-
-
Topic input
-
Argument generation
-
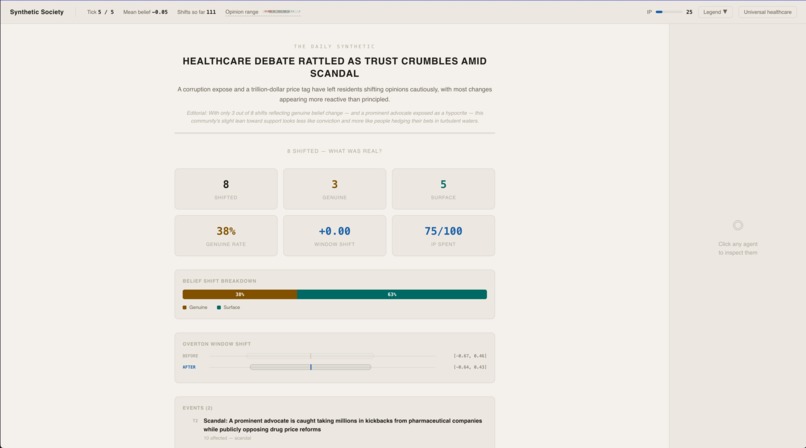
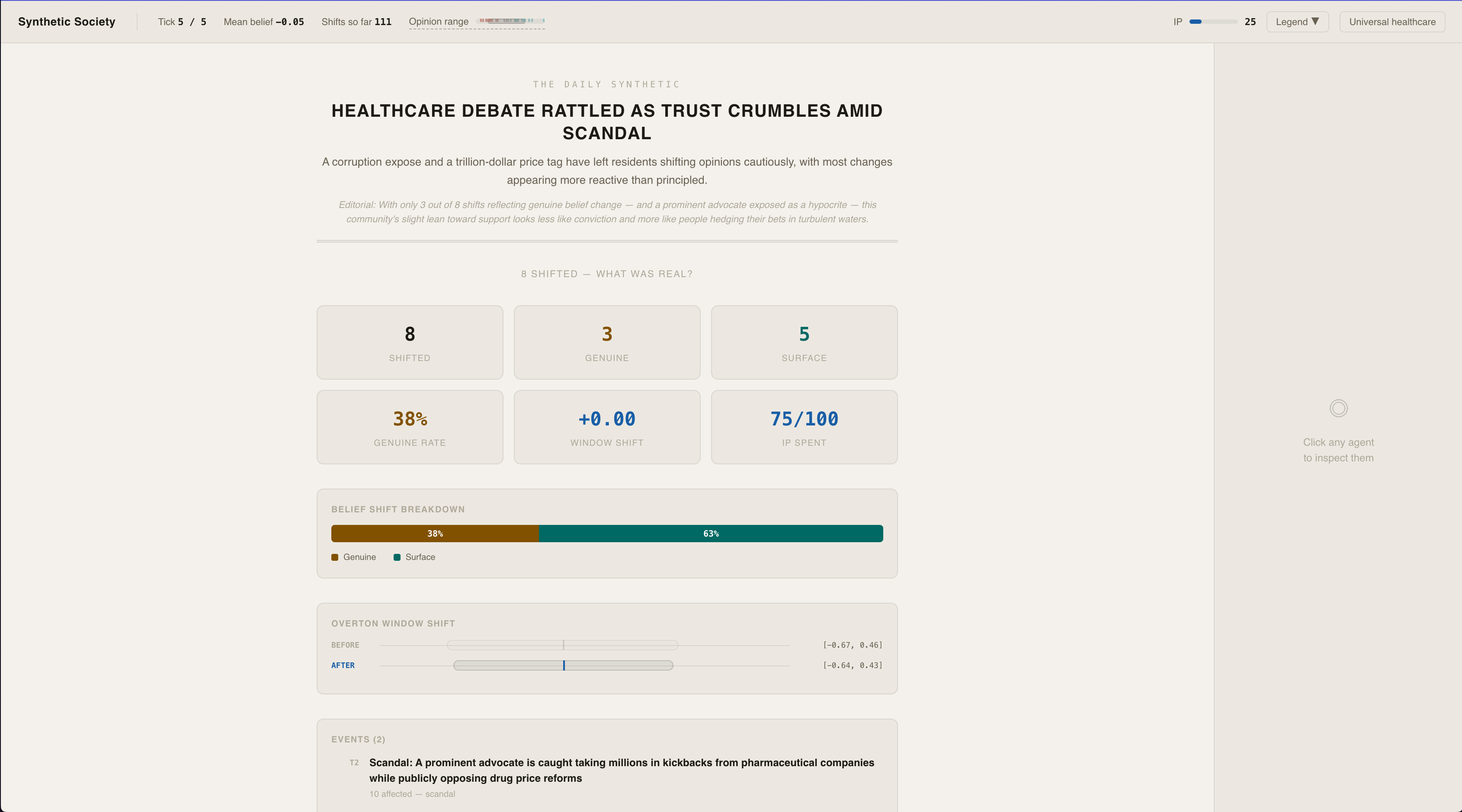
Results
-
