-
-
Home
-
Node Map
-

AR Visual
-

Documented


Inspiration
We spent 14 of our 36 hours just planning. Everything we said went into a Google Doc, got fed to AI for "refinement," and came back as something that sounded nothing like us. We'd scrap it, start over, repeat. By hour 14 we had a few half-baked ideas and a doc full of slop.The breaking point was realizing the problem wasn't our ideas — it was that no tool captures how ideas actually form. Your brain doesn't think in bullet points. It branches, connects, jumps sideways, doubles back. Every tool we tried forced us to linearize a process that is fundamentally non-linear. So we stopped planning and built the thing we needed to plan.
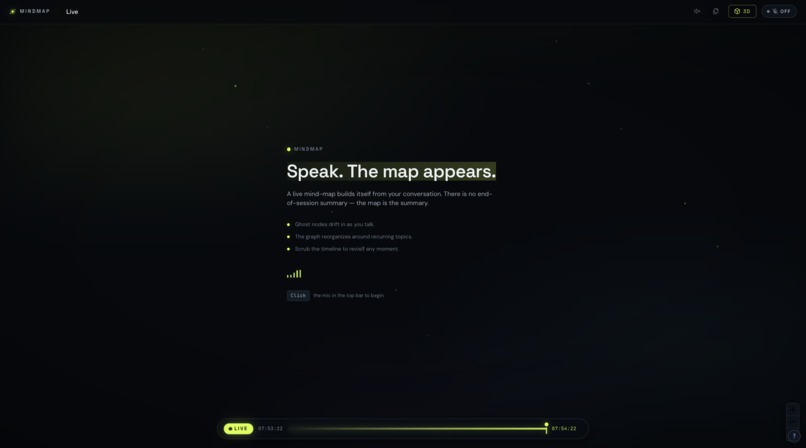
What it does
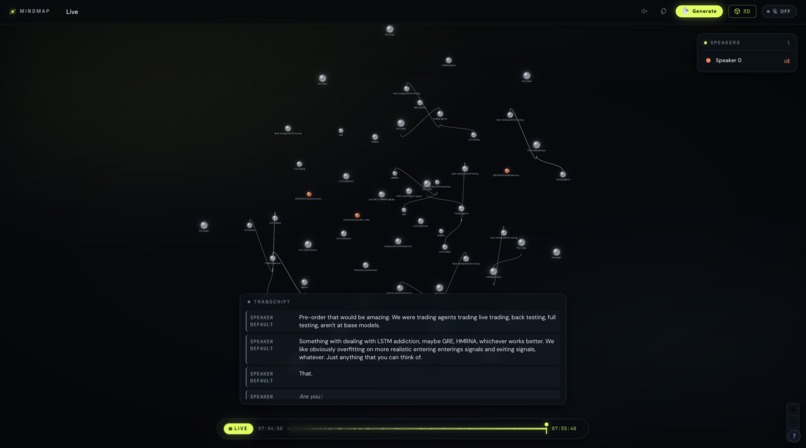
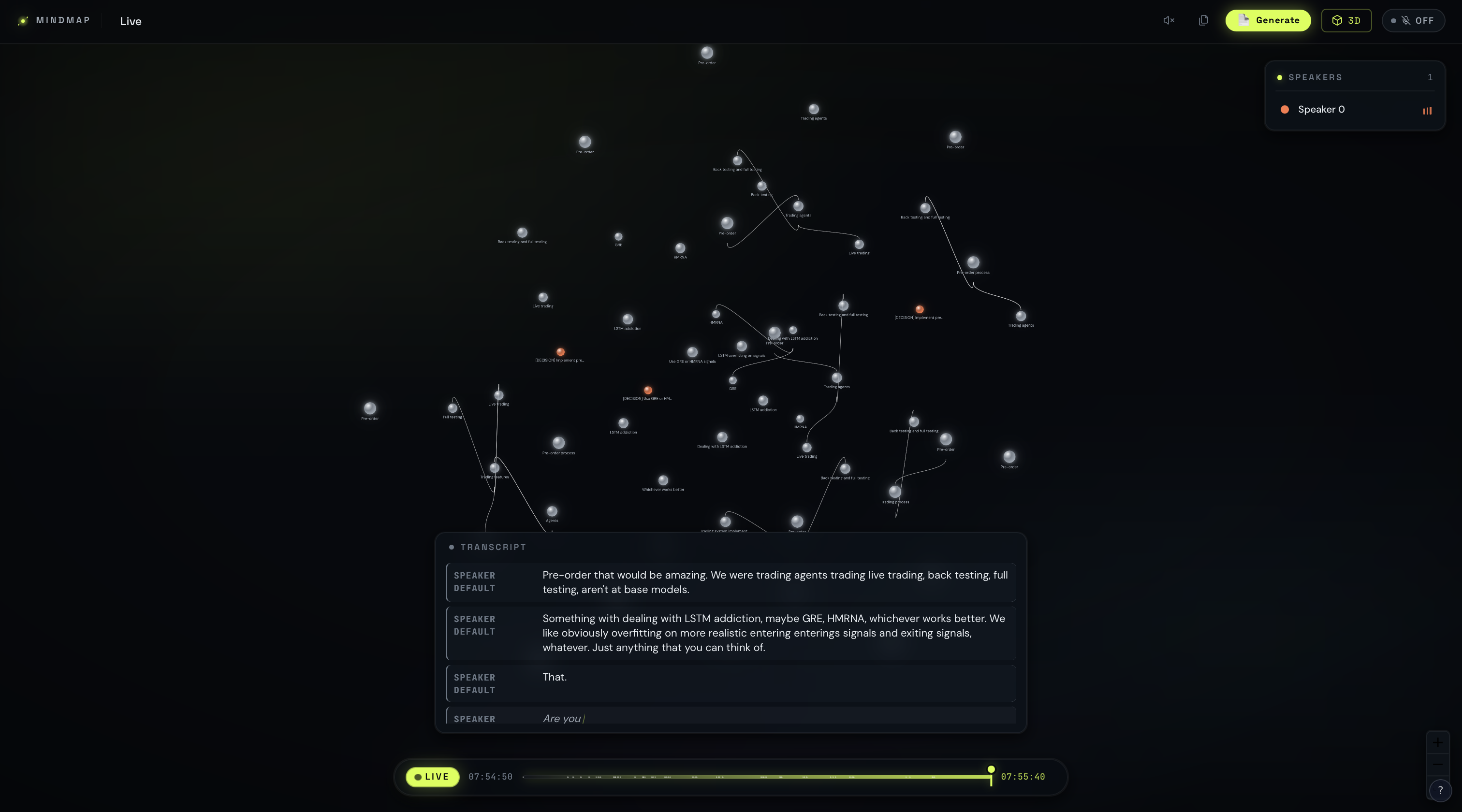
MindMap is a real-time ideation engine. You talk — alone or with your team — and MindMap builds a live graph of your thinking as you speak. No typing, no organizing, no interrupting your flow.As topics emerge, nodes appear. As ideas connect in conversation, edges form between them — typed as direct, tangential, or inferred connections. As you go deeper on any concept, a parallel agent quietly enriches that node with key points, waiting inside for you to click. Every speaker is color-coded, so you can see not just what was said but who introduced each idea and who made the connections.Sessions are timestamped at every action, so you can scrub back through the graph and watch your thinking assemble itself in replay. You can branch from any moment like a git branch for thought. When the graph grows large, switch to 3D mode and navigate your ideas in space. Drop in screenshots or images mid-session and they attach directly to the nearest node.When you're done, you don't get a summary. You get the map — exactly as your brain made it.
How we built it
The audio layer runs on ElevenLabs' Scribe v2 Realtime API via WebSocket, giving us ~150ms latency transcription with voice diarization to separate speakers in real time. Two AI agents handle the graph. Agent 1 (Graph Topology) fires every few seconds, receiving a rolling window of the last ~100 words plus the current graph state as a serialized JSON object, and returns a diff — add node, merge near-duplicates, add or update edges, assign edge types. It never removes nodes. Agent 2 (Node Enrichment) runs in a parallel non-blocking thread, detects when the conversation is dwelling on a specific existing concept, and writes concise key points into that node's info panel. Graph state, edge metadata, speaker attribution, and session history all live in MongoDB Atlas, which also powers the timeline scrub and session branching features. The frontend renders the live force-directed graph using React, with a Three.js layer for 3D mode.
Challenges we ran into
Keeping Agent 1 fast enough to feel real-time without hallucinating connections was the hardest technical problem. Too large a context window and it started inventing relationships. Too small and it missed legitimate ones. Finding the right rolling window size and graph serialization format took most of our iteration time. Speaker diarization in real time is genuinely hard. ElevenLabs' batch Scribe v2 supports full diarization, but the real-time model doesn't natively separate speakers mid-stream. We worked around this by routing separate microphone inputs as distinct audio channels and attributing by source. The 3D graph mode sounds simple but spatial layout of a force-directed graph in three dimensions without it becoming visually chaotic took significant tuning. Making it navigable rather than just impressive was the challenge.
Accomplishments that we're proud of
The demo works on a real conversation in real time. That sounds obvious but it's the thing we were least sure about at hour one and most proud of at hour 36. The two-agent architecture genuinely runs in parallel without either agent blocking the other. You can watch node enrichment populate inside a node while the graph is still actively growing from new speech — they're completely independent. We validated the problem with 10+ teams at this hackathon before writing a single line of code. Every team confirmed the same pain point. Knowing we were building something people around us actually needed made every hard hour worth it. The 3D mode. It looks exactly as cool as we hoped.
What we learned
Real-time AI systems are unforgiving in ways that batch systems aren't. Latency compounds. One slow agent call creates a visible lag in the graph that breaks the feeling of flow — which is the entire product. Keeping every layer fast wasn't an optimization, it was a core product requirement. We also learned that the best product decisions were subtractive. Every time we asked "what else should this do?" the answer was usually "nothing." No AI summary at the end. No auto-suggestions. No chatbot. The restraint is what makes it feel focused instead of bloated.
What's next for MindMap
Async collaboration — teammates joining a session from separate locations, their speech layered into the same graph in real time. A results layer — after a session, an optional structured output (not a summary, but a decision artifact) that captures only what the team explicitly resolved, separate from the ideation graph itself. Deeper OmegaClaw integration — so any OmegaClaw user can trigger a MindMap ideation session as a native skill directly from ASI:One. Long-session compression — intelligent clustering of large graphs into navigable super-nodes, so hour-long sessions don't become visually overwhelming even in 3D. And eventually, a public graph library — anonymized mind maps from real ideation sessions that teams can use as thinking templates for common problem types.
Built With
- elevenlabs-api
- eslint
- fastapi
- groq
- mangodb
- python
- typescript


Log in or sign up for Devpost to join the conversation.