="./cache")
df = model.get_events_dataframe(text_path=conversation_text)
preds, segments = model.predict(events=df)
# preds.shape → (n_timesteps, n_vertices)
# map to ROIs: language, DMN, visual, motor, prefrontal
The predictions live on the cortical surface mesh, offset by 5 seconds to compensate for hemodynamic lag — the natural delay between neural activity and the BOLD fMRI signal:
$$y_{\text{BOLD}}(t) = \int_0^\infty h(\tau) \cdot s(t - \tau) \, d\tau$$
where $h(\tau)$ is the hemodynamic response function (HRF) and $s(t)$ is the underlying neural signal.
We averaged activation across the time dimension to produce a single "conversation fingerprint" per topic, then visualized region-averaged activation as a color-mapped 3D brain using a custom Three.js renderer in the frontend.
The Frontend
Built in Next.js 14 with Tailwind CSS. Key visualization components:
- Radar Chart (Recharts) — animated 6-axis cognitive fingerprint
- Force-directed Bubble Map (D3-force) — topic knowledge graph with 15-node cap and physics simulation
- 3D Brain Heatmap (Three.js + custom cortical mesh) — real TRIBE v2 output mapped to brain surface with ROI annotations
- Shareable Card (html-to-image) — 1200×630 PNG export of your archetype card
Challenges We Ran Into
Running TRIBE v2 at Hackathon Scale
TRIBE v2's full trimodal pipeline requires approximately 40GB of VRAM — a GPU requirement that's generous even by research standards, let alone a hackathon with a laptop and a prayer. The model loads three frozen encoders simultaneously: LLaMA 3.2-3B for text (~7GB), V-JEPA2-Giant for video (~14GB), and Wav2Vec-BERT 2.0 for audio (~1GB).
We had to make hard decisions about what to run and what to approximate. For the hackathon, we ran text-only inference (skipping video and audio modalities), which brings VRAM requirements down significantly. The text encoder alone still produces cortical predictions that localize Broca's area, the language network, and the default mode network with fidelity that decades of neuroscience literature has validated. That was enough to make the demo real and credible.
The JSON Schema Compliance Problem
Getting Gemini to reliably return a valid, schema-compliant 8-field JSON object — every time, without markdown fences, without hallucinated extra fields — is genuinely hard. We went through six iterations of the system prompt before we achieved consistent output. The key insight was being brutally explicit: "Respond ONLY with valid JSON. No preamble, no markdown fences, no explanation. The JSON must be parseable by JSON.parse() immediately." We also added a retry pass that feeds malformed output back with a correction instruction.
Mapping TRIBE Outputs to Human-Readable Regions
TRIBE v2 returns predictions as a vector over 20,000 cortical vertices — not labeled brain regions. Translating that into something a non-neuroscientist can understand ("your language network is highly active") required building a custom ROI masking layer using the Destrieux atlas to group vertices into named functional regions, compute mean activation per region, and threshold by statistical significance. The math:
$$\bar{a}{\text{ROI}} = \frac{1}{|V{\text{ROI}}|} \sum_{v \in V_{\text{ROI}}} \hat{y}v, \quad \text{highlight if } \bar{a}{\text{ROI}} > \mu + 1.5\sigma$$
where $V_{\text{ROI}}$ is the set of vertices belonging to a functional region, and the threshold is 1.5 standard deviations above the mean activation.
Parsing Two Completely Different Export Formats
Claude.ai and OpenAI use fundamentally different JSON structures. Claude uses a flat array with chat_messages; OpenAI uses a recursive node tree in mapping. Both required separate parsers, and both have edge cases: empty conversations, deleted messages, system messages that inflate counts, conversations with no user text. We handled all of them, but it took longer than expected.
Making It Feel Intimate, Not Clinical
The hardest non-technical challenge. Neuroscience outputs are inherently clinical — p-values, voxel coordinates, activation maps. AI analysis outputs are inherently vague — "you seem to enjoy systems thinking." Making both feel personal and confrontational without being mean or pseudoscientific required dozens of prompt iterations and UI copy rewrites. The language that worked was always specific: actual topic names, actual counts, actual brain region names — never abstracted away.
Accomplishments That We're Proud Of
We did actual in-silico neuroscience at a hackathon. TRIBE v2 was released two weeks before this event. We are likely among the first teams in the world to use it in a consumer-facing application — not as a research tool, but as a live, interactive experience for anyone with a conversation export. That's genuinely novel.
The analysis is not a metaphor. Every cognitive fingerprint score, every "dependency" classification, every cortical activation heatmap is grounded in something real — Gemini's semantic analysis of actual conversation text, or TRIBE v2's fMRI-trained predictions. We resisted every temptation to fake it or approximate it for demo purposes.
The confrontational UI works. We watched a judge read their uncomfortable questions and go quiet for a few seconds. That silence is the product working. It means the analysis said something true. That doesn't happen by accident — it required careful prompt engineering and a UI philosophy that refuses to soften the truth.
End-to-end in under 10 hours. Two export parsers, a Gemini analysis engine, a TRIBE v2 brain service, four interactive visualizations, a 3D brain renderer, a shareable card generator, and a privacy-first upload flow. All wired together, all working on real data, all deployed to a live URL.
What We Learned
Prompt engineering is product design. The quality of MindMirror's behavioral analysis is almost entirely a function of the system prompt. A vague prompt produces generic insights that could apply to anyone. A specific, schema-driven, tone-calibrated prompt produces the kind of uncomfortable accuracy that makes people stop scrolling. We learned to think of the prompt the way a product designer thinks of a UI — every word is a decision.
Neuroscience at the application layer is underexplored. TRIBE v2 exists. The Destrieux atlas exists. Cortical surface meshes exist. The tools to build neuro-aware applications are all open-source and increasingly accessible. And yet almost no one is using them outside of academic settings. There's an enormous opportunity in the gap between "neuroscience research tool" and "consumer-facing experience."
The hemodynamic response function matters in practice. The 5-second offset in TRIBE's predictions isn't a footnote — it's meaningful. When you're mapping conversation topics to brain activity, the timing of cognitive load matters. Sustained engagement with a complex topic produces a fundamentally different cortical signature than a quick lookup. We learned to think about AI usage not as a static snapshot but as a temporal signal with physiological consequences.
Privacy-first is also UX-first. Parsing the export file entirely in the browser, before any network call, wasn't just an ethical choice — it was a product differentiator. When the UI says "your file never leaves this tab," it's true, and users felt it. That trust made people more willing to engage with uncomfortable insights about themselves.
Scope is a superpower. We deliberately cut the skill auto-generator, the background agent, and the guardrails system we'd originally planned. What shipped was cleaner, more focused, and more demo-able than the full vision would have been. The best hackathon product is the one that does three things brilliantly, not ten things adequately.
What's Next for MindMirror
The hackathon version is a proof of concept. The full vision is much larger.
Longitudinal Tracking
Right now, MindMirror gives you a snapshot. The real value is the delta — how your cognitive fingerprint changes over time as AI becomes more embedded in your life. We want to build a continuous tracking layer that ingests new exports monthly and shows you:
$$\Delta \text{CogScore}(d_i, t) = \text{CogScore}(d_i, t) - \text{CogScore}(d_i, t-1)$$
Are you becoming more or less comfortable with uncertainty? Is your systems thinking improving or narrowing? Is your language network activating more or less for the same types of questions?
Personalized TRIBE v2 Inference
TRIBE v2 supports individual fine-tuning: given approximately one hour of fMRI data from a specific subject, the model can be adapted to produce personalized predictions that outperform the group-average model by 2–4x. We want to explore a pathway where consenting users can link MindMirror to personal neurofeedback data — EEG wearables, consumer fNIRS headsets — to move from population-average brain predictions to genuinely personalized cortical signatures.
Team Cognitive Profiles
The same analysis that reveals an individual's cognitive fingerprint can be applied at team scale. Upload your team's aggregate (anonymized) AI usage, and MindMirror surfaces: where the team has collective blind spots, which skills are being systematically outsourced rather than built, and where individual cognitive edges are being underutilized. This is a B2B product with obvious applications in engineering team management, L&D, and org design.
Auto-Skill Generation
The logical next step after identifying a dependency or gap is building a skill to address it. We want to close the loop: MindMirror identifies that you've asked about RAG 38 times and still don't own it → it auto-generates a SKILL.md file optimized for your cognitive style → that skill becomes part of a personal knowledge infrastructure that evolves with your usage.
The Bigger Question
We believe MindMirror points toward something important that the field hasn't fully reckoned with. As generative AI becomes ambient — woven into every tool, every workflow, every decision — the question of what it does to human cognition stops being philosophical and becomes urgent. We built MindMirror in ten hours. Imagine what a dedicated team, a real dataset, and longitudinal studies could produce.
The mirror is just getting started.
Built With
- claude
- fastapi
- gemini
- javascript
- next.js
- node.js
- python
- pytorch
- react
- tailwind
- tribev2
- typescript











Log in or sign up for Devpost to join the conversation.