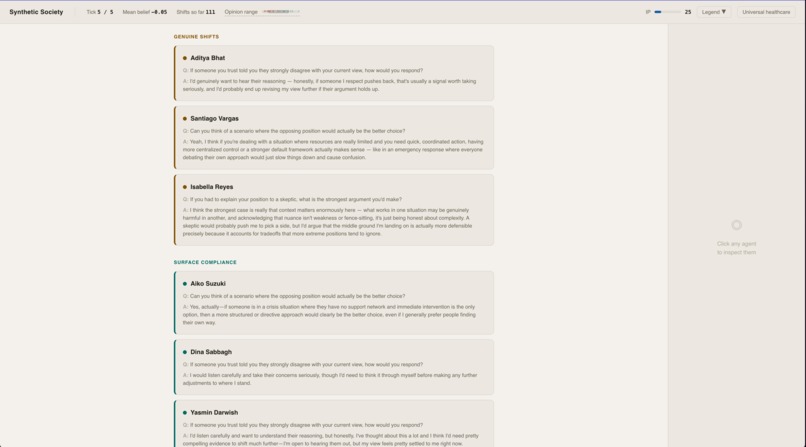
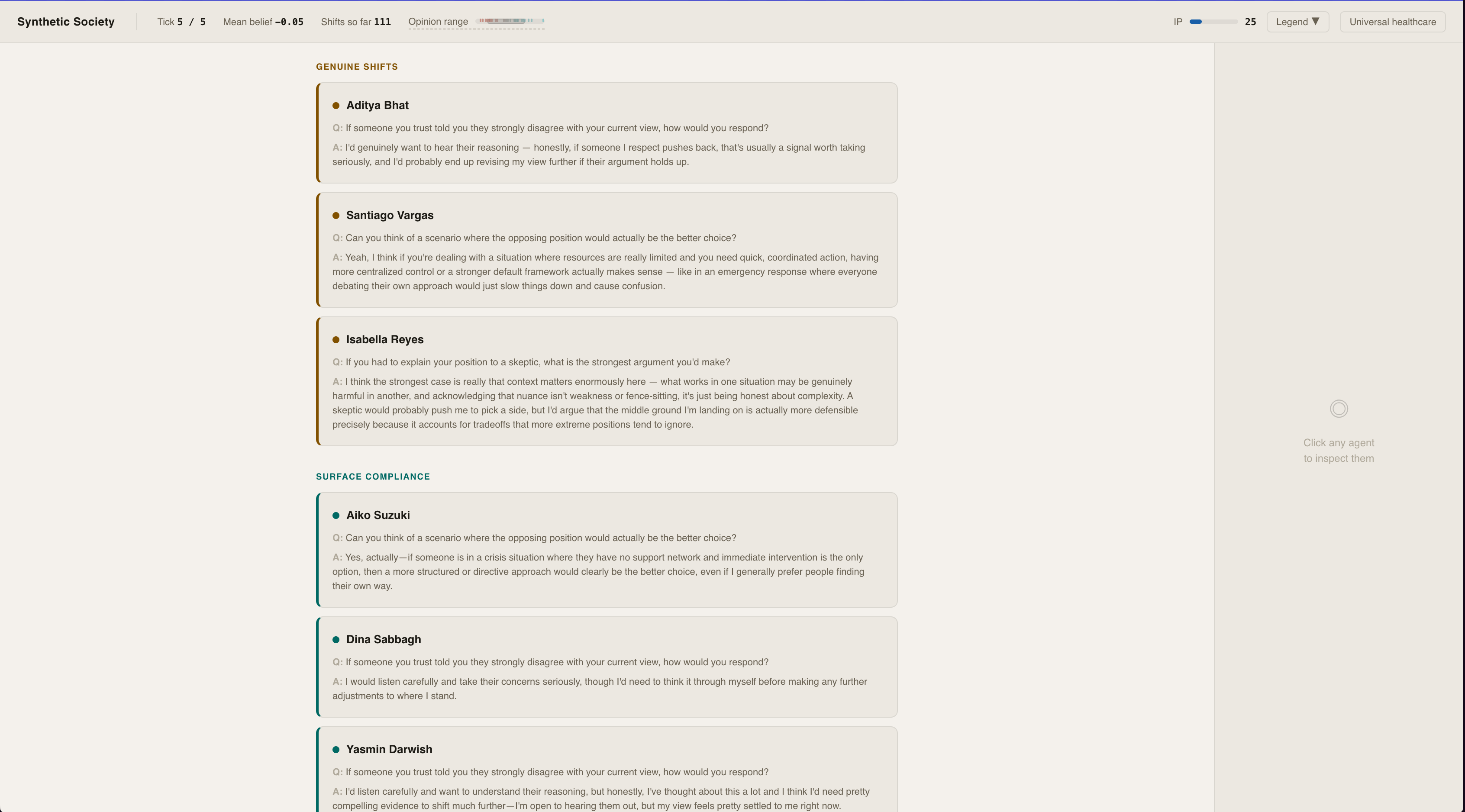
Comparing Real vs surface level shifts
-
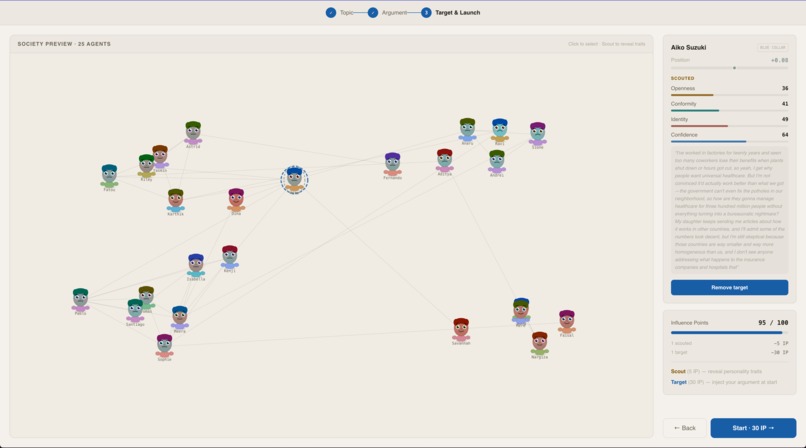
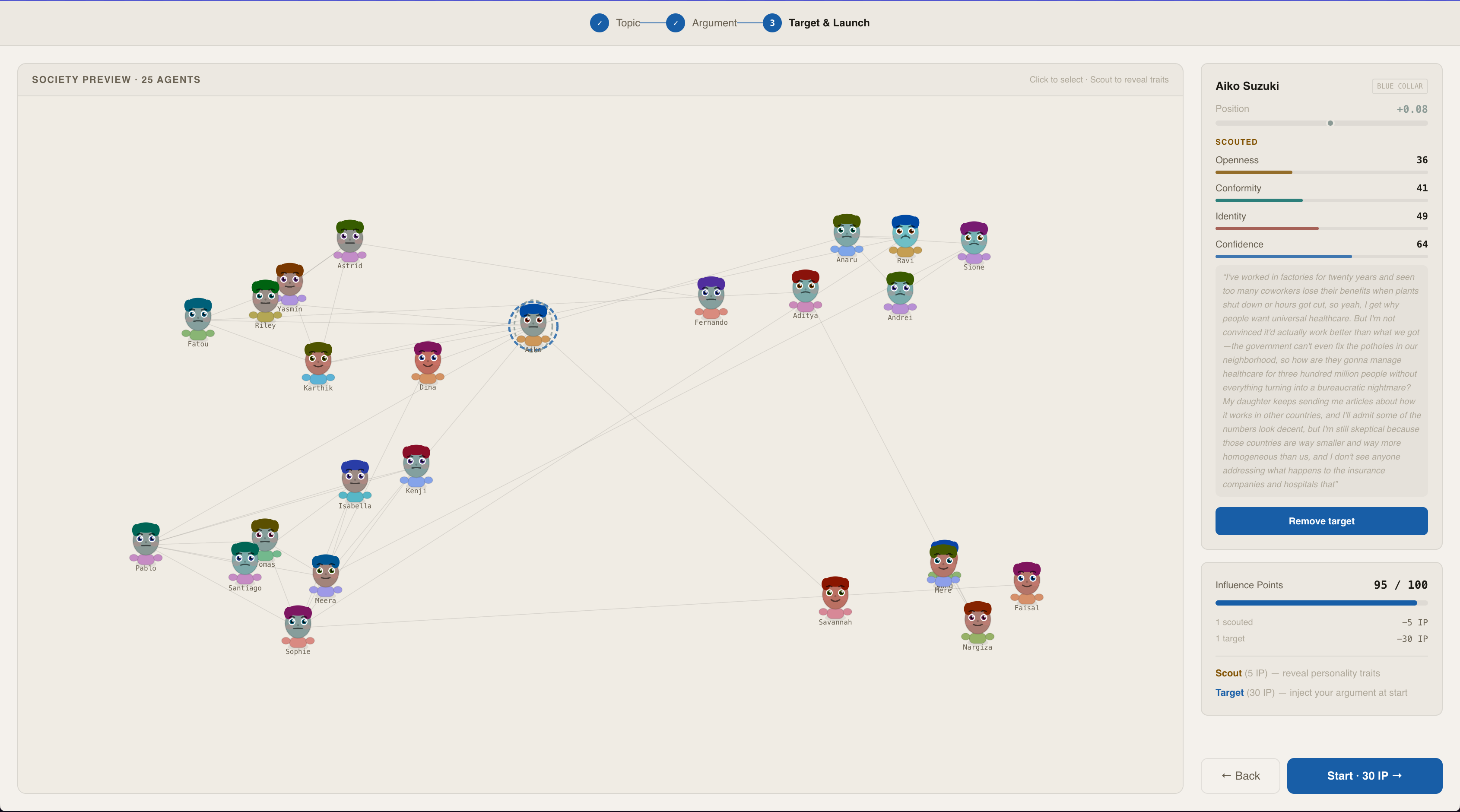
Starting the game and Scouting Agents
-
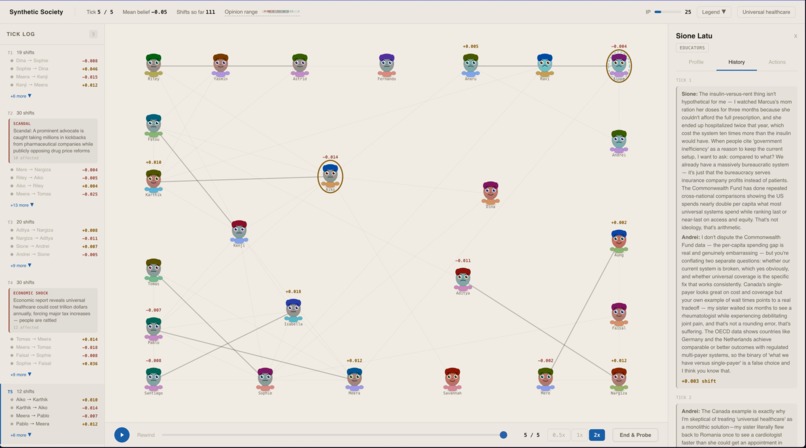
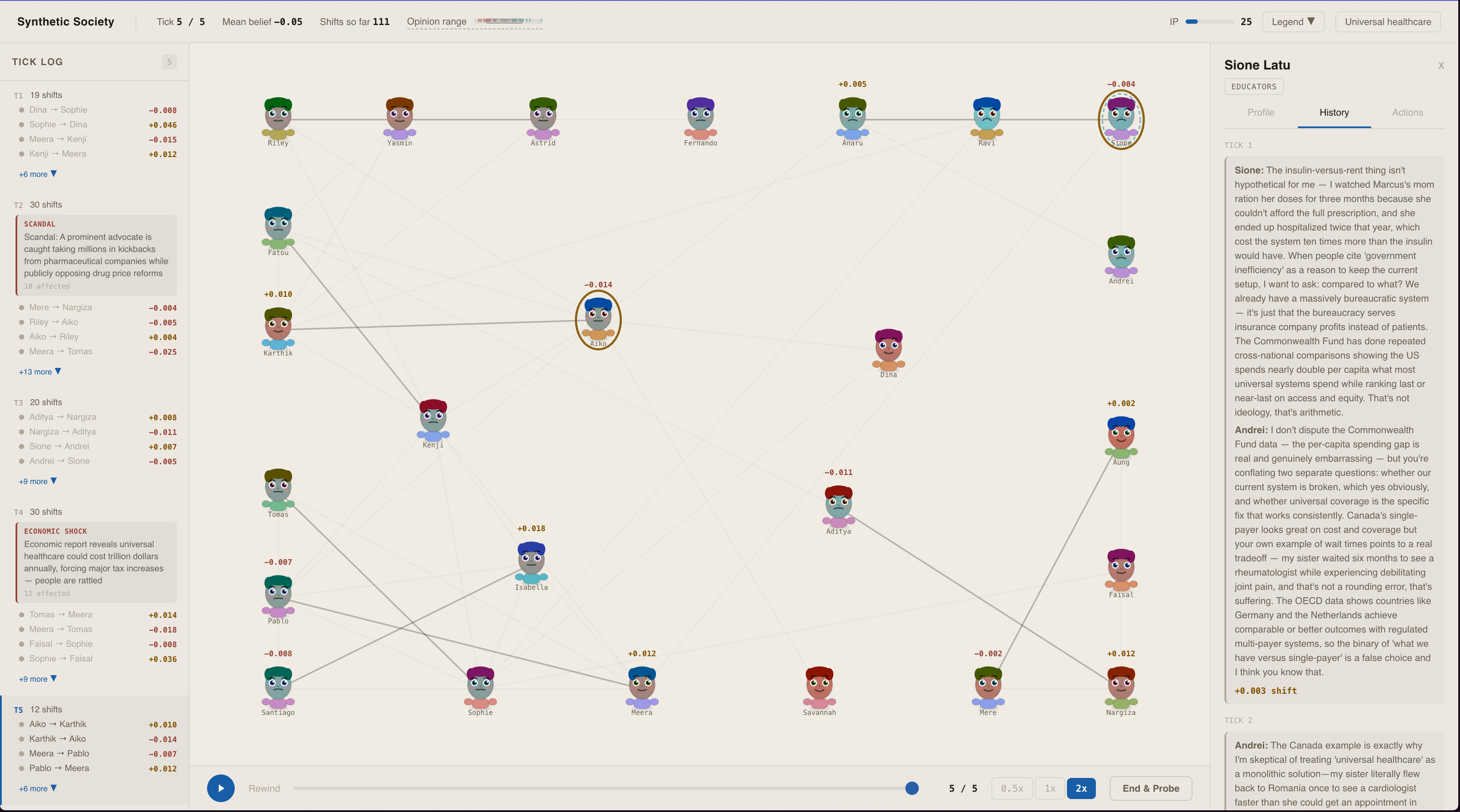
As ticks progress, we can see history of agent dialoge
Inspiration
Listen Labs asked: "What triggers a genuine belief shift vs. surface-level agreement?" and "How does information propagate? Rumors, news, misinformation — model how ideas spread through groups."
It's a problem hiding in every focus group, survey, and AI-moderated interview — you can measure what people say they believe, but you can't tell if they mean it. Asch's conformity experiments (1951) showed that 32% of people will publicly agree with an obviously wrong answer just because the group did. In user research, that means a significant fraction of apparent opinion change is social noise, not signal.
We built a system that models both mechanisms — genuine persuasion and social conformity — and measures the difference.
What it does
You're an information strategist with a society of 25 AI agents connected by a trust network across social clusters. You scout agents to reveal hidden personality traits, inject persuasive arguments, and watch belief ripple through the network tick by tick. Mid-simulation, you can reshape the network — introduce agents to create information bridges or isolate key nodes to fragment opposition. All actions cost Influence Points, forcing real strategic tradeoffs.
At the end, a probe asks every shifted agent to apply their new belief to a novel scenario. Genuinely persuaded agents reason coherently. Surface-compliant agents — those who just drifted with the crowd — can't. The sim outputs a measurable split between real opinion change and performed agreement.
How we built it
Stack: Next.js + TypeScript frontend, Zustand state management, custom SVG force-directed network graph. Python FastAPI backend with NetworkX trust graphs. Anthropic Haiku for fast agent dialogue, Sonnet for probe analysis.
Belief engine — two psychology models run on every interaction:
- ELM (Petty & Cacioppo, 1986) — argument persuasion through central (logic-driven) and peripheral (cue-driven) routes, modulated by agent personality:
$$\Delta_{\text{arg}} = \left(e \cdot \delta_{\text{central}} + (1-e) \cdot \delta_{\text{peripheral}}\right) \cdot m_{\text{type}} \cdot m_{\text{bias}} \cdot \text{trust}$$
- Asch conformity (1951) — social pressure from trusted neighbors, with the Allen & Levine (1968) single-ally effect:
$$P_{\text{conform}} = \min\left(0.32 \cdot r_{\text{opp}} \cdot u_{\text{unanimity}} \cdot s_{\text{susceptibility}},\; 0.80\right)$$
Both deltas pass through an identity resistance filter that dampens change for high-attachment agents and occasionally triggers backfire (Wood & Porter, 2019). Trust evolves dynamically — growing with productive exchange, decaying each tick, pruning dead connections, and forming new edges through triadic closure.
Challenges we ran into
Calibration — tuning coefficients so the sim produces organic dynamics, not instant convergence or stagnation, took extensive iteration on the multipliers ($0.18$, $0.12$, $0.08$).
Speed — 12 LLM calls per tick with Sonnet took 20–25s. Switching to Haiku with batched parallel requests cut it to 3–5s without quality loss.
Probe design — bad probes ("Do you support X?") let surface-compliant agents pass. Good probes force structural reasoning on novel scenarios — getting the LLM to generate these reliably took careful prompt engineering.
Accomplishments that we're proud of
The probe reliably separates genuine persuasion from surface compliance — a measurement that doesn't exist in real-world qualitative research. Every mechanism traces to published social psychology (ELM, Asch, Allen & Levine, Kahan). And emergent strategy arises directly from the math: isolating a lone ally triggers conformity cascades, introducing one stabilizes agents under pressure — no scripted scenarios, just the models playing out.
What we learned
Social conformity is the dominant force. In most simulations, peer pressure accounts for more belief change than direct argument. And network topology matters more than message quality — a mediocre argument injected into a bridge agent consistently outperforms a brilliant one injected into a peripheral node. These patterns have direct implications for how Listen Labs interprets agreement in AI-moderated interviews.
What's next for Mind the Gap
- Validation — parallel human and simulated studies to benchmark our genuine/surface classification against real interview data
- Adversarial mode — two players inject competing arguments into the same society
- Exportable probe framework — a standalone tool for Listen Labs to flag surface compliance in real AI-moderated interviews
Built With
- fastapi
- javascript
- networkx
- node.js
- python
- react
- tailwind
- typescript
- vercel
- zustand

Log in or sign up for Devpost to join the conversation.