Inspiration
Search is one of the most ancient user-facing tools in the world of software. However, given the current state of "information velocity" and strains on mental health, we felt it was time to push for a search that only got the user where they needed to go, with the minimal amount of distraction and mental overhead. Presenting MindfulQ: a web querying system that won't make you question your sanity.
What it does
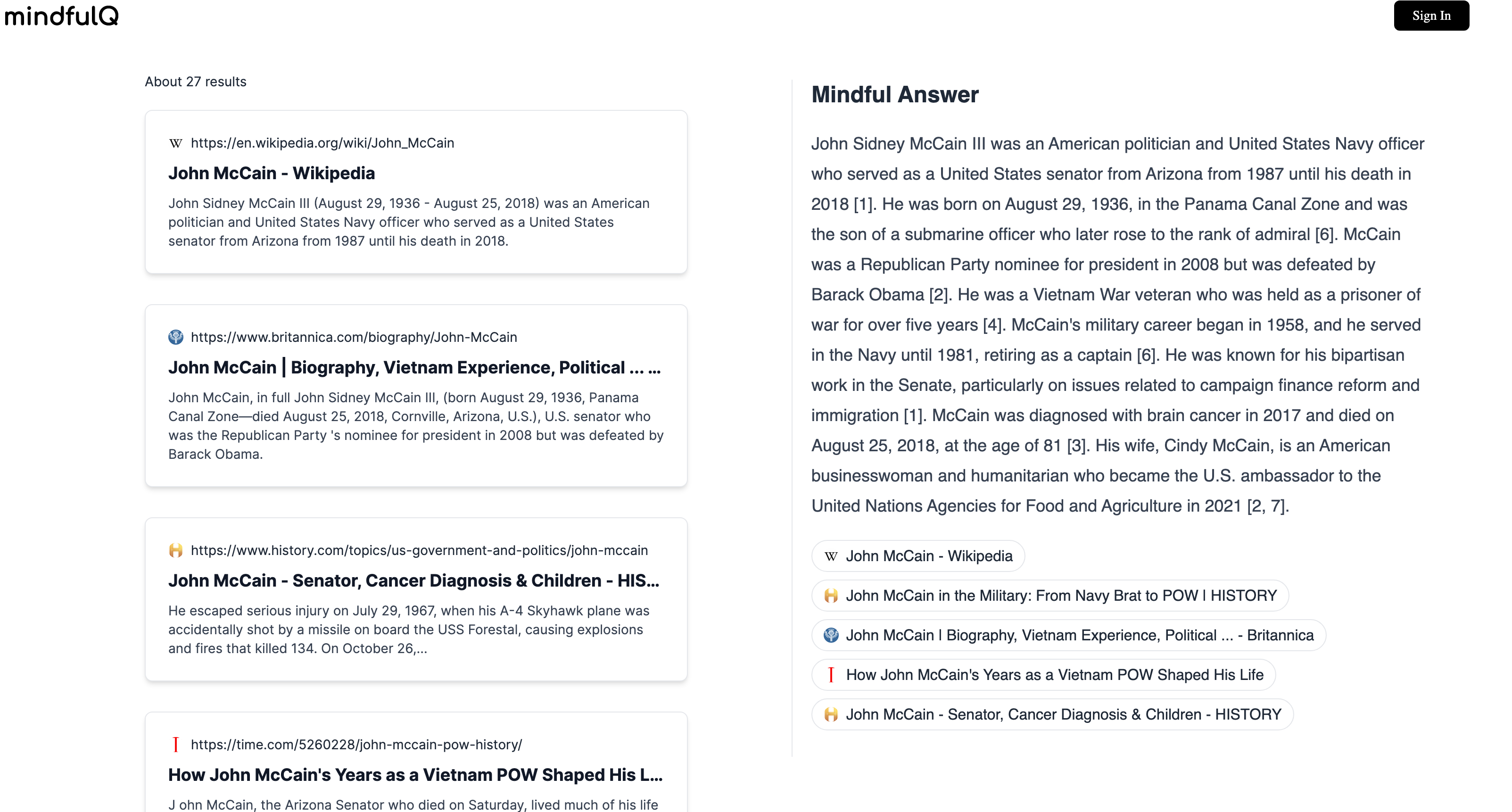
MindfulQ provides concise and relevant search results which follows the principle of "gradual complexity" for new users. Users can navigate the web in 4 ways (customized search, AI summary, content rendering, tl;dr snippets) We allow users to submit complex and potentially lengthy queries via a dynamic scaling search bar. We handle the complexity introduced by query length in our stride; using LLMs, we automatically break down the initial query into multiple well-defined sub-queries. We use the Bing and Google APIs in the backend, as well as a customized web-content segmentation pipeline to create rich, Markdown-renderable "snippets" of information.
How we built it
We used a search api to get the relevant links and once we had the relevant links we scraped the pages for each link using a web scraper. We then extracted the html elements (text) and passed it into a parser which broke the text into chunks. We embedded each of these chunks and stored them with pinecone. Upon receiving a query we do a vector search to see the K best snippets and display these snippets for each webpage when we hover over it.
Challenges we ran into
We spent a lot of time trying to find a better context-aware "chunking" solution for web readability content in HTML or Markdown as well as ways in which to segment the text. After messing around with a variety of deprecated, semi-deprecated, and supported chunking functions in langchain and other packages, we were eventually able to create a chunking pipeline from scratch. We also spent a lot of time figuring out the proper architecture and handling functions for the PineconeDB backend (and whether it was worth implementing that vs the classic llamaindex vector store which operates locally). Given the size of the vector embeddings for our text snippets, Pinecone proved to be a more storage- and compute-effective solution.
In parallel to data-processing challenges, we also went back and forth about a variety of UI/UX design considerations. As the goal of mindfulQ was to reduce the information overload on the user, we had to make sure that each information-related feature we implemented was synergistic with one another and adding value to the overall search experience.
Accomplishments that we're proud of
We are proud that we were able to put together a functional product within an extreme time crunch. Ch(Rome) wasn't built in a week, and the reinvention of user-centric search won't be either.
What we learned
We learn a lot about the power of large language models and how they can be used to make the search experience seamless and stress-free for the user. We learned more about the power of vector databases like PineconeDB and how they are extremely important in building LLM-based software solutions.
What's next for mindfulQ
Continuous improvement of our product and conducting A/B experiments to determine the usefulness of different features in our search service.
Built With
- express.js
- fastapi
- javascript
- langchain
- pinecone
- python



Log in or sign up for Devpost to join the conversation